В данной статье я расскажу о том, как найти среднеквадратическое отклонение . Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом (греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Что такое дисперсия
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
- Определите среднее (простое среднее арифметическое ряда значений).
- Затем от каждого из значений отнимите среднее и возведите полученную разность в квадрат (получили квадрат разности ).
- Следующим шагом будет вычисление среднего арифметического полученных квадратов разностей (Почему именно квадратов вы сможете узнать ниже).
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение . Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего :

Наконец, чтобы вычислить дисперсию , каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
Дисперсия мм 2 .
Таким образом, дисперсия составляет 21704 мм 2 .
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
Мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Что такое стандартное отклонение
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть значений, то:
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
Дисперсия выборки =  мм 2 .
мм 2 .
При этом стандартное отклонение по выборке равно  мм (округлено до ближайшего целого значения).
мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Примечание. Почему именно квадраты разностей?
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
 .
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
 .
.
Для второго примера получится:
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал , Сергей Валерьевич
Стандартное отклонение является одним из тех статистических терминов в корпоративном мире, которое позволяет поднять авторитет людей, сумевших удачно ввернуть его в ходе беседы или презентации, и оставляет смутное недопонимание тех, кто не знает, что это такое, но стесняется спросить. На самом деле большинство менеджеров не понимают концепцию стандартного отклонения и, если вы один из них, вам пора перестать жить во лжи. В сегодняшней статье я расскажу вам, как эта недооцененная статистическая мера позволит лучше понять данные, с которыми вы работаете.
Что измеряет стандартное отклонение?
Представьте, что вы владелец двух магазинов. И чтобы избежать потерь, важно, чтобы был четкий контроль остатков на складе. В попытке выяснить, кто из менеджеров лучше управляет запасами, вы решили проанализировать стоки последних шести недель. Средняя недельная стоимость стока обоих магазинов примерно одинакова и составляет около 32 условных единиц. На первый взгляд среднее значение стока показывает, что оба менеджера работают одинаково.

Но если внимательнее изучить деятельность второго магазина, можно убедится, что хотя среднее значение корректно, вариабельность стока очень высокая (от 10 до 58 у.е.). Таким образом, можно сделать вывод, что среднее значение не всегда правильно оценивает данные. Вот где на выручку приходит стандартное отклонение.
Стандартное отклонение показывает, как распределены значения относительно среднего в нашей . Другими словами, можно понять на сколько велик разброс величины стока от недели к неделе.
В нашем примере, мы воспользовались функцией Excel СТАНДОТКЛОН, чтобы рассчитать показатель стандартного отклонения вместе со средним.

В случае с первым менеджером, стандартное отклонение составило 2. Это говорит нам о том, что каждое значение в выборке в среднем откланяется на 2 от среднего значения. Хорошо ли это? Давайте рассмотрим вопрос под другим углом – стандартное отклонение равное 0, говорит нам о том, что каждое значение в выборке равно его среднему значению (в нашем случае, 32,2). Так, стандартное отклонение 2 ненамного отличается от 0, и указывает на то, что большинство значений находятся рядом со средним значением. Чем ближе стандартное отклонение к 0, тем надежнее среднее. Более того, стандартное отклонение близкое к 0, говорит о маленькой вариабельности данных. То есть, величина стока со стандартным отклонением 2, указывает на невероятную последовательность первого менеджера.
В случае со вторым магазином, стандартное отклонение составило 18,9. То есть стоимость стока в среднем отклоняется на величину 18,9 от среднего значения от недели к неделе. Сумасшедший разброс! Чем дальше стандартное отклонение от 0, тем менее точно среднее значение. В нашем случае, цифра 18,9 указывает на то, что среднему значению (32,8 у.е. в неделю) просто нельзя доверять. Оно также говорит нам о том, что еженедельная величина стока обладает большой вариабельностью.
Такова концепция стандартного отклонения в двух словах. Хотя оно не дает представление о других важных статистических измерениях (Мода, Медиана…), фактически стандартное отклонение играет решающую роль в большинстве статистических расчетов. Понимание принципов стандартного отклонения прольет свет на суть многих процессов вашей деятельности.
Как рассчитать стандартное отклонение?
Итак, теперь мы знаем, о чем говорит цифра стандартного отклонения. Давайте разберемся, как она считается.
Рассмотрим набор данных от 10 до 70 с шагом 10. Как видите, я уже рассчитал для них значение стандартного отклонения с помощью функции СТАНДОТКЛОН в ячейке H2 (оранжевым).

