Ang bagong isinalin na pangunahing aklat-aralin ni S. Khaikin (ang ikalawang edisyon ng Amerika ng 1999 ay isinalin) na ganap na sinasabing ang kaganapan ng 2006 sa panitikang Ruso sa neuroinformatics. Ngunit dapat tandaan na kahit na ang pagsasalin ay ginawa nang walang halatang mga pagkakamali, ang mga footnote-komento ng mga tagapagsalin ay hindi masasaktan upang linawin ang terminolohiya (dahil ang parehong bagay ay maaaring tawagin sa neuroinformatics, istatistika at pagkakakilanlan ng system na may iba't ibang mga salita, ito ay kinakailangan upang bawasan ang mga termino sa isang lugar, o magbigay ng mga listahan ng mga kasingkahulugan - hindi lahat ng mga mambabasa ay magkakaroon ng malawak na pananaw). Ang mga komento ay maaari ring sumasalamin sa pag-unlad sa larangan ng mga artipisyal na neural network na naganap mula nang ilathala ang orihinal na Ingles. Umaasa ako na ang libro ay in demand at ang mga pagbabago ay gagawin kapag ang edisyon ay muling nai-print. Bukod dito, mayroong malaking bilang ng mga typo sa mga mathematical formula. Ang page na ito ay pangunahing nakatuon sa typo corrections. Ngunit dapat tandaan na hindi ko ginagarantiyahan ang pagkakumpleto ng listahan ng mga kamalian na ibinigay dito - binasa ko ang aklat na "diagonal", sa mga akma at pagsisimula iba't ibang antas pagkaasikaso, para may makaligtaan ako (o magkamali ako).
Kabanata 1
- p.32 ikalawang talata. Dito lamang ang salitang "pagganap" ay mauunawaan bilang ang bilis ng trabaho, ang kapangyarihan ng calculator. Dagdag pa sa aklat, ang "pagganap" ay mangangahulugan ng katumpakan, ang kalidad ng neural network (halimbawa, sa p. 73 sa ikalawang talata mula sa ibaba).
- S.35 p.7. Ang "VLSI Implementability" ay mas mahusay na isinalin hindi bilang "scalability", ngunit bilang "effective implementability on VLSI - very large integrated circuits".
- p.39 p.7. Ang salitang "spike" - "ejection, impulse" sa Russian neuroscience ay madalas at nakagawian na simpleng transliterated bilang "spike".
- P.49 pamagat ng talata. Marahil ang isang mas mahusay na termino ay "itinuro na graph" sa halip na "itinuro na graph".
- C.76 ikatlong talata. Imbes na link, dapat may link sa libro ni Ashby.
- P.99 konklusyon 1. Kinakailangan din na idagdag ang kaso ng sabay-sabay na kasiyahan ng parehong mga kundisyon at may sign na "
- C.105 talata 2. Ipasok ang salitang "nakikita" bago (nakikita).
Kabanata 2
- P.94 footnote 2. Ang reference sa ay malamang na hindi tama, dahil Hindi ito libro, at hindi talaga akma ang pamagat.
- P.122 huling talata. Natawa siya sa pariralang "pagpapangit ng istraktura ng mga neuron": hanggang sa ang panlabas na kaganapan ng isang concussion ay nababagay, hindi maaalala ng isang tao ang kaganapang ito. Malamang, pinagtatalunan na ang memorya ay natanto lamang sa pamamagitan ng pagdiskonekta ng mga synaptic input (mga pagtatapos) mula sa mga galamay ng mga dendrite o paglipat mula sa isang galamay patungo sa isa pa (mga termino mula sa Fig. 1.2 hanggang p. 40, dahil ang figure na ito ay angkop para sa paglalarawan). Yung. ang ating utak ay buhay at gumagalaw.
- C.129 formula (2.39). sa halip na X ay dapat na X.
- C.129 na mga formula (2.40), (2.41), (2.44). Superscript dapat q sa halip na m.
- C.137 unang talata at formula (2.61). E dapat naka-italic. At sa mga formula (2.64), (2.65), (2.67), (2.68) sa p.138 din.
- P.142 formula (142). Magdagdag ng 0 pagkatapos ng unang arrow.
- C.142 huling talata. dati huling-salita ipasok ang minus.
- C.147 unang talata. | L|=l. Yung. variable l sa kanang bahagi ng expression ay dapat ibigay sa italics (dahil ang variant sa aklat ay nalilito ito sa unit).
- P.151 na formula (2.90). Sa tuktok na linya, pagkatapos ng curly brace, ipasok F.
- C.151 formula (2.91). Ipasok ang "sa" bago N.
- C.160 huling talata sa talababa. Ang "may maliit na halaga" ay pinalitan ng "may malaking halaga".
Kabanata 3
- P.173 Larawan.3.1. Ang mga variable ay dapat ibigay sa italics alinsunod sa notasyon na pinagtibay sa aklat, dahil ang mga variable na ito ay scalar.
- P.176 na mga formula (3.5), (3.7). Dapat w* sa halip na w* .
- C.176 huling linya. Malamang, kailangan mong sumangguni, kahit na ang isyung ito ay maaari ding isaalang-alang sa tinukoy na isa.
- P.179 talababa. Dapat ay "derivative ng f(w) na may kinalaman sa w"
- P.180 ang huling linya bago ang footnote. Sa halip, maaaring mas mahusay na kunin, at maaaring hindi tama ang link.
- C.184 intermediate expression sa tuktok na linya ng formula (3.30). sa halip na x(n) ay dapat na x(i)
- C.200 talata pagkatapos ng formula (3.59). Pinagtawanan ang "Gucci-Schwartz inequality". Dapat mayroong kilalang hindi pagkakapantay-pantay ng Cauchy mula sa kurso ng unibersidad ng tore.
- C.204 ang unang talata ng seksyon 3.10 ay tungkol sa pagbabago ng isang Bayesian classifier sa isang linear separator sa isang Gaussian na kapaligiran. Ito ay tumutukoy sa kondisyon na ang mga covariance matrice ng parehong mga klase ay pareho (ipapakilala sa seksyon sa p. 207), ngunit kapag sinabi kong "Gaussian environment" kadalasang naaalala ko ang pangkalahatang sitwasyon ng dalawang normal na distribusyon na may arbitrary covariance matrice, kapag ang Bayes ay maaaring hindi bumagsak sa isang linear separator, ngunit nagbibigay ng isang parisukat na separator.
