Свіжеперекладений фундаментальний підручник С.Хайкіна (перекладено друге американське видання 1999 р.) цілком претендує на звання події 2006 року в російській літературі з нейроінформатики. Але слід зазначити, що переклад хоч і виконаний без явних ляпів, але підрядкові примітки-коментарі перекладачів не завадили б для уточнення термінології (оскільки те саме може називатися в нейроінформатиці, статистиці та ідентифікації систем різними словами, то потрібно або зводити терміни до однієї області, або давати списки синонімів - не все ж читачі матимуть широкий кругозір). Коментарі могли б відобразити і прогрес у галузі штучних нейронних мереж, що відбувся з моменту опублікування англомовного оригіналу. Я сподіваюся, що книга матиме попит і при додрукуванні тиражу зміни будуть внесені. Тим більше, що є значна кількість друкарських помилок у математичних формулах. Виправленням друкарських помилок головним чином і присвячена дана сторінка. Але треба зазначити, що я не гарантую повноту наведеного тут списку неточностей - книгу читав "по діагоналі", уривками та при різного ступеняуважності, тому щось міг пропустити (або помилитися сам).
Глава 1
- С.32 другий абзац. Тільки тут слово "продуктивність" можна розуміти як швидкість роботи, потужність обчислювача. Далі у книзі у "продуктивності" (performance) буде сенсом точність, якість роботи нейромережі (наприклад, на с.73 у другому абзаці знизу).
- С.35 п.7. "VLSI Implementability" краще перекласти не як "масштабованість", а як "ефективна реалізованість на НВІС - надвеликих інтегральних схемах".
- С.39 стор.7. Слово "spike"-"викид, імпульс" у російськомовній нейронауці досить часто і звично просто транслітерується як "спайк".
- С.49 назва параграфа. Напевно, найкращим був би термін "орієнтований граф" замість "направлений граф".
- C.76 Третій абзац. Замість посилання напевно має бути посилання на книгу Ешбі.
- С.99 висновок 1. Потрібно додати ще й випадок одночасного задоволення цих умов і зі знаком "
- С.105 абзац 2. Потрібно вставити слово "видимі" перед (visible).
Розділ 2
- С.94 виноска 2. Посилання швидше за все неправильна, т.к. не книга і за назвою особливо не підходить.
- С.122 останній абзац. Посміявся над фразою "деформація структури нейронів": поки зовнішню подію струс мозку не влаштує, людина цю подію і не запам'ятає. Швидше за все стверджувалося, що пам'ять реалізується лише відключенням синаптичних входів (закінчень) від щупалець дендритів або перемиканням з одного щупальця на інше (терміни з Мал.1.2 на с.40, оскільки цей малюнок добре підходить для ілюстрації). Тобто. мізки наші з вами живі та ворушаться.
- С.129 формула (2.39). Замість хповинно бути х.
- C.129 формули (2.40), (2.41), (2.44). Верхній індекс має бути qзамість m.
- C.137 перший абзац та формула (2.61). Е має бути курсивом. І у формулах (2.64), (2.65), (2.67), (2.68) на с.138 теж.
- С.142 формула (142). Після першої стрілки додати 0.
- C.142 останній абзац. Перед останнім словомвставити "мінус".
- C.147 перший абзац. | L|=l. Тобто. змінна lу правій частині виразу має бути дано курсивом (оскільки варіант у книзі плутає її з одиницею).
- С.151 формула (2.90). У верхній рядок після фігурної дужки вставити F.
- C.151 формула (2.91). Вставити " при " перед N.
- C.160 останній абзац у виносці. "при невеликій кількості" замінити на "при великій кількості".
Розділ 3
- С.173 Мал.3.1. Змінні треба дати курсивом відповідно до прийнятих у книзі позначеннями, т.к. ці змінні скалярні.
- С.176 формули (3.5), (3.7). Повинно бути w* замість w* .
- C.176 останній рядок. Швидше за все, треба посилатися на , хоча у зазначеній це питання теж може бути розглянуто.
- С.179 виноски. Має бути "похідна f(w) по w"
- С.180 останній рядок перед виноскою. Замість можливо краще взяти , а посилання може бути неправильним.
- С.184 проміжний вираз у верхньому рядку формули (3.30). Замість x(n) повинно бути x(i)
- С.200 абзац після формули (3.59). Посміявся з "нерівності Гучі-Шварца". Має бути всім відома за ВНЗ курсу вишки нерівність Коші-Шварца (Cauchy).
