Svježe prevedeni temeljni udžbenik S. Khaikina (prevedeno je drugo američko izdanje iz 1999.) s pravom pretendira na događaj 2006. godine u ruskoj literaturi o neuroinformatici. Ali treba napomenuti da iako je prijevod izveden bez očitih pogrešaka, fusnote i komentari prevoditelja ne bi škodili razjašnjenju terminologije (budući da se ista stvar u neuroinformatici, statistici i identifikaciji sustava može nazvati različitim riječima, to je potrebno ili svesti pojmove na jedno područje ili dati popise sinonima - neće svi čitatelji imati široku perspektivu). Komentari bi također mogli odražavati napredak u području umjetnih neuronskih mreža koji se dogodio od objavljivanja izvornika na engleskom jeziku. Nadam se da će knjiga biti tražena i da će se napraviti izmjene kada se izdanje ponovno tiska. Štoviše, postoji značajan broj tipfelera u matematičkim formulama. Ova je stranica uglavnom posvećena ispravljanju pogrešaka pri upisu. Ali treba napomenuti da ne jamčim potpunost popisa netočnosti koji su ovdje navedeni - knjigu sam čitao "dijagonalno", u napadima u različitim stupnjevima pozornost, pa sam možda nešto propustio (ili sam pogriješio).
Poglavlje 1
- Str.32 drugi odlomak. Samo se ovdje riječ "performanse" može shvatiti kao brzina rada, snaga računala. Kasnije u knjizi, "performanse" će značiti točnost, kvalitetu rada neuronske mreže (na primjer, na str. 73 u drugom paragrafu odozdo).
- Str.35 str.7. “VLSI implementabilnost” bolje je prevesti ne kao “skalabilnost”, već kao “učinkovita implementabilnost na VLSI - vrlo velikim integriranim krugovima.”
- str.39 str.7. Riječ "šiljak" - "emisija, impuls" u neuroznanosti na ruskom jeziku prilično se često i uobičajeno jednostavno transliterira kao "šiljak".
- P.49 naslov odlomka. Možda bi bolji izraz bio "usmjereni graf" umjesto "usmjereni graf".
- Str.76 treći odlomak. Umjesto linka, vjerojatno bi trebao biti link na Ashbyjevu knjigu.
- P.99 zaključak 1. Također je potrebno dodati slučaj istovremenog zadovoljenja ovih istih uvjeta i sa znakom "
- P.105 paragraf 2. Morate umetnuti riječ "vidljiv" ispred (vidljiv).
2. Poglavlje
- P.94 fusnota 2. Referenca na je najvjerojatnije netočna, jer Nije knjiga i naslov joj baš ne pristaje.
- Str.122 posljednji odlomak. Nasmijao sam se izrazu "deformacija strukture neurona": dok se ne zadovolji vanjski događaj potresa mozga, osoba se neće sjećati tog događaja. Najvjerojatnije se tvrdilo da se pamćenje ostvaruje samo isključivanjem sinaptičkih ulaza (završetaka) iz pipaka dendrita ili prelaskom s jednog pipka na drugi (pojmovi sa slike 1.2 na str. 40, budući da je ova slika prikladna za ilustraciju) . Oni. Naši mozgovi su živi i kreću se.
- P.129 formula (2.39). Umjesto x mora biti x.
- P.129 formule (2.40), (2.41), (2.44). Superskript bi trebao biti q umjesto m.
- P.137 prvi odlomak i formula (2.61). E treba biti u kurzivu. I u formulama (2.64), (2.65), (2.67), (2.68) na 138. str.
- P.142 formula (142). Dodajte 0 nakon prve strelice.
- Str.142 posljednji odlomak. Prije posljednja riječ ubaci "minus".
- P.147 prvi odlomak. | L|=l. Oni. varijabla l s desne strane izraza treba dati kurzivom (budući da ga verzija u knjizi brka s jednim).
- P.151 formula (2.90). Umetnite u gornji red nakon vitičaste zagrade F.