- C.206 formula (3.77). Dagdag pa, sa halip na ang λ na ipinahiwatig sa formula, ang Λ ay ipi-print nang ilang beses sa teksto at sa Fig. 3.10.
- P.216 gawain 3.11. Ang ibinigay sa itaas na limitasyon ng kabuuan ay dapat ilipat sa ilalim ng tanda ng kabuuan (at ang minus ay maaaring kunin bago ang kabuuan). Gayundin sa talata pagkatapos ng formula na ito, sa halip na w T x ay dapat na w T x
Kabanata 4
Ang aking komentaryo sa kabanata: isang bangungot, isang baguhan sa mga neural network at mga pamamaraan ng pag-optimize, kahit na pagkatapos ng paulit-ulit na pagbabasa ng kabanata at paulit-ulit na mga pagsubok (sinadya o sa pamamagitan ng pagsundot), ay malabong makapagprograma nang tama ng pagsasanay sa neural network gamit ang paraan ng backpropagation. Sa pamamagitan ng kahit na, kapag isinasaalang-alang ang mga mag-aaral lamang ng mga panlalawigang teknikal na unibersidad ay handang makipagtalo tungkol dito nang may medyo mataas na pusta. Ang pagtatanghal ay pinaghalo ang mga kinakailangan at hindi mahalagang bagay sa isang bunton, nang hindi binibigyang-diin at labis na kumplikado ang pagtatanghal (pumupunta sa "lahat o wala" na diskarte sa halip na hakbang-hakbang na pagdaragdag ng mga pamamaraan). Dagdag pa ng maraming empiricism. Bakit hindi na lang balangkasin ang pamamaraan para sa pagkalkula ng gradient ng isang kumplikadong function (isang neural network kasama ang isang layunin na pag-andar sa output nito at, kung kinakailangan, sa mga katangian ng neural network), pagkatapos, tulad ng sa Kabanata 6, i-refer ang mga mambabasa sa mga paraan ng pag-optimize ng gradient nang walang mga paghihigpit (sa Kabanata 6, ang sanggunian ay napupunta sa quadratic na mga pamamaraan ng programming), at nagpapakita mula sa makasaysayang mga halimbawa ng gradient na view ng network ng tama at hindi wastong paggamit teorya ng optimization at pag-maximize ng rate ng convergence (learning rate).
Ano ang gusto mong makita sa kabanata (o aklat) bilang karagdagan. Una, ang mga layunin na pag-andar maliban sa paraan ng least squares, lalo na para sa pagsasanay sa network ng classifier (halimbawa, ang cross-entropy function). Pangalawa, ang isang mas malinaw na pagpili ng posibilidad na magkaroon ng layunin na function na binubuo ng ilang mga termino: gamit ang halimbawa ng regularization ayon kay Tikhonov sa pamamagitan ng tahasang pag-minimize, bilang karagdagan sa aktwal na halaga ng error, gayundin ang scalar square ng gradient ng network output signal sa pamamagitan ng mga timbang ng synapses (pinagsamang trabaho ng LeCun at Drucker 1991-92), o gamit ang paraan ng paghahanap ng Flat at Drucker 1991-92. o gamit ang halimbawa ng paraan ng CLearning para sa paglilinis ng mga signal ng input ng network ni Andreas Weigend kasama ang mga co-authors. Pangatlo, ang isang mas detalyadong paglalarawan ng posibilidad ng pagkalkula ng pangalawang derivatives sa network (ang ipinahiwatig na mga gawa ng LeCun at Drucker, ang mga pamamaraan na nakalista sa pagsusuri). Pang-apat, ang isang mas detalyadong paglalarawan ng mga pamamaraan para sa pagkalkula ng nilalaman ng impormasyon-utility ng iba't ibang mga elemento at signal sa network (i.e., pagtukoy sa nilalaman ng impormasyon ng mga input, ang posibilidad ng pagbabawas hindi lamang ng mga synapses gamit ang mga pamamaraan na inilarawan sa aklat, kundi pati na rin ang pagbawas ng buong neuron, at mayroon ding isang grupo ng iba pang mga pamamaraan para sa pagbabawas ng mga synapses). Ikalima, isang tahasang indikasyon (pagkatapos ng lahat, hindi malalaman ng mga mambabasa ang kanilang sarili) sa kakayahang kalkulahin ang gradient gamit ang mga input signal ng network (upang malutas kabaligtaran na mga problema sa mga neural network na sinanay upang malutas ang isang direktang problema, upang ipakita ang paraan ng CLearning). Dagdag pa, para dito at sa iba pang mga kabanata, kung saan lumitaw ang gawain ng pag-aaral kasama ang isang guro, ilarawan nang mas detalyado ang ideya ng mga curves ng pag-aaral para sa mga neural network.
Kabanata 5
- P.357 pagkatapos ng formula (5.23). Dagdag pa sa ilang pahina E maaaring ibigay sa italics o bold, at ang pagbabago sa anyo ng notasyon ay medyo hindi sistematiko. Mas tama, sa italics, para sa E(F), E s (F), E c (F), E(F,h).
- C.361 formula (5.31). Sa halip na subscript H ay dapat na H .
- P.363 huling talata. "...linear combination..." sa halip na "...linear superposition...".
- C.364 formula (5.43). Alisin ang 1/λ.
- P.367 formula (5.59). σ sa halip na δ.
- P.369 pagkatapos ng formula (5.65). Dapat ulit linear na kumbinasyon" sa halip na "linear superposition".
- P.373 ikatlong linya ng formula (5.74). Maglagay ng pambungad na bracket bago ang pangalawa t i .
- C.382 formula (5.112). Sa mas mababang limitasyon ng halaga, idagdag ang "hindi katumbas ng k".
- C.390 pamagat ng seksyon 5.12. Sa agham na nagsasalita ng Ruso, sa halip na "core regression", ang mga terminong "nonparametric regression" (ito ang tawag sa pamamaraang ito ng mga istatistika sa Russian) o "nuclear regression" (kung isinalin "sa noo") ay karaniwang ginagamit.