- С.204 перший абзац розділу 3.10 - для перетворення байєсовського класифікатора на лінійний роздільник за умов гаусового середовища. Мається на увазі умова однаковості матриць коваріації обох класів (буде введено в розділі на с.207), але у мене при фразі "гаусове середовище" зазвичай згадується узагальнена ситуація двох нормальних розподілів з довільними матрицями коваріації, коли байєс може і не вироджуватися в лінійний роздільник , а давати квадратичну поверхню, що розділяє.
- С.206 формула (3.77). Далі замість зазначеної у формулі λ кілька разів у тексті та на рис.3.10 буде надруковано Λ.
- С.216 Завдання 3.11. Те, що дано у верхній межі суми, має бути перенесено під знак суми (а мінус можна винести і перед сумою). Також в абзаці після цієї формули замість w T xповинно бути w T x
Розділ 4
Мій коментар до розділу: кошмар, новачок у нейронних мережах та методах оптимізації навіть після неодноразового прочитання глави та неодноразових проб (цілеспрямовано або методом тику) навряд чи правильно зможе запрограмувати навчання нейронної мережі методом зворотного поширення помилки. за Крайній мірі, при розгляді лише студентів провінційних технічних ВНЗ готовий сперечатися про це із досить високими ставками. Переказ перемішав у купу і необхідні, і малопотрібні речі, не розставивши акцентів і переускладнивши виклад (ідучи підходом "все чи нічого" замість покрокового доповнення процедур). Плюс багато емпірики. Чому б не викласти просто методику обчислення градієнта складної функції (нейросеть плюс цільова функція над її виходом і, при необхідності, над властивостями нейромережі), потім, як у Розділі 6, надіслати читачів до методів градієнтної оптимізації без обмежень (у Розділі 6 посилання йде до методів квадратичного програмування), і викласти кілька історичних прикладів правильних і неправильних підходів до використання обчислюваного мережею градієнта з погляду теорії градієнтної оптимізації та максимізації швидкості збіжності (швидкості навчання).
Що хотілося б бачити у розділі (чи книзі) додатково. По-перше, відмінні від методу найменших квадратів цільові функції, особливо навчання мережі-класифікатора (наприклад, крос-энтропийная функція). По-друге, більш чітке виділення можливості мати що складається з кількох доданків цільову функцію: з прикладу регуляризації по Тихонову через явну мінімізацію крім власне значення помилки ще й скалярного квадрата градієнта вихідних сигналів мережі за вагами синапсів (спільні роботи ЛеКуна і Дракера 1991-9 або на прикладі методу Flat minina search Хохрейтера та Шмідхубера, або на прикладі методу CLearning очищення вхідних сигналів мережі Андреаса Вайгенда із співавторами. По-третє, більш детальне розписування можливості обчислення других похідних у мережі (зазначені роботи ЛеКуна та Дракера, методи, перераховані в огляді). По-четверте, більш детальний опис методів обчислення інформативності-корисності різних елементів і сигналів у мережі (тобто визначення інформативності входів, можливості редукції не тільки синапсів описаними в книзі методами, але й редукції цілих нейронів, та й для редукції синапсів теж є купа інших методів). У п'ятих - явна вказівка (адже читачі не зрозуміють самі) на можливість вважати градієнт і за вхідними сигналами мережі (для вирішення обернених завданьна нейромережах, навчених рішенню прямої задачі, для викладу методу CLearning). Плюс для цієї та інших розділів, де постає завдання навчання з учителем, детальніше розписати ідею кривих навчання для нейронних мереж.
Розділ 5
- С.357 після формули (5.23). Далі на кількох сторінках Eможе бути дана курсивом або жирним шрифтом, причому зміна форми запису досить безсистемна. Правильніше - курсивом, для E(F), E s (F), E c (F), E(F,h).
- С.361 формула (5.31). Замість нижнього індексу Hповинно бути H .
- С.363 останній абзац. "...лінійною комбінацією..." замість "...лінійною суперпозицією...".
- С.364 формула (5.43). Забрати 1/λ.
- С.367 формула (5.59). σ замість δ.
- С.369 після формули (5.65). Знову має бути " лінійна комбінаціязамість "лінійної суперпозиції".
- С.373 третій рядок формули (5.74). Вставити дужку, що відкриває, перед другим t i .
- С.382 формула (5.112). У нижній межі суми дописати "не одно k".
- С.390 назва розділу 5.12. У російськомовній науці зазвичай замість "регресії ядра" використовуються терміни "непараметрична регресія" (саме так називається цей метод статистики російською) або "ядерна регресія" (якщо переводити "в лоб").