Ниже описаны шаги, которые предпринимает Excel, чтобы прийти к цифре 21,6.
Обратите внимание, что все расчеты визуализированы, для лучшего понимания. На самом деле в Excel расчет происходит мгновенно, оставляя все шаги за кулисами.
Для начала Excel находит среднее значение выборки. В нашем случае, среднее получилось равным 40, которое на следующем шаге отнимают от каждого значения выборки. Каждую полученную разницу возводят в квадрат и суммируют. У нас получилась сумма равная 2800, которую необходимо разделить на количество элементов выборки минус 1. Так как у нас 7 элементов, получается необходимо 2800 разделить на 6. Из полученного результата находим квадратный корень, это цифра будет стандартным отклонением.

Для тех, кому не совсем ясен принцип расчета стандартного отклонения с помощью визуализации, привожу математическую интерпретацию нахождения данного значения.

Функции расчета стандартного отклонения в Excel
В Excel присутствует несколько разновидностей формул стандартного отклонения. Вам достаточно набрать =СТАНДОТКЛОН и вы сами в этом убедитесь.

Стоит отметить, что функции СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г (первая и вторая функция в списке) дублируют функции СТАНДОТКЛОН и СТАНДОТКЛОНП (пятая и шестая функция в списке), соответственно, которые были оставлены для совместимости с более ранними версиями Excel.
Вообще разница в окончаниях.В и.Г функций указывают на принцип расчета стандартного отклонения выборки или генеральной совокупности. Разницу между двумя этими массивами я уже объяснял в предыдущей .
Особенностью функций СТАНДОТКЛОНА и СТАНДОТКЛОНПА (третья и четвертая функция в списке), является то, что при расчете стандартного отклонения массива в расчет принимаются логические и текстовые значения. Текстовые и истинные логические значения равняются 1, а ложные логические значения равняются 0. Мне трудно представить ситуацию, когда бы мне могли понадобится эти две функции, поэтому, думаю, что их можно игнорировать.
$X$. Для начала напомним следующее определение:
Определение 1
Генеральная совокупность -- совокупность случайно отобранных объектов данного вида, над которыми проводят наблюдения с целью получения конкретных значений случайной величины, проводимых в неизменных условиях при изучении одной случайной величины данного вида.
Определение 2
Генеральная дисперсия -- среднее арифметическое квадратов отклонений значений вариант генеральной совокупности от их среднего значения.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда генеральная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае генеральная дисперсия вычисляется по формуле:
С этим понятием также связано понятие генерального среднего квадратического отклонения.
Определение 3
Генеральное среднее квадратическое отклонение
\[{\sigma }_г=\sqrt{D_г}\]
Выборочная дисперсия
Пусть нам дана выборочная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 4
Выборочная совокупность -- часть отобранных объектов из генеральной совокупности.
Определение 5
Выборочная дисперсия -- среднее арифметическое значений вариант выборочной совокупности.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда выборочная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае выборочная дисперсия вычисляется по формуле:
С этим понятием также связано понятие выборочного среднего квадратического отклонения.
Определение 6
Выборочное среднее квадратическое отклонение -- квадратный корень из генеральной дисперсии:
\[{\sigma }_в=\sqrt{D_в}\]
Исправленная дисперсия
Для нахождения исправленной дисперсии $S^2$ необходимо умножить выборочную дисперсию на дробь $\frac{n}{n-1}$, то есть
С этим понятием также связано понятие исправленного среднего квадратического отклонения, которое находится по формуле:
В случае, когда значение вариант не являются дискретными, а представляют из себя интервалы, то в формулах для вычисления генеральной или выборочной дисперсий за значение $x_i$ принимается значение середины интервала, которому принадлежит $x_i.$
Пример задачи на нахождение дисперсии и среднего квадратического отклонения
Пример 1
Выборочная совокупность задана следующей таблицей распределения:
Рисунок 1.
Найдем для нее выборочную дисперсию, выборочное среднее квадратическое отклонение, исправленную дисперсию и исправленное среднее квадратическое отклонение.
Для решения этой задачи для начала сделаем расчетную таблицу:
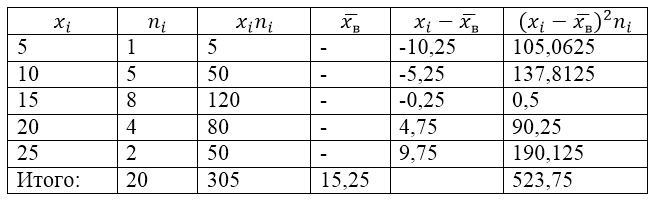
Рисунок 2.
Величина $\overline{x_в}$ (среднее выборочное) в таблице находится по формуле:
\[\overline{x_в}=\frac{\sum\limits^k_{i=1}{x_in_i}}{n}\]
\[\overline{x_в}=\frac{\sum\limits^k_{i=1}{x_in_i}}{n}=\frac{305}{20}=15,25\]
Найдем выборочную дисперсию по формуле:
Выборочное среднее квадратическое отклонение:
\[{\sigma }_в=\sqrt{D_в}\approx 5,12\]
Исправленная дисперсия:
\[{S^2=\frac{n}{n-1}D}_в=\frac{20}{19}\cdot 26,1875\approx 27,57\]
Исправленное среднее квадратическое отклонение.
Квадратный корень из дисперсии носит название среднего квадратического отклонения от средней, которое рассчитывается следующим образом:
Элементарное алгебраическое преобразование формулы среднего квадратического отклонения приводит ее к следующему виду:
Эта формула часто оказывается более удобной в практике расчетов.
Среднее квадратическое отклонение так же, как и среднее линейное отклонение, показывает, на сколько в среднем отклоняются конкретные значения признака от среднего их значения. Среднее квадратическое отклонение всегда больше среднего линейного отклонения. Между ними имеется такое соотношение:
Зная это соотношение, можно по известному показатели определить неизвестный, например, но (I рассчитать а и наоборот. Среднее квадратическое отклонение измеряет абсолютный размер колеблемости признака и выражается в тех же единицах измерения, что и значения признака (рублях, тоннах, годах и т.д.). Оно является абсолютной мерой вариации.
Для альтернативных признаков, например наличия или отсутствия высшего образования, страховки, формулы дисперсии и среднего квадратического отклонения такие:
Покажем расчет среднего квадратического отклонения по данным дискретного ряда, характеризующего распределение студентов одного из факультетов вуза по возрасту (табл. 6.2).
Таблица 6.2.