- S.393 formula (5.135). Ipasok ang "...para sa lahat..." tulad ng sa (5.139) sa susunod na pahina.
- P.399 "gitna" na talata. "...algorithm para sa clustering sa pamamagitan ng k-daluyan...", pagkatapos ay hindi na lalaktawan ang salitang "average".
- C.403 hindi ayos na listahan. Masyadong pandaigdigan at hindi malabo na mga konklusyon ang iginuhit ng mga may-akda mula sa isang eksperimento, bagaman sa maraming aspeto ay sumasang-ayon ako.
- P.404 ang unang item sa listahan. Hindi naintindihan, lalo na tungkol sa "impluwensya sa mga parameter ng input". Imbes na higit na halagaλ, mas mababa ang impluwensya ng data sa pangkalahatan sa mga huling katangian ng modelo.
- P.408 unang talata. Nagdududa reference sa , marahil ay angkop .
- С.408 linya 6 ng talata 2. "basic function" sa halip na "fundamental function".
Kabanata 6
- P.431 huling pangungusap bago ang seksyon 6.4. Hindi ko naintindihan ang "mas mahusay" ng iminungkahing pagpipilian sa pamamagitan ng average ng sample (at tila nakuha ang tama nang sabay-sabay b 0 hindi magiging posible).
- S.434 formula (6.35). Index i ang huli x Hindi dapat.
- P.435 unnumbered formula sa Mercer's theorem. Sa halip na ψ dapat mayroong φ.
- P.444 talababa. Ang apelyidong Huber ay isinalin noon sa Russian bilang Huber, hindi Gaber (halimbawa, ang pagsasalin ng kanyang aklat noong panahon ng Sobyet: Huber, "Robustness in Statistics").
Kabanata 7 (hindi kumpleto)
- P.459 ikatlong linya mula sa itaas. Ang interpretasyon ng terminong "mahina na algorithm ng pag-aaral" ay ibinigay sa p.467 sa ikalawang talata mula sa itaas.
- C.459 walang bilang na mga subparagraph sa talata 2. Ang terminong "gateway network" bilang isang pagsasalin ng terminong "gating network" ay masyadong clumsy, ngunit walang iba pang (at sa parehong oras mabuti) na opsyon sa Russian. Marahil ay mas mahusay na gamitin ang terminong "weighting network", na unibersal para sa kaso ng hard switching (multipliers ng 0 o 1 para sa isang kinokontrol na signal) at para sa soft control ng attenuation coefficient (multipliers mula sa range ).
- S.463 p.2. Inalis namin ang particle na "hindi" mula sa pangungusap na ito - ang pagkakaiba-iba ng ensemble ay mas mababa kaysa sa pagkakaiba-iba ng mga indibidwal na pag-andar.
- P.471 unang linya. Ang "pagganap" (ipinaaalala namin sa iyo na ang "pagganap-pagganap" dito ay nauunawaan hindi sa kahulugan ng bilis, ngunit sa kahulugan ng katumpakan ng solusyon at generalization - tingnan ang aming komento sa p. 32) ng paunang paraan ng amplification ay nakasalalay din sa mga distribusyon na nabuo sa panahon ng operasyon nito para sa pangalawa at kasunod na mga eksperto.
- C.472 talahanayan 7.2 huling linya. Dapat F palikpik ( x)=…
Bibliograpiya
- Ilang beses ang mga salitang application, approximation, approach, applied, support, mapping, applicability, upper ay isinulat mula sa isa. p.
- . Tamang pagsulat ang mga pangalan ng isa sa mga may-akda ay makikita sa .
- . Ang tamang apelyido ng Muller ay katulad ng kanyang kapangalan.
- . Unang may-akda - B u ntine.
- . Inilabas sa parehong NIPS bilang .
- . Ang huli sa mga may-akda ay wastong pinangalanan sa .
- . Kailangan namin ng mahina sa halip na linggo.
- . Ang huling may-akda ay wastong pinangalanan sa .
- . Una - Landa u.
- . Ito ay isang kabanata sa isang libro.
- . Sch ö lkopf.
- . Sa pamagat - "... bia s termino". Sa doble ay nakasulat ito ng tama.
- . Sa pamagat - "...gamm sa".
- . Ulitin.

Sa inilarawan namin ang pinaka mga simpleng katangian mga pormal na neuron. Napag-usapan namin ang katotohanan na ang threshold adder ay mas tumpak na nagpaparami ng likas na katangian ng isang spike, at pinapayagan ka ng linear adder na gayahin ang tugon ng isang neuron, na binubuo ng isang serye ng mga impulses. Ipinakita na ang halaga sa output ng isang linear adder ay maihahambing sa dalas ng sapilitan na mga spike ng isang tunay na neuron. Ngayon ay titingnan natin ang mga pangunahing katangian na mayroon ang gayong mga pormal na neuron.
Hebb filter
Sa mga sumusunod, madalas kaming sumangguni sa mga modelo ng neural network. Sa prinsipyo, halos lahat ng mga pangunahing konsepto mula sa teorya ng mga neural network ay direktang nauugnay sa istraktura ng tunay na utak. Ang isang tao, na nahaharap sa ilang mga gawain, ay nakabuo ng maraming kawili-wiling disenyo ng neural network. Ang ebolusyon, pag-uuri sa lahat ng posibleng mga mekanismo ng neural, pinili ang lahat na naging kapaki-pakinabang para dito. Hindi dapat nakakagulat na para sa napakaraming mga modelo na naimbento ng tao, ang mga malinaw na biological prototype ay matatagpuan. Dahil ang aming salaysay ay hindi naglalayon sa anumang detalyadong presentasyon ng teorya ng mga neural network, tatalakayin lamang namin ang pinaka karaniwang mga sandali kinakailangan upang ilarawan ang mga pangunahing ideya. Para sa mas malalim na pag-unawa, lubos kong inirerekumenda na sumangguni sa espesyal na literatura. Para sa akin, ang pinakamagandang tutorial sa mga neural network ay si Simon Haykin "Neural Networks. Buong kurso” (Khaikin, 2006).Maraming mga modelo ng neural network ang nakabatay sa kilalang tuntunin sa pag-aaral ng Hebbian. Ito ay iminungkahi ng physiologist na si Donald Hebb noong 1949 (Hebb, 1949). Sa isang bahagyang maluwag na interpretasyon, mayroon itong napakasimpleng kahulugan: ang mga koneksyon ng mga neuron na nag-aapoy nang sama-sama ay dapat palakasin, ang mga koneksyon ng mga neuron na nag-iisa ay dapat humina.