- С.393 формула (5.135). Вставити " ... всім ... " , як і (5.139) на след.стр.
- С.399 "середній" абзац. "... Алгоритм кластеризації по k-середнім…", далі слово "середнім" пропускатися більше не буде.
- С.403 ненумерований перелік. Надто вже глобальні та однозначні висновки роблять автори з одного експерименту, хоча багато в чому згоден.
- С.404 – перший пункт списку. Не зрозумів, особливо у частині "впливу на вхідні параметри". Швидше, ніж більше значенняλ, тим менший вплив даних взагалі на підсумкові властивості моделі.
- С.408 перший абзац. Сумнівне посилання на, можливо підійде.
- С.408 рядок 6 абзацу 2. "базової функції" замість "фундаментальної функції".
Розділ 6
- С.431 остання пропозиція перед розділом 6.4. Не зрозумів "кращі" пропонованого вибору через середнє за вибіркою (та й начебто при цьому отримати правильне b 0буде не можна).
- С.434 формула (6.35). Індексу iу останнього xбути не повинно.
- С.435 ненумеровані формули у теоремі Мерсера. Замість ψ має бути φ.
- С.444 виноски. Прізвище Huber російською мовою раніше перекладалося як Х'юбер, а не Габер (наприклад, переклад його книги за часів СРСР: Х'юбер, "Робастність у статистиці").
Розділ 7 (не повністю)
- С.459 третій рядок зверху. Розшифрування терміна "слабкий алгоритм навчання" дано на с.467 у другому абзаці зверху.
- С.459 ненумеровані підпункти у п.2. Термін "шлюзова мережа" як переклад терміна "gating network" занадто вже кострубатий, але іншого (і при цьому хорошого) варіанта російською поки немає. Напевно, краще було б використовувати термін "зважуюча мережа", універсальний як для випадку жорсткого перемикання (коефіцієнти-множники 0 або 1 для керованого сигналу), так і для м'якого керування коефіцієнтом загасання (множниками діапазону).
- С.463 п.2. Частку "не" прибираємо з цієї пропозиції - дисперсія ансамблю менша за дисперсію окремих функцій.
- С.471 перші рядки. "Продуктивність" (нагадуємо, що "продуктивність-performance" тут розуміється не в сенсі швидкості, а в сенсі точності рішення та узагальнення - див. наш коментар до с.32) вихідного методу посилення теж залежить від розподілів, що формуються в процесі його роботи другого та наступних експертів.
- С.472 таблиця 7.2 останній рядок. Повинно бути F fin ( x)=…
Бібліографія
- Купу раз слова application, approximation, approach, applied, support, mapping, applicability, upper написані з одного p.
- . Правильне написанняпрізвища одного з авторів можна побачити у .
- . Правильне прізвище Мюллера - як у його однофамільця.
- . Перший автор - B u ntine.
- . Вийшло в тому ж NIPS, що і .
- . Останній із авторів правильно названий у .
- . Потрібно weak замість week.
- . Останній автор правильно названий у .
- . Перший - Landa u.
- . Це розділ у книзі.
- . Sch ö lkopf.
- . У назві - "… bia s term". У дублі написано правильно.
- . У назві - "…gamm on".
- . Повторення.

У ми описали самі прості властивостіформальних нейронів. Проговорили про те, що граничний суматор точніше відтворює природу одиничного спайка, а лінійний суматор дозволяє змоделювати відповідь нейрона, що складається з серії імпульсів. Показали, що значення виході лінійного суматора можна зіставити з частотою викликаних спайків реального нейрона. Тепер ми подивимося на основні властивості, які мають такі формальні нейрони.
Фільтр Хебба
Далі ми часто звертатимемося до нейромережевих моделей. У принципі, практично всі основні концепції теорії нейронних мереж мають пряме відношення до будови реального мозку. Людина, стикаючись з певними завданнями, вигадала безліч цікавих нейромережевих конструкцій. Еволюція, перебираючи всі можливі нейронні механізми, відібрала все, що виявилося для неї корисним. Не варто дивуватися, що для багатьох моделей, придуманих людиною, можна знайти чіткі біологічні прототипи. Оскільки наша розповідь не ставить за мету хоч скільки-небудь детальний виклад теорії нейронних мереж, ми торкнемося тільки найбільш загальних моментів, необхідні опису основних ідей. Для глибшого розуміння я рекомендую звернутися до спеціальної літератури. На мене найкращий підручник з нейронних мереж - це Саймон Хайкін «Нейронні мережі. Повний курс» (Хайкін, 2006).В основі багатьох нейромережевих моделей лежить добре відоме правило навчання Хебба. Воно було запропоновано фізіологом Дональдом Хеббом 1949 року (Hebb, 1949). У трохи вільному трактуванні воно має дуже простий зміст: зв'язки нейронів, що активуються спільно, повинні посилюватися, зв'язки нейронів, які спрацьовують незалежно, повинні слабшати.