Результаты вспомогательных расчетов даны в графах 2-5 табл. 6.2.
Средний возраст студента, лет, определен по формуле средней арифметической взвешенной (графа 2):
![]()
Квадраты отклонения индивидуального возраста студента от среднего содержатся в графах 3-4, а произведения квадратов отклонений на соответствующие частоты - в графе 5.
Дисперсию возраста студентов, лет, найдем по формуле (6.2):
![]()
Тогда о = л/3,43 1,85 *ода, т.е. каждое конкретное значение возраста студента отклоняется от среднего значения на 1,85 года.
Коэффициент вариации
По своему абсолютному значению среднее квадратическое отклонение зависит не только от степени вариации признака, но и от абсолютных уровней вариантов и средней. Поэтому сравнивать средние квадратические отклонения вариационных рядов с различными средними уровнями непосредственно нельзя. Чтобы иметь возможность для такого сравнения, нужно найти удельный вес среднего отклонения (линейного или квадратического) в среднем арифметическом показателе, выраженном в процентах, т.е. рассчитать относительные показатели вариации.
Линейный коэффициент вариации вычисляют по формуле
Коэффициент вариации определяют по следующей формуле:
В коэффициентах вариации устраняется не только несопоставимость, связанная с различными единицами измерения изучаемого признака, но и несопоставимость, возникающая вследствие различий в величине средних арифметических. Кроме того, показатели вариации дают характеристику однородности совокупности. Совокупность считается однородной, если коэффициент вариации не превышает 33%.
По данным табл. 6.2 и полученным выше результатам расчетов определим коэффициент вариации, %, по формуле (6.3):
![]()
Если коэффициент вариации превышает 33%, то это свидетельствует о неоднородности изучаемой совокупности. Полученное в пашем случае значение говорит о том, что совокупность студентов по возрасту однородна по своему составу. Таким образом, важная функция обобщающих показателей вариации - оценка надежности средних. Чем меньше с1, а2 и V, тем однороднее полученная совокупность явлений и надежнее полученная средняя. Согласно рассматриваемому математической статистикой "правилу трех сигм" в нормально распределенных или близких к ним рядах отклонения от средней арифметической, не превосходящие ±3ст, встречаются в 997 случаях из 1000. Таким образом, зная х и а, можно получить общее первоначальное представление о вариационном ряде. Если, например, средняя заработная плата работника по фирме составила 25 000 руб., а а равна 100 руб., то с вероятностью, близкой к достоверности, можно утверждать, что заработная плата работников фирмы колеблется в пределах (25 000 ± ± 3 х 100) т.е. от 24 700 до 25 300 руб.
Х i - случайные (текущие) величины;
X̅ – среднее значение случайных величин по выборке, рассчитывается по формуле:

Итак, дисперсия - это средний квадрат отклонений . То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат , складывается и затем делится на количество значений в данной совокупности.
Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, мы просто рассчитываем среднюю арифметическую.
Разгадка магического слова «дисперсия» заключается всего в этих трех словах: средний – квадрат – отклонений.
Среднее квадратичное отклонение (СКО)
Извлекая из дисперсии квадратный корень, получаем, так называемое «среднеквадратичное отклонение». Встречаются названия «стандартное отклонение» или «сигма» (от названия греческой буквыσ .). Формула среднего квадратичного отклонения имеет вид:
Итак, дисперсия – это сигма в квадрате, или – среднее квадратичное отклонение в квадрате.
Среднеквадратичное отклонение, очевидно, также характеризует меру рассеивания данных, но теперь (в отличие от дисперсии) его можно сравнивать с исходными данными, так как единицы измерения у них одинаковые (это явствует из формулы расчета). Размах вариации – это разница между крайними значениями. Среднеквадратичное отклонение, как мера неопределенности, также участвует во многих статистических расчетах. С ее помощью устанавливают степень точности различных оценок и прогнозов. Если вариация очень большая, то стандартное отклонение тоже получится большим, следовательно, и прогноз будет неточным, что выразится, к примеру, в очень широких доверительных интервалах.
Поэтому в методах статистической обработки данных в оценках объектов недвижимости в зависимости от необходимой точности поставленной задачи используют правило двух или трех сигм.
Для сравнения правила двух сигм и правила трех сигм используем формулу Лапласа:
![]() Ф - Ф ,
Ф - Ф ,
где Ф(x) – функция Лапласа;
Минимальное значение
β = максимальное значение
s = значение сигмы (среднее квадратичное отклонение)
a = среднее значение
В этом случае используется частный вид формулы Лапласа когда границы α и β значений случайной величины X равно отстоят от центра распределения a = M(X) на некоторую величину d: a = a-d, b = a+d.
 Или
Или
  (1)
Формула (1) определяет вероятность заданного отклонения d случайной величины X с нормальным законом распределения от ее математического ожидания М(X) = a.
Если в формуле (1) принять последовательно d = 2s и d = 3s, то получим:
(2),
(3). (1)
Формула (1) определяет вероятность заданного отклонения d случайной величины X с нормальным законом распределения от ее математического ожидания М(X) = a.
Если в формуле (1) принять последовательно d = 2s и d = 3s, то получим:
(2),
(3).
|
Правило двух сигм
Почти достоверно (с доверительной вероятностью 0,954) можно утверждать, что все значения случайной величины X с нормальным законом распределения отклоняются от ее математического ожидания M(X) = a на величину, не большую 2s (двух средних квадратических отклонений). Доверительной вероятностью (Pд) называют вероятность событий, которые условно принимаются за достоверные (их вероятность близка к 1).
Проиллюстрируем правило двух сигм геометрически. На рис. 6 изображена кривая Гаусса с центром распределения а. Площадь, ограниченная всей кривой и осью Оx, равна 1 (100%), а площадь криволинейной трапеции между абсциссами а–2s и а+2s, согласно правилу двух сигм, равна 0,954 (95,4% от всей площади). Площадь заштрихованных участков равна 1-0,954 = 0,046 (»5% от всей площади). Эти участки называют критической областью значений случайной величины. Значения случайной величины, попадающие в критическую область, маловероятны и на практике условно принимаются за невозможные.

Вероятность условно невозможных значений называют уровнем значимости случайной величины. Уровень значимости связан с доверительной вероятностью формулой:
где q – уровень значимости, выраженный в процентах.
Правило трех сигм
При решении вопросов, требующих большей надежности, когда доверительную вероятность (Pд) принимают равной 0,997 (точнее - 0,9973), вместо правила двух сигм, согласно формуле (3), используют правило трех сигм.
Согласно правилу трех сигм при доверительной вероятности 0,9973 критической областью будет область значений признака вне интервала (а-3s, а+3s). Уровень значимости составляет 0,27%.
Другими словами, вероятность того, что абсолютная величина отклонения превысит утроенное среднее квадратическое отклонение, очень мала, а именно равна 0,0027=1-0,9973. Это означает, что лишь в 0,27% случаев так может произойти. Такие события, исходя из принципа невозможности маловероятных событий, можно считать практически невозможными. Т.е. выборка высокоточная.
В этом и состоит сущность правила трех сигм:
Если случайная величина распределена нормально, то абсолютная величина ее отклонения от математического ожидания не превосходит утроенного среднего квадратического отклонения (СКО).
На практике правило трех сигм применяют так: если распределение изучаемой случайной величины неизвестно, но условие, указанное в приведенном правиле, выполняется, то есть основание предполагать, что изучаемая величина распределена нормально; в противном случае она не распределена нормально.
Уровень значимости принимают в зависимости от дозволенной степени риска и поставленной задачи. Для оценки недвижимости обычно принимается менее точная выборка, следуя правилу двух сигм.