Ang output state ng isang linear adder ay maaaring isulat:
Kung sinisimulan natin ang mga paunang halaga ng mga timbang na may maliliit na halaga at nagbibigay ng iba't ibang mga imahe bilang input, kung gayon walang pumipigil sa atin na subukang sanayin ang neuron na ito ayon sa panuntunan ng Hebb:
saan n ay isang discrete time step, ay isang learning rate parameter.
Sa pamamaraang ito, tinataasan namin ang mga bigat ng mga input kung saan inilalapat ang signal, ngunit ginagawa namin ito nang mas malakas, mas aktibo ang reaksyon ng sinanay na neuron mismo. Kung walang reaksyon, walang pag-aaral.
Totoo, ang gayong mga timbang ay tataas nang walang katiyakan, kaya ang normalisasyon ay maaaring ilapat upang maging matatag. Halimbawa, hatiin sa haba ng vector na nakuha mula sa "bagong" synaptic na timbang.
Sa ganitong pag-aaral, ang mga timbang ay muling ipinamamahagi sa pagitan ng mga synapses. Mas madaling maunawaan ang kakanyahan ng muling pamamahagi kung susundin mo ang pagbabago sa mga timbang sa dalawang hakbang. Una, kapag aktibo ang isang neuron, ang mga synapses na tumatanggap ng signal ay tumatanggap ng additive. Ang mga bigat ng synapses na walang signal ay nananatiling hindi nagbabago. Pagkatapos ay binabawasan ng pangkalahatang normalisasyon ang mga timbang ng lahat ng synapses. Ngunit sa parehong oras, ang mga synapses na walang signal ay nawawala kumpara sa kanilang dating halaga, at ang mga synapses na may mga signal ay muling namamahagi ng mga pagkalugi na ito sa kanilang mga sarili.
Ang panuntunan ni Hebb ay walang iba kundi isang pagpapatupad ng gradient descent method sa ibabaw ng error. Sa katunayan, pinipilit namin ang neuron na umangkop sa mga ibinigay na signal, sa bawat oras na inililipat ang mga timbang nito sa direksyon na kabaligtaran sa error, iyon ay, sa direksyon ng antigradient. Upang ang gradient descent ay humantong sa amin sa isang lokal na extremum nang hindi ito overshoot, ang rate ng descent ay dapat na sapat na maliit. Ano sa pag-aaral ng Hebbian ay isinasaalang-alang sa pamamagitan ng kaliitan ng parameter.
Ang liit ng parameter ng learning rate ay nagbibigay-daan sa amin na muling isulat ang nakaraang formula bilang isang serye sa :
Kung itatapon natin ang mga tuntunin ng pangalawang pagkakasunud-sunod at mas mataas, pagkatapos ay makukuha natin ang panuntunan sa pag-aaral ng Oja (Oja, 1982):
Ang isang positibong karagdagan ay responsable para sa pag-aaral ng Hebbian, at isang negatibo para sa pangkalahatang katatagan. Ang pagre-record sa form na ito ay nagbibigay-daan sa iyo na madama kung paano maipapatupad ang naturang pagsasanay sa isang analog na kapaligiran nang hindi gumagamit ng mga kalkulasyon, na tumatakbo lamang sa positibo at negatibong mga koneksyon.
Kaya, ang gayong sobrang simpleng pagsasanay ay may nakakagulat na pag-aari. Kung unti-unti nating bawasan ang rate ng pag-aaral, kung gayon ang mga bigat ng mga synapses ng sinanay na neuron ay magsasama-sama sa mga halaga na ang output nito ay magsisimulang tumutugma sa unang pangunahing bahagi, na makukuha kung inilapat natin ang naaangkop na mga pamamaraan ng pagsusuri ng pangunahing bahagi sa data ng pag-input. Ang disenyong ito ay tinatawag na Hebb filter.
Halimbawa, ilapat natin ang isang pixel na imahe sa input ng isang neuron, ibig sabihin, ihambing natin ang isang punto ng imahe sa bawat neuron synapse. Dalawang imahe lang ang ipapakain namin sa input ng neuron - mga larawan ng patayo at pahalang na linya na dumadaan sa gitna. Isang hakbang sa pag-aaral - isang imahe, isang linya, pahalang o patayo. Kung ang mga larawang ito ay na-average, makakakuha ka ng isang krus. Ngunit ang resulta ng pagsasanay ay hindi magiging katulad ng pag-average. Ito ang magiging isa sa mga linya. Ang isa na magiging mas karaniwan sa mga isinumiteng larawan. Hindi iha-highlight ng neuron ang average o intersection, ngunit ang mga puntong iyon na kadalasang nangyayari nang magkasama. Kung ang mga imahe ay mas kumplikado, kung gayon ang resulta ay maaaring hindi malinaw. Ngunit ito ay palaging magiging pangunahing bahagi.
Ang pagsasanay sa isang neuron ay humahantong sa katotohanan na ang isang tiyak na imahe ay naka-highlight (na-filter) sa mga kaliskis nito. Kapag nagbigay ng bagong signal, mas tumpak ang tugma sa pagitan ng signal at mga setting ng timbang, mas mataas ang tugon ng neuron. Ang isang sinanay na neuron ay maaaring tawaging isang detektor neuron. Sa kasong ito, ang imahe, na inilarawan ng mga timbang nito, ay karaniwang tinatawag na isang katangian na pampasigla.