Стан виходу лінійного суматора можна записати:
Якщо ми ініціюємо початкові значення ваг малими величинами і подаватимемо на вхід різні образи, то ніщо не заважає нам спробувати навчати цей нейрон за правилом Хебба:
Де n– дискретний крок у часі, – параметр швидкості навчання.
Такою процедурою ми збільшуємо ваги тих входів, на які подається сигнал, але робимо це тим сильніше, чим активніша реакція самого нейрона, що навчається. Якщо немає реакції, не відбувається і навчання.
Щоправда, такі ваги необмежено зростатимуть, тому для стабілізації можна застосувати нормування. Наприклад, поділити на довжину вектора, отриманого з "нових" синаптичних ваг.
За такого навчання відбувається перерозподіл ваг між синапсами. Зрозуміти суть перерозподілу легше, якщо стежити за зміною ваг у два прийоми. Спочатку, коли нейрон активний, ті синапси, куди надходить сигнал, отримують добавку. Вага синапсів без сигналу залишається без змін. Потім загальне нормування зменшує ваги всіх синапсів. Але при цьому синапси без сигналів втрачають у порівнянні зі своїм попереднім значенням, а синапси із сигналами перерозподіляють між собою ці втрати.
Правило Хебба є не що інше, як реалізація методу градієнтного спуску поверхнею помилки. По суті, ми змушуємо нейрон підлаштуватися під сигнали, що подаються, зрушуючи кожен раз його ваги в бік, протилежну помилці, тобто в напрямку антиградієнта. Щоб градієнтний спуск привів нас до локального екстремуму, не проскочивши його, швидкість спуску має бути досить низька. Що у Хеббовском навчанні враховується трохи параметра .
Трохи параметра швидкості навчання дозволяє переписати попередню формулу у вигляді ряду за :
Якщо відкинути доданки другого порядку і вище, то вийде правило навчання Ойа (Oja, 1982):
Позитивна добавка відповідає за хеббівське навчання, а негативна за загальну стабільність. Запис у такому вигляді дозволяє відчути, як таке навчання можна реалізувати в аналоговому середовищі без використання обчислень, оперуючи лише позитивними та негативними зв'язками.
Так ось, таке вкрай просте навчання має дивовижну властивість. Якщо ми поступово зменшуватимемо швидкість навчання, то ваги синапсів нейрона, що навчається, зійдуться до таких значень, що його вихід починає відповідати першій головній компоненті, яка вийшла б, якби ми застосували до даних відповідні процедури аналізу головних компонентів. Така конструкція називається фільтром Хебба.
Наприклад, подамо на вхід нейрона піксельну картинку, тобто зіставимо кожному синапс нейрона одну точку зображення. Подаватимемо на вхід нейрона всього два образи – зображення вертикальних та горизонтальних ліній, що проходять через центр. Один крок навчання – одне зображення, одна лінія або горизонтальна, або вертикальна. Якщо ці зображення усереднити, то вийде хрест. Але результат навчання не буде схожим на усереднення. Це буде одна з ліній. Та, яка частіше зустрічатиметься в зображеннях, що подаються. Нейрон виділить не усереднення чи перетин, а ті точки, що найчастіше зустрічаються разом. Якщо образи будуть складнішими, то результат може бути настільки наочний. Але це завжди буде головна компонента.
Навчання нейрона веде до того що, що у його вагах виділяється (фільтрується) певний образ. Коли подається новий сигнал, то чим точніше збіг сигналу та налаштування ваги, тим вище відгук нейрона. Навчений нейрон можна назвати нейроном-детектором. При цьому образ, який описується його вагами, називається характерним стимулом.