- C.151 formula (2.91). Umetnite "at" ispred N.
- C.160 zadnji odlomak u bilješci. "za male količine" treba zamijeniti s "za velike količine".
Poglavlje 3
- P.173 sl.3.1. Varijable treba dati kurzivom u skladu s oznakom korištenom u knjizi, jer ove varijable su skalarne.
- P.176 formule (3.5), (3.7). Mora biti w* umjesto w* .
- C.176 posljednji redak. Najvjerojatnije se trebate pozvati, iako se ovo pitanje također može razmotriti u navedenom.
- Str.179 bilješka. Trebao bi biti "derivacija f(w) u odnosu na w"
- P.180 posljednji redak prije bilješke. Možda je bolje uzeti umjesto toga, ali veza može biti netočna.
- P.184 srednji izraz u gornjem retku formule (3.30). Umjesto x(n) trebalo bi x(ja)
- P.200 odlomak nakon formule (3.59). Smijao se "Gucci-Schwartz nejednakosti". Trebala bi postojati Cauchy-Schwarzova nejednakost, koja je svima poznata sa sveučilišnog kolegija.
- P.204 prvi stavak odjeljka 3.10 govori o pretvaranju Bayesovog klasifikatora u linearni separator u Gaussovom okruženju. Ovo se odnosi na uvjet da su matrice kovarijance obiju klasa identične (bit će predstavljeno u odjeljku na str. 207), ali kad čujem izraz "Gaussovo okruženje" obično se sjetim generalizirane situacije dviju normalnih distribucija s proizvoljnom kovarijancom matrice, kada se Bayes ne može degenerirati u linearni separator, već dati kvadratnu razdjelnu plohu.
- P.206 formula (3.77). Dalje, umjesto λ navedenog u formuli, Λ će biti ispisano nekoliko puta u tekstu i na sl. 3.10.
- Str.216 zadatak 3.11. Ono što je zadano u gornjoj granici iznosa mora se pomaknuti pod znak zbroja (a minus se može staviti ispred zbroja). Također u paragrafu iza ove formule, umjesto w T x mora biti w T x
Poglavlje 4
Moj komentar o poglavlju: noćna mora, početnik u neuronskim mrežama i metodama optimizacije, čak i nakon višestrukog čitanja poglavlja i ponovljenih pokušaja (bilo namjerno ili nasumično), vjerojatno neće ispravno programirati obuku neuronske mreže koristeći povratno širenje metoda. Po barem, kada uzmem u obzir samo studente s provincijskih tehničkih sveučilišta, spreman sam o tome raspravljati s prilično visokim ulozima. Prezentacija je na hrpu pomiješala potrebne i nepotrebne stvari, bez isticanja i prekompliciranja prezentacije (pristupom “sve ili ništa” umjesto postupnim dodavanjem procedura). Plus puno empirije. Zašto jednostavno ne ocrtate metodologiju za izračunavanje gradijenta složene funkcije (neuronska mreža plus funkcija cilja nad njezinim izlazom i, ako je potrebno, nad svojstvima neuronske mreže), zatim, kao u 6. poglavlju, uputite čitatelje na gradijent metode optimizacije bez ograničenja (u 6. poglavlju referenca ide na metode kvadratnog programiranja), i ocrtajte nekoliko povijesnih primjera točnih i netočnih pristupa korištenju mrežno izračunatih gradijenata sa stajališta teorije gradijentne optimizacije i maksimiziranja stope konvergencije (stopa učenja).