Pangunahing Bahagi
Ang mismong ideya ng pagsusuri ng pangunahing bahagi ay simple at mapanlikha. Ipagpalagay na mayroon tayong pagkakasunod-sunod ng mga pangyayari. Inilalarawan namin ang bawat isa sa kanila sa pamamagitan ng impluwensya nito sa mga sensor kung saan natin nakikita ang mundo. Sabihin nating mayroon kaming mga sensor na naglalarawan ng mga feature . Ang lahat ng mga kaganapan para sa amin ay inilalarawan ng mga vector ng dimensyon. Ang bawat bahagi ng naturang vector ay tumuturo sa halaga ng kaukulang tampok na i-th. Magkasama silang bumubuo ng isang random na variable X . Maaari nating ilarawan ang mga kaganapang ito bilang mga punto sa -dimensional na espasyo, kung saan ang mga palatandaan na ating naobserbahan ay magsisilbing mga palakol.
Ang pag-average ng mga halaga ay nagbibigay ng mathematical na inaasahan ng random variable X, tinutukoy bilang E( X). Kung isentro natin ang data upang ang E( X)=0, pagkatapos ay ang point cloud ay iko-concentrate sa paligid ng pinanggalingan.
Ang ulap na ito ay maaaring iunat sa anumang direksyon. Sinubukan ang lahat posibleng mga direksyon, makakahanap tayo ng isa kung saan ang pagkakaiba ng data ay magiging maximum.
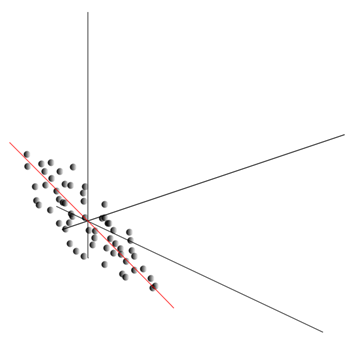
Kaya, ang direksyon na ito ay tumutugma sa unang pangunahing bahagi. Ang pangunahing bahagi mismo ay tinukoy ng isang vector ng yunit na lumalabas sa pinanggalingan at kasabay ng direksyong ito.
Susunod, makakahanap tayo ng isa pang direksyon na patayo sa unang bahagi, upang sa kahabaan nito ang dispersion ay maximum din sa lahat ng patayong direksyon. Sa paghahanap nito, nakukuha namin ang pangalawang bahagi. Pagkatapos ay maaari nating ipagpatuloy ang paghahanap, dahil sa kondisyon na kailangan nating maghanap sa mga direksyon na patayo sa mga nahanap na bahagi. Kung linearly independent ang orihinal na mga coordinate, magagawa natin ito nang isang beses, hanggang sa matapos ang dimensyon ng espasyo. Kaya, nakakakuha kami ng magkaparehong orthogonal na mga bahagi na inayos ayon sa kung anong porsyento ng pagkakaiba-iba ng data ang ipinaliwanag nila.
Natural, ang mga resultang pangunahing bahagi ay sumasalamin sa mga panloob na regularidad ng aming data. Ngunit may mga mas simpleng katangian na naglalarawan din sa kakanyahan ng umiiral na mga pattern.
Ipagpalagay na mayroon kaming mga kaganapan sa kabuuan. Ang bawat kaganapan ay inilalarawan ng isang vector. Ang mga bahagi ng vector na ito ay:
Para sa bawat tanda, maaari mong isulat kung paano ito nagpakita ng sarili sa bawat isa sa mga kaganapan:
Para sa anumang dalawang tampok kung saan nakabatay ang paglalarawan, maaaring kalkulahin ng isa ang isang halaga na nagpapakita ng antas ng kanilang magkasanib na pagpapakita. Ang halagang ito ay tinatawag na covariance: 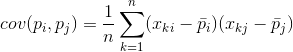
Ipinapakita nito kung paano ang mga paglihis mula sa average na halaga ng isa sa mga palatandaan ay nag-tutugma sa paghahayag sa mga katulad na paglihis ng iba pang tanda. Kung ang ibig sabihin ng mga halaga ng mga tampok ay katumbas ng zero, ang covariance ay nasa anyo: 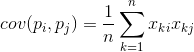
Kung itatama natin ang covariance para sa mga standard deviations na likas sa mga feature, makakakuha tayo ng linear correlation coefficient, na tinatawag ding Pearson correlation coefficient: ![]()
Ang koepisyent ng ugnayan ay may kapansin-pansing katangian. Ito ay tumatagal ng mga halaga mula -1 hanggang 1. Bukod dito, ang 1 ay nangangahulugan ng direktang proporsyonalidad ng dalawang halaga, at -1 ay nagpapahiwatig ng kanilang kabaligtaran na linear na relasyon.
Mula sa lahat ng pairwise covariances ng mga feature, maaari kang gumawa ng covariance matrix, na, gaya ng madali mong makita, ay ang mathematical na inaasahan ng produkto: ![]()
Kaya lumalabas na para sa mga pangunahing bahagi ito ay totoo:
Iyon ay, ang mga pangunahing sangkap, o, kung tawagin din sila, ang mga kadahilanan ay ang mga eigenvector ng correlation matrix. Sila ay tumutugma sa kanilang sariling mga numero. Kasabay nito, ang higit pa sariling numero, mas malaki ang porsyento ng pagkakaiba ang nagpapaliwanag sa salik na ito.
Alam ang lahat ng mga pangunahing bahagi, para sa bawat kaganapan, na kung saan ay ang pagpapatupad X
, maaari nating isulat ang mga projection nito sa mga pangunahing bahagi:
Kaya, posible na kumatawan sa lahat ng mga paunang kaganapan sa mga bagong coordinate, ang mga coordinate ng mga pangunahing bahagi: 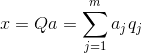
Sa pangkalahatan, ang isang pagkakaiba ay ginawa sa pagitan ng pamamaraan para sa paghahanap ng mga pangunahing bahagi at ang pamamaraan para sa paghahanap ng batayan ng mga kadahilanan at ang kasunod na pag-ikot nito, na nagpapadali sa interpretasyon ng mga kadahilanan, ngunit dahil ang mga pamamaraang ito ay malapit sa ideolohiya at nagbibigay ng katulad na resulta, tatawagin natin ang parehong pagsusuri sa kadahilanan.