Головні компоненти
Сама ідея методу головних компонентів проста і геніальна. Припустимо, що ми маємо послідовність подій. Кожне з них описуємо через його вплив на сенсори, якими ми сприймаємо світ. Припустимо, що ми маємо сенсорів, що описують ознак . Всі події для нас описуються векторами розмірності. Кожен компонент такого вектора вказують на значення відповідної ознаки. Усі разом вони утворюють випадкову величину X . Ці події ми можемо зобразити у вигляді точок в мірному просторі, де осями виступатимуть спостерігаються нами ознаки.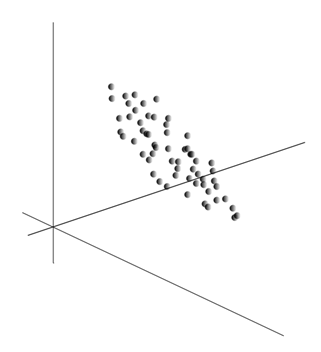
Усереднення значень дає математичне очікування випадкової величини X, що позначається, як E( X). Якщо ми відцентруємо дані так, щоб E( X)=0, то хмара точок буде сконцентрована навколо початку координат.
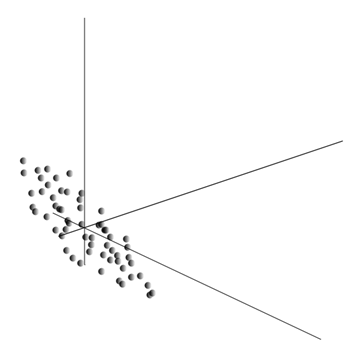
Ця хмара може виявитися витягнутою у будь-якому напрямку. Перепробувавши все можливі напрямки, ми можемо знайти таке, уздовж якого дисперсія даних буде максимальною.
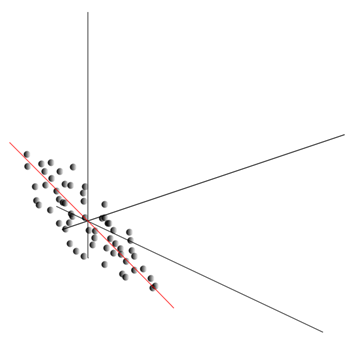
Так ось, такий напрямок відповідає першій головній компоненті. Сама головна компонента визначається одиничним вектором, що виходить із початку координат і збігається з цим напрямком.
Далі ми можемо знайти інший напрямок, перпендикулярний першій компоненті, такий, щоб уздовж нього дисперсія також була максимальною серед усіх перпендикулярних напрямків. Знайшовши його, ми матимемо другу компоненту. Потім ми можемо продовжити пошук, задавшись умовою, що треба шукати серед напрямків, перпендикулярних вже знайденим компонентам. Якщо вихідні координати були лінійно незалежні, то ми зможемо вчинити раз, доки закінчиться розмірність простору. Таким чином, ми отримаємо взаємоортогональних компонентів, упорядкованих по тому, який відсоток дисперсії даних вони пояснюють.
Природно, отримані основні компоненти відбивають внутрішні закономірності наших даних. Але є простіші характеристики, також описують суть існуючих закономірностей.
Припустимо, що всього ми маємо n подій. Кожна подія описується вектором. Компоненти цього вектора:
Для кожної ознаки можна записати, як він проявляв себе у кожній з подій:
Для будь-яких двох ознак, на яких будується опис, можна вважати величину, що показує ступінь їхнього спільного прояву. Ця величина називається коваріацією: 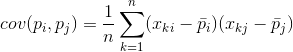
Вона показує, наскільки відхилення від середнього значення однієї з ознак збігаються за проявом з аналогічними відхиленнями іншої ознаки. Якщо середні значення ознак дорівнюють нулю, то коваріація набуває вигляду: 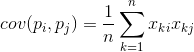
Якщо скоригувати коваріацію на середньоквадратичні відхилення, властиві ознакам, ми отримаємо лінійний коефіцієнт кореляції, званий ще коефіцієнтом кореляції Пірсона: ![]()
Коефіцієнт кореляції має чудову властивість. Він приймає значення від -1 до 1. Причому 1 означає пряму пропорційність двох величин, а -1 говорить про їхню зворотну лінійну залежність.
З усіх попарних підступів ознак можна скласти підступну матрицю, яка, як неважко переконатися, є математичне очікування твору: ![]()
Так ось виявляється, що для основних компонентів справедливо:
Тобто головні компоненти, чи, як їх називають, чинники є власними векторами кореляційної матриці . Їм відповідають власні числа. При цьому чим більше власне числотим більший відсоток дисперсії пояснює цей фактор.
Знаючи всі головні компоненти для кожної події , що є реалізацією X
, можна записати його проекції на основні компоненти:
Таким чином, можна уявити всі вихідні події у нових координатах, координатах головних компонентів: 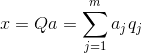
Взагалі розрізняють процедуру пошуку основних компонентів і процедуру знаходження базису з чинників та її подальше обертання, що полегшує трактування чинників, але оскільки ці процедури ідеологічно близькі і дають схожий результат, називатимемо і те й інше факторним аналізом.
За досить простою процедурою факторного аналізу криється дуже глибоке значення. Справа в тому, що якщо простір вихідних ознак - це спостерігається простір, то фактори - це ознаки, які хоча і описують властивості навколишнього світу, але в загальному випадку (якщо не збігаються з ознаками, що спостерігаються) є сутностями прихованими. Тобто формальна процедура факторного аналізу дозволяє від явищ спостережуваних перейти до виявлення явищ, хоча безпосередньо і невидимих, проте існуючих в навколишньому світі.
Можна припустити, що наш мозок активно використовує виділення факторів як одну із процедур пізнання навколишнього світу. Виділяючи фактори, ми маємо можливість будувати нові описи того, що відбувається з нами. Основа цих нових описів – виразність у подіях тих явищ, що відповідають виділеним факторам.
Дещо поясню суть факторів на побутовому рівні. Припустимо, ви менеджер з персоналу. До вас приходить безліч людей, і щодо кожного ви заповнюєте певну форму, куди записуєте різні дані про відвідувача. Переглянувши свої записи, ви можете виявити, що деякі графи мають певний взаємозв'язок. Наприклад, стрижка у чоловіків буде в середньому коротша, ніж у жінок. Лисих людей ви, швидше за все, зустрінете лише серед чоловіків, а фарбувати губи будуть лише жінки. Якщо до анкетних даних застосувати факторний аналіз, то саме стать і виявиться одним із факторів, що пояснює відразу кілька закономірностей. Але факторний аналіз дозволяє знайти всі фактори, які пояснюють кореляційні залежності у наборі даних. Це означає, що крім фактора статі, який ми можемо спостерігати, виділяться й інші, у тому числі й неявні фактори, що не спостерігаються. І якщо підлога явно фігуруватиме в анкеті, то інша важливий факторзалишиться між рядками. Оцінюючи здатність людей пов'язано викладати свої думки, оцінюючи їх кар'єрну успішність, аналізуючи їх оцінки в дипломі тощо, ви прийдете до висновку, що є Загальна оцінкаінтелекту людини, яка явно в анкеті не записана, але яка пояснює багато її пунктів. Оцінка інтелекту – це і є прихований фактор, головний компонент з високим пояснювальним ефектом. Явно ми цю компоненту не спостерігаємо, але фіксуємо ознаки, які з нею кореловані. Маючи життєвий досвід, ми можемо підсвідомо за окремими ознаками формувати уявлення про інтелект співрозмовника. Та процедура, якою при цьому користується наш мозок, є, по суті, факторним аналізом. Спостерігаючи за тим, як ті чи інші явища проявляються спільно, мозок, використовуючи формальну процедуру, виділяє фактори, як відображення стійких статистичних закономірностей, властивих навколишньому світу.
Виділення набору факторів
Ми показали, як фільтр Хебба виділяє першу головну компоненту. Виявляється, за допомогою нейронних мереж можна легко отримати не тільки першу, але і всі інші компоненти. Це можна зробити, наприклад, в такий спосіб. Припустимо, що ми маємо вхідних ознак. Візьмемо лінійних нейронів, де .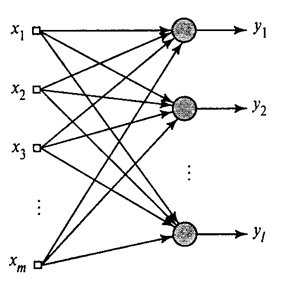
Узагальнений алгоритм Хебба(Хайкін, 2006)
Навчатимемо перший нейрон як фільтр Хебба, щоб він виділив першу головну компоненту. А ось кожен наступний нейрон навчатимемо на сигналі, з якого виключимо вплив усіх попередніх компонентів.
Активність нейронів на кроці nвизначається як 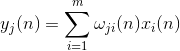
А поправка до синоптичних ваг як
де від 1 до , а від 1 до .
Для всіх нейронів це виглядає як навчання, аналогічне фільтру Хебба. З тією лише різницею, що кожен наступний нейрон бачить не весь сигнал, а лише те, що не побачили попередні нейрони. Цей принцип називається повторним оцінюванням. Ми фактично за обмеженим набором компонентів виробляємо відновлення вихідного сигналу і змушуємо наступний нейрон бачити тільки залишок, різницю між вихідним сигналом і відновленим. Цей алгоритм називається узагальненим алгоритмом Хебба.