Sa likod ng isang medyo simpleng pamamaraan ng pagsusuri ng kadahilanan ay may napakalalim na kahulugan. Ang katotohanan ay kung ang puwang ng mga paunang tampok ay ang sinusunod na espasyo, kung gayon ang mga kadahilanan ay mga tampok na, bagaman inilalarawan nila ang mga katangian ng nakapaligid na mundo, ngunit sa pangkalahatang kaso (kung hindi sila nag-tutugma sa mga naobserbahang tampok) ay mga nakatagong entidad. Iyon ay, ang pormal na pamamaraan ng pagsusuri ng kadahilanan ay nagpapahintulot sa amin na lumipat mula sa nakikitang mga phenomena hanggang sa pagtuklas ng mga phenomena, kahit na direktang hindi nakikita, ngunit, gayunpaman, umiiral sa nakapaligid na mundo.
Maaaring ipagpalagay na aktibong ginagamit ng ating utak ang pagpili ng mga kadahilanan bilang isa sa mga pamamaraan para sa pagkilala sa mundo sa paligid natin. Sa pamamagitan ng paghihiwalay sa mga salik, nagkakaroon tayo ng pagkakataong bumuo ng mga bagong paglalarawan ng kung ano ang nangyayari sa atin. Ang batayan ng mga bagong paglalarawan na ito ay ang pagpapakita sa kung ano ang nangyayari sa mga phenomena na tumutugma sa mga napiling salik.
Hayaan akong ipaliwanag nang kaunti ang kakanyahan ng mga kadahilanan sa antas ng sambahayan. Sabihin nating isa kang HR manager. Maraming tao ang pumupunta sa iyo, at para sa bawat sagutan mo ang isang partikular na form, kung saan isusulat mo ang iba't ibang nakikitang data tungkol sa bisita. Pagkatapos suriin ang iyong mga tala, maaari mong makita na ang ilang mga graph ay may isang tiyak na kaugnayan. Halimbawa, ang mga gupit ng lalaki ay magiging mas maikli sa karaniwan kaysa sa mga babae. Malamang na makakatagpo ka ng mga kalbo sa mga lalaki lamang, at mga babae lamang ang magpipinta ng kanilang mga labi. Kung inilapat sa personal na data factor analysis, kung gayon ito ay kasarian na lalabas na isa sa mga salik na nagpapaliwanag ng ilang mga pattern nang sabay-sabay. Ngunit nagbibigay-daan sa iyo ang pagsusuri ng kadahilanan na mahanap ang lahat ng mga kadahilanan na nagpapaliwanag ng mga ugnayan sa set ng data. Nangangahulugan ito na bilang karagdagan sa sex factor, na maaari nating obserbahan, ang iba ay mamumukod-tangi, kabilang ang implicit, unobservable factor. At kung ang kasarian ay tahasang lumilitaw sa talatanungan, kung gayon ang isa pa mahalagang salik manatili sa pagitan ng mga linya. Ang pagtatasa sa kakayahan ng mga tao na ipahayag ang kanilang mga iniisip, pagsusuri ng kanilang tagumpay sa karera, pagsusuri sa kanilang mga marka sa isang diploma at katulad na mga palatandaan, makakarating ka sa konklusyon na mayroong pangkalahatang pagtatasa ng katalinuhan ng isang tao, na hindi tahasang naitala sa talatanungan, ngunit nagpapaliwanag ng marami sa mga punto nito. Ang pagtatasa ng katalinuhan ay nakatagong salik, ang pangunahing bahagi na may mataas na epekto sa pagpapaliwanag. Malinaw, hindi namin sinusunod ang bahaging ito, ngunit inaayos namin ang mga tampok na nauugnay dito. Ang pagkakaroon ng karanasan sa buhay, maaari tayong hindi malay na bumuo ng isang ideya ng talino ng interlocutor batay sa ilang mga palatandaan. Ang pamamaraan na ginagamit ng ating utak sa kasong ito ay, sa katunayan, pagsusuri ng kadahilanan. Sa pagmamasid sa kung paano nagpapakita ng magkakasama ang ilang mga phenomena, ang utak, gamit ang isang pormal na pamamaraan, ay nagha-highlight ng mga salik bilang isang salamin ng matatag na mga pattern ng istatistika na likas sa mundo sa paligid natin.
Pagpili ng isang hanay ng mga kadahilanan
Ipinakita namin kung paano kinukuha ng Hebb filter ang unang pangunahing bahagi. Ito ay lumalabas na sa tulong ng mga neural network, madali mong makuha hindi lamang ang una, kundi pati na rin ang lahat ng iba pang mga bahagi. Magagawa ito, halimbawa, sa sumusunod na paraan. Ipagpalagay na mayroon kaming mga tampok ng pag-input. Kunin natin ang mga linear neuron, kung saan .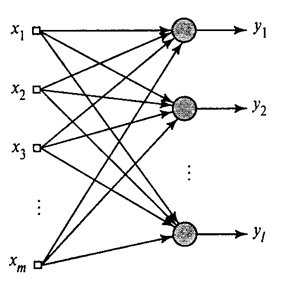
Pangkalahatang algorithm ng Hebb(Haikin, 2006)
Sasanayin natin ang unang neuron bilang Hebb filter upang makuha nito ang unang pangunahing bahagi. Ngunit sanayin namin ang bawat kasunod na neuron sa isang senyas kung saan ibubukod namin ang impluwensya ng lahat ng naunang bahagi.
Neuronal na aktibidad sa isang hakbang n tinukoy bilang 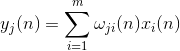
At ang pagwawasto sa synoptic weights bilang
kung saan mula 1 hanggang , at mula 1 hanggang .
Para sa lahat ng neuron, ito ay mukhang pag-aaral, katulad ng Hebb filter. Ang pagkakaiba lamang ay ang bawat kasunod na neuron ay hindi nakikita ang buong signal, ngunit kung ano lamang ang "hindi nakita" ng mga nakaraang neuron. Ang prinsipyong ito ay tinatawag na muling pagtatasa. Sa katunayan, ibinabalik namin ang orihinal na signal gamit ang isang limitadong hanay ng mga bahagi at pinipilit ang susunod na neuron na makita lamang ang natitira, ang pagkakaiba sa pagitan ng orihinal na signal at ang naibalik. Ang algorithm na ito ay tinatawag na pangkalahatang algorithm ng Hebb.