В узагальненому алгоритмі Хебба не зовсім добре те, що він має надто обчислювальний характер. Нейрони мають бути впорядковані, і облік їхньої діяльності має здійснюватися суворо послідовно. Це дуже поєднується з принципами роботи кори мозку, де кожен нейрон хоч і взаємодіє з іншими, але працює автономно, і де немає яскраво вираженого «центрального процесора», який би визначав загальну послідовність подій. З таких міркувань дещо привабливіше виглядають алгоритми, які називають алгоритмами декореляції.
Уявимо, що ми маємо два шари нейронів Z 1 і Z 2 . Активність нейронів першого шару утворює якусь картину, яка проектується за аксонами наступного шару.
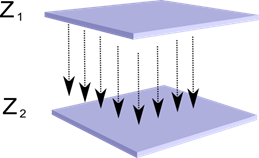
Проекція одного шару на інший
Тепер уявімо, що кожен нейрон другого шару має синаптичні зв'язки з усіма аксонами, що приходять з першого шару, якщо вони потрапляють у межі певної околиці цього нейрона (рисунок нижче). Аксони, які у таку область, утворюють рецептивне полі нейрона. Рецептивне поле нейрона – це той фрагмент загальної активності, який доступний для спостереження. Усього решти цього нейрона просто немає.
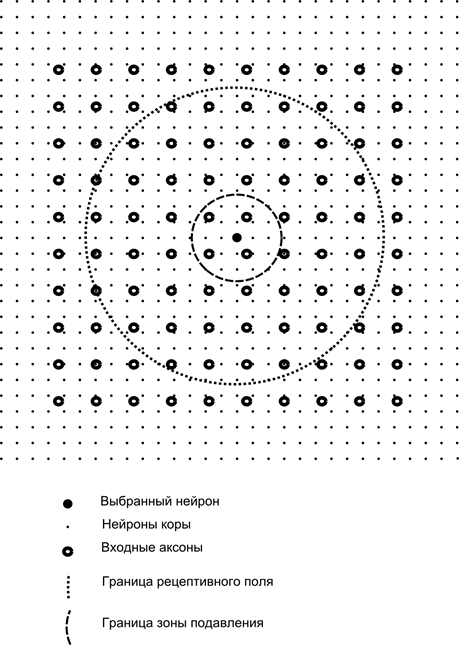
Крім рецептивного поля нейрона, введемо область трохи меншого розміру, яку назвемо зоною придушення. З'єднаємо кожен нейрон зі своїми сусідами, які у цю зону. Такі зв'язки називаються бічними або, дотримуючись прийнятої в біології термінології, латеральними. Зробимо латеральні зв'язки, що гальмують, тобто знижують активність нейронів. Логіка їх роботи – активний нейрон гальмує активність усіх нейронів, що потрапляють у його зону гальмування.
Збудливі та гальмують зв'язки можуть бути розподілені строго з усіма аксонами або нейронами в межах відповідних областей, а можуть бути задані випадково, наприклад, з щільним заповненням певного центру та експоненційним зменшенням щільності зв'язків у міру віддалення від нього. Суцільне заповнення простіше для моделювання, випадковий розподіл більш анатомічний з точки зору організації зв'язків у реальній корі.
Функцію активності нейрона можна записати:
де – підсумкова активність, – безліч аксонів, які потрапляють у рецептивну область обраного нейрона, – безліч нейронів, у зону придушення яких потрапляє обраний нейрон, – сила відповідного латерального гальмування, що набуває негативних значень.
Така функція активності є рекурсивною, оскільки активність нейронів виявляється залежною друг від друга. Це призводить до того, що практичний розрахунок провадиться ітераційно.
Навчання синаптичних вагів робиться аналогічно фільтру Хебба:
Латеральні ваги навчаються за анти-Хеббівським правилом, збільшуючи гальмування між «схожими» нейронами:
Суть цієї конструкції в тому, що Хеббовское навчання має призвести до виділення на вагах нейрона значень, що відповідають першому головному фактору, характерному для даних, що подаються. Але нейрон здатний навчатися у бік будь-якого чинника, лише якщо він активний. Коли нейрон починає виділяти фактор і, відповідно, реагувати на нього, він починає блокувати активність нейронів, що потрапляють до його зони придушення. Якщо активацію претендує кілька нейронів, то взаємна конкуренція призводить до того, що перемагає найсильніший нейрон, пригнічуючи у своїй інші. Іншим нейронам не залишається нічого іншого, окрім як навчатися в ті моменти, коли поряд немає сусідів з високою активністю. Таким чином, відбувається декореляція, тобто кожен нейрон в межах області, розмір якої визначається розміром зони придушення, починає виділяти свій ортогональний фактор всім іншим. Цей алгоритм називається алгоритмом адаптивного вилучення основних компонентів (APEX) (Kung S., Diamantaras K.I., 1990).