Ang hindi lubos na maganda sa pangkalahatang algorithm ng Hebb ay ang pagiging "computational" nito sa kalikasan. Ang mga neuron ay dapat mag-order, at ang pagkalkula ng kanilang aktibidad ay dapat na isagawa nang mahigpit na sunud-sunod. Ito ay hindi masyadong tugma sa mga prinsipyo ng cerebral cortex, kung saan ang bawat neuron, bagama't nakikipag-ugnayan sa iba, ay gumagana nang awtonomiya, at kung saan walang binibigkas na "central processor" na tutukoy sa pangkalahatang pagkakasunud-sunod ng mga kaganapan. Para sa mga kadahilanang ito, mukhang mas kaakit-akit ang mga algorithm na tinatawag na decorrelation algorithm.
Isipin na mayroon tayong dalawang layer ng neuron Z 1 at Z 2 . Ang aktibidad ng mga neuron ng unang layer ay bumubuo ng isang tiyak na larawan, na inaasahang kasama ang mga axon hanggang sa susunod na layer.
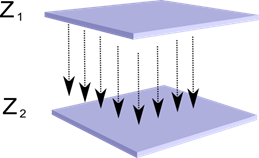
Projection ng isang layer papunta sa isa pa
Ngayon isipin na ang bawat neuron ng pangalawang layer ay may synaptic na koneksyon sa lahat ng axon na nagmumula sa unang layer, kung sila ay nasa loob ng mga hangganan ng isang partikular na kapitbahayan ng neuron na ito (Figure sa ibaba). Ang mga axon na pumapasok sa naturang lugar ay bumubuo sa receptive field ng neuron. Ang receptive field ng isang neuron ay ang fragment ng pangkalahatang aktibidad na magagamit nito para sa pagmamasid. Ang lahat ng iba pa para sa neuron na ito ay hindi umiiral.
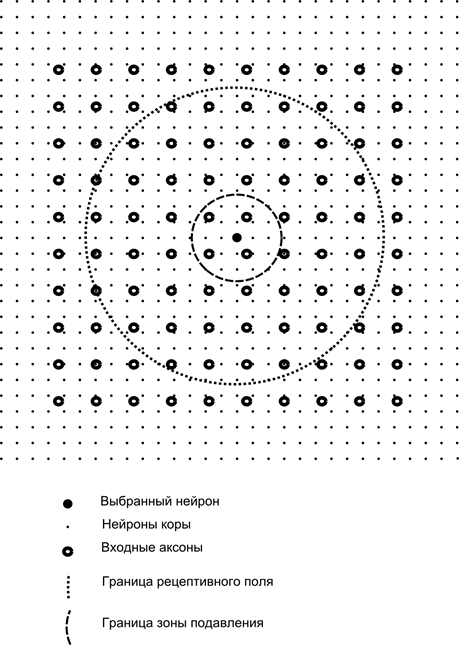
Bilang karagdagan sa receptive field ng neuron, ipinakilala namin ang isang lugar na bahagyang mas maliit na sukat, na tatawagin naming zone ng pagsugpo. Ikonekta natin ang bawat neuron sa mga kapitbahay nito na nahuhulog sa zone na ito. Ang ganitong mga koneksyon ay tinatawag na lateral o, kasunod ng terminolohiya na tinatanggap sa biology, lateral. Gawin natin ang mga lateral na koneksyon na nagbabawal, iyon ay, pagpapababa sa aktibidad ng mga neuron. Ang lohika ng kanilang trabaho ay ang isang aktibong neuron ay pumipigil sa aktibidad ng lahat ng mga neuron na nahuhulog sa zone ng pagsugpo nito.
Ang mga excitatory at inhibitory na koneksyon ay maaaring ipamahagi nang mahigpit sa lahat ng mga axon o neuron sa loob ng mga hangganan ng kaukulang mga lugar, o maaari silang itakda nang random, halimbawa, na may siksik na pagpuno ng isang tiyak na sentro at isang exponential na pagbaba sa density ng mga koneksyon habang lumalayo ka mula dito. Ang solid filling ay mas madaling i-modelo, ang random na pamamahagi ay mas anatomical sa mga tuntunin ng organisasyon ng mga koneksyon sa tunay na cortex.
Ang pag-andar ng aktibidad ng neuron ay maaaring isulat bilang:
kung saan ang pangwakas na aktibidad, ay ang hanay ng mga axon na nahuhulog sa receptive area ng napiling neuron, ay ang hanay ng mga neuron na ang suppression zone ay nahuhulog sa napiling neuron, ay ang lakas ng kaukulang lateral inhibition, na kumukuha ng mga negatibong halaga.
Ang ganitong function ng aktibidad ay recursive, dahil ang aktibidad ng mga neuron ay lumalabas na umaasa sa isa't isa. Ito ay humahantong sa katotohanan na ang praktikal na pagkalkula ay isinasagawa nang paulit-ulit.
Ang pagsasanay ng synaptic weights ay ginagawa katulad ng Hebb filter:
Ang mga lateral weight ay sinanay ayon sa anti-Hebbian na panuntunan, na nagpapataas ng pagsugpo sa pagitan ng "katulad" na mga neuron:
Ang kakanyahan ng disenyo na ito ay ang pag-aaral ng Hebbian ay dapat humantong sa paglalaan ng mga halaga sa mga kaliskis ng neuron na naaayon sa unang pangunahing kadahilanan na katangian ng ibinigay na data. Ngunit ang isang neuron ay natututo lamang sa direksyon ng anumang kadahilanan kung ito ay aktibo. Kapag ang isang neuron ay nagsimulang maglabas ng isang kadahilanan at, nang naaayon, tumugon dito, nagsisimula itong hadlangan ang aktibidad ng mga neuron na nahuhulog sa zone ng pagsugpo nito. Kung ang ilang mga neuron ay nag-aangkin na isinaaktibo, kung gayon ang kumpetisyon sa isa't isa ay humahantong sa katotohanan na ang pinakamalakas na neuron ay nanalo, habang inaapi ang lahat ng iba pa. Ang ibang mga neuron ay walang pagpipilian kundi ang matuto sa mga sandaling iyon na walang mga kapitbahay sa malapit mataas na aktibidad. Kaya, ang decorrelation ay nangyayari, iyon ay, ang bawat neuron sa loob ng rehiyon, ang laki nito ay tinutukoy ng laki ng suppression zone, ay nagsisimulang maglaan ng sarili nitong kadahilanan, orthogonal sa lahat ng iba pa. Ang algorithm na ito ay tinatawag na Adaptive Principal Component Extraction (APEX) algorithm (Kung S., Diamantaras K.I., 1990).
Ang ideya ng lateral inhibition ay malapit sa espiritu sa kilalang-kilala iba't ibang modelo ang nagwagi ay tumatagal ng lahat ng prinsipyo, na nagpapahintulot din sa decorrelation ng lugar kung saan ang nagwagi ay hinanap. Ang prinsipyong ito ay ginagamit, halimbawa, sa Fukushima neocognitron, ang mga mapa ng self-organizing ni Kohanen, at ang prinsipyong ito ay ginagamit din sa pagtuturo ng kilalang hierarchical temporal memory ni Jeff Hawkins.
Maaari mong matukoy ang nanalo simpleng paghahambing aktibidad ng neuron. Ngunit tulad ng isang enumeration, na kung saan ay madaling ipinatupad sa isang computer, medyo hindi tumutugma sa analogies na may isang tunay na cortex. Ngunit kung itinakda natin sa ating sarili ang layunin na gawin ang lahat sa antas ng pakikipag-ugnayan ng mga neuron nang hindi kinasasangkutan ng mga panlabas na algorithm, kung gayon ang parehong resulta ay maaaring makamit kung, bilang karagdagan sa pag-iwas sa pag-ilid ng mga kapitbahay, ang neuron ay may positibong feedback na higit na nakakaganyak. Ang ganitong pamamaraan para sa paghahanap ng nagwagi ay ginagamit, halimbawa, sa Grossberg adaptive resonance network.
Kung pinahihintulutan ito ng ideolohiya ng neural network, kung gayon napaka-maginhawang gamitin ang panuntunang "nagwagi sa lahat", dahil mas madaling maghanap para sa maximum na aktibidad kaysa sa paulit-ulit na pagkalkula ng mga aktibidad, na isinasaalang-alang ang mutual inhibition.
Oras na para tapusin ang bahaging ito. Ito ay naging sapat na mahaba, ngunit talagang hindi ko nais na hatiin ang salaysay na konektado sa kahulugan. Huwag magulat sa KDPV, ang larawang ito ay nauugnay para sa akin sa parehong oras sa artificial intelligence at sa pangunahing kadahilanan.
Ang artikulong ito ay naglalaman ng mga materyales - karamihan ay Russian-wika - para sa isang pangunahing pag-aaral ng mga artipisyal na neural network.
Artipisyal na neural network, o ANN - matematikal na modelo, pati na rin ang pagpapatupad ng software o hardware nito, na binuo sa prinsipyo ng organisasyon at paggana ng mga biological neural network - mga network mga selula ng nerbiyos buhay na organismo. Ang agham ng mga neural network ay umiral nang mahabang panahon, ngunit ito ay tiyak na may kaugnayan sa pinakabagong mga nagawa siyentipiko at teknolohikal na pag-unlad, ang lugar na ito ay nagsisimula upang makakuha ng katanyagan.
Mga libro
Magsimula tayo sa koleksyon klasikong paraan pag-aaral - sa tulong ng mga libro. Pumili kami ng mga aklat sa wikang Ruso na may malaking bilang ng mga halimbawa:
- F. Wasserman, Neurocomputer Engineering: Teorya at Practice. 1992
Binabalangkas ng aklat ang mga pangunahing kaalaman sa pagbuo ng mga neurocomputer sa pampublikong anyo. Ang istraktura ng mga neural network at iba't ibang mga algorithm para sa kanilang pag-tune ay inilarawan. Ang mga hiwalay na kabanata ay nakatuon sa pagpapatupad ng mga neural network. - S. Khaikin, Mga neural network: Kumpletuhin ang kurso. 2006
Dito, isinasaalang-alang ang mga pangunahing paradigma ng mga artipisyal na neural network. Ang ipinakita na materyal ay naglalaman ng isang mahigpit na mathematical na pagbibigay-katwiran ng lahat ng mga neural network paradigms, ay inilalarawan ng mga halimbawa, isang paglalarawan ng mga eksperimento sa computer, naglalaman ng isang hanay ng mga mga praktikal na gawain pati na rin ang isang malawak na bibliograpiya.
D. Forsyth, Computer Vision. Makabagong diskarte. 2004
Ang computer vision ay isa sa mga pinaka-demand na lugar sa yugtong ito sa pagbuo ng mga pandaigdigang teknolohiyang digital computer. Kinakailangan ito sa pagmamanupaktura, kontrol ng robot, automation ng proseso, mga aplikasyong medikal at militar, pagsubaybay sa satellite, at gawaing personal na computer tulad ng paghahanap ng digital na imahe.
Video
Wala nang mas naa-access at naiintindihan kaysa sa visual na pag-aaral gamit ang video:
- Upang maunawaan kung ano ang machine learning sa pangkalahatan, tingnan dito. dalawang lecture na ito mula sa ShAD Yandex.
- Panimula sa mga pangunahing prinsipyo ng disenyo ng neural network - mahusay para sa patuloy na paggalugad ng mga neural network.
- Kurso ng lecture sa paksang "Computer Vision" mula sa VMK MSU. Ang computer vision ay isang teorya at teknolohiya para sa paglikha ng mga artipisyal na sistema na nakakakita at nag-uuri ng mga bagay sa mga larawan at video. Ang mga lektyur na ito ay maaaring maiugnay sa isang panimula sa kawili-wili at kumplikadong agham na ito.
Mga mapagkukunang pang-edukasyon at kapaki-pakinabang na mga link
- Portal ng artificial intelligence.
- Laboratory "Ako ang talino".
- Mga neural network sa Matlab.
- Mga neural network sa Python (Ingles):
- Pag-uuri ng teksto na may ;
- Simple .
- Naka-on ang neural network .
Isang serye ng aming mga publikasyon sa paksa
Nakapag-publish na kami ng kurso #[email protected] sa pamamagitan ng mga neural network. Sa listahang ito, para sa iyong kaginhawahan, ang mga publikasyon ay nakaayos ayon sa pagkakasunud-sunod ng pag-aaral.