Ідея латерального гальмування близька за духом добре відомим за різним моделямпринципом «переможець забирає все», який також дозволяє здійснити декореляцію тієї галузі, де шукається переможець. Цей принцип використовується, наприклад, в неокогнітроні Фукушіми, картах Коханена, що самоорганізуються, також цей принцип застосовується в навчанні широко відомої ієрархічної темпоральної пам'яті Джеффа Хокінса.
Визначити переможця можна простим порівняннямактивності нейронів. Але такий перебір, що легко реалізується на комп'ютері, дещо не відповідає аналогіям з реальною корою. Але якщо поставити собі за мету зробити все на рівні взаємодії нейронів без залучення зовнішніх алгоритмів, то того ж результату можна досягти, якщо окрім латерального гальмування сусідів нейрон матиме позитивний зворотний зв'язок, що дозбуджує його. Такий прийом пошуку переможця використовується, наприклад, у мережах адаптивного резонансу Гроссберга.
Якщо ідеологія нейронної мережі це допускає, використовувати правило «переможець забирає все» дуже зручно, оскільки шукати максимум активності значно простіше, ніж ітераційно обраховувати активності з урахуванням взаємного гальмування.
Настав час закінчувати цю частину. Вийшло досить довго, але дуже не хотілося дробити пов'язану за змістом розповідь. Не дивуйтеся КДПВ, ця картинка проасоціювалася для мене одночасно зі штучним інтелектом і з головним фактором.
У статті зібрані матеріали - переважно російськомовні - для базового вивчення штучних нейронних мереж.
Штучна нейронна мережа, або ІНС - математична модель, а також її програмне або апаратне втілення, побудоване за принципом організації та функціонування біологічних нейронних мереж - мереж нервових клітинживий організм. Наука нейронних мереж існує досить давно, проте саме у зв'язку з останніми досягненняминауково-технічного прогресу ця область починає набувати популярності.
Книги
Почнемо добірку з класичного способувивчення – за допомогою книг. Ми підібрали російськомовні книги з великою кількістю прикладів:
- Ф. Уоссермен, Нейрокомп'ютерна техніка: Теорія та практика. 1992 р.
У книзі загальнодоступної формі викладаються основи побудови нейрокомп'ютерів. Описано структуру нейронних мереж та різні алгоритми їх налаштування. Окремі розділи присвячені питанням реалізації нейронних мереж. - С. Хайкін, Нейронні мережі: Повний курс. 2006 р.
Тут розглядаються основні парадигми штучних нейронних мереж. Представлений матеріал містить суворе математичне обґрунтування всіх нейромережевих парадигм, ілюструється прикладами, описом комп'ютерних експериментів, містить безліч практичних завдань, і навіть велику бібліографію.
Д. Форсайт, Комп'ютерний зір. Сучасний підхід 2004 р.
Комп'ютерний зір - це одна з найбільш затребуваних областей на даному етапі розвитку глобальних цифрових комп'ютерних технологій. Воно потрібне на виробництві, при керуванні роботами, при автоматизації процесів, у медичних та військових додатках, при спостереженні з супутників та при роботі з персональними комп'ютерами, зокрема пошуку цифрових зображень.
Відео
Немає нічого доступніше і зрозуміліше, ніж візуальне навчання за допомогою відео:
- Щоб зрозуміти, що таке взагалі машинне навчання, подивіться ось ці дві лекціївід ШАДу Яндекса.
- Вступосновні принципи проектування нейронних мереж - чудово підходить для продовження знайомства з нейронними мережами.
- Курс лекційна тему «Комп'ютерний зір» від ВМК МДУ. Комп'ютерний зір - теорія та технологія створення штучних систем, які проводять виявлення та класифікацію об'єктів у зображеннях та відеозаписах. Ці лекції можна зарахувати до запровадження у цю цікаву і складну науку.
Освітні ресурси та корисні посилання
- Портал штучного інтелекту.
- Лабораторія «Я – інтелект».
- Нейронні мережі в Matlab.
- Нейронні мережі в Python (англ.):
- Класифікація тексту за допомогою;
- Простий.
- Нейронна мережа на .
Серія наших публікацій на тему
Раніше у нас публікувався курс #neuralnetwork@tprogerпо нейронних мережах. У цьому списку публікації для вашої зручності розміщені у порядку вивчення.