Koje biste dodatne stvari željeli vidjeti u poglavlju (ili knjizi). Prvo, objektivne funkcije osim najmanjih kvadrata, posebno za obuku mreže klasifikatora (na primjer, unakrsna entropijska funkcija). Drugo, jasnije isticanje mogućnosti postojanja objektivne funkcije koja se sastoji od nekoliko članova: korištenjem primjera regularizacije prema Tihonovu putem eksplicitne minimizacije, osim same vrijednosti pogreške, također gradijenta skalarnog kvadrata mrežnih izlaznih signala pomoću težine sinapsi (zajednički rad LeCuna i Druckera 1991.-92.), bilo korištenjem primjera metode traženja ravnih minina Hochreitera i Schmidhubera, ili primjerom metode CLearning za čišćenje mrežnih ulaznih signala Andreasa Weigenda i sur. Treće, detaljniji opis mogućnosti izračunavanja sekundarne derivacije u mreži (naznačeni radovi LeCuna i Druckera, metode navedene u recenziji). Četvrto, detaljniji opis metoda za izračunavanje informacijskog sadržaja-korisnosti različitih elemenata i signala u mreži (tj. određivanje informacijskog sadržaja ulaza, mogućnost smanjenja ne samo sinapsi pomoću metoda opisanih u knjizi, već i smanjenja cijele neurone, a postoji i puno opcija za smanjenje sinapsi drugim metodama). Peto, postoji eksplicitna indikacija (čitatelji to neće sami shvatiti) o mogućnosti izračunavanja gradijenta pomoću ulaznih signala mreže (za rješavanje inverzni problemi na neuronskim mrežama osposobljeni za rješavanje izravnog problema kako bi predstavili metodu CLearning). Osim toga, za ovo i druga poglavlja u kojima se pojavljuje zadatak nadziranog učenja, detaljnije opišite ideju krivulja učenja za neuronske mreže.
5. poglavlje
- Str.357 nakon formule (5.23). Dalje na nekoliko stranica E može se dati u kurzivu ili podebljano, a promjena oblika pisanja prilično je slučajna. Točnije - kurzivom, za E(F), E s(F), E c (F), E(F,h).
- P.361 formula (5.31). Umjesto indeksa H mora biti H .
- P.363 posljednji odlomak. "...linearnom kombinacijom..." umjesto "...linearnom superpozicijom...".
- P.364 formula (5.43). Uklonite 1/λ.
- P.367 formula (5.59). σ umjesto δ.
- Str.369 nakon formule (5.65). Mora postojati opet" linearna kombinacija" umjesto "linearne superpozicije".
- P.373 treći redak formule (5.74). Umetnite uvodnu zagradu prije druge t ja .
- P.382 formula (5.112). Na donju granicu iznosa dodajte "nije jednako k".
- P.390 naslov odjeljka 5.12. U znanosti na ruskom jeziku umjesto "jezgrene regresije" obično se koriste pojmovi "neparametrijska regresija" (tako se ova metoda statistike naziva na ruskom) ili "jezgrena regresija" (ako se prevodi "direktno").
- P.393 formula (5.135). Unesite "...za sve..." kao u (5.139) na sljedećoj stranici.
- P.399 “srednji” odlomak. "...algoritam grupiranja po k-prosjek...”, tada se riječ “prosječno” više neće preskakati.
- P.403 nenumerirani popis. Autori iz jednog eksperimenta izvode previše globalne i nedvosmislene zaključke, iako se uglavnom slažu.
- P.404 je prva stavka na popisu. Ne razumijem, pogotovo što se tiče "utjecaja na ulazne parametre". Rađe nego više vrijednostiλ, manji je utjecaj podataka općenito na konačna svojstva modela.
- P.408 prvi odlomak. Link na je upitan, možda upali.
- P.408 redak 6 stavka 2. „osnovna funkcija” umjesto „temeljna funkcija”.
Poglavlje 6
- P.431 zadnja rečenica prije odjeljka 6.4. Nisam razumio "bolju" predloženog izbora kroz prosjek uzorka (i čini se da sam dobio točan b 0 neće biti moguće).
- P.434 formula (6.35). Indeks ja zadnji x ne bi trebalo biti.
- P.435 nenumerirane formule u Mercerovom teoremu. Umjesto ψ treba biti φ.
- P.444 bilješka. Prezime Huber ranije je na ruski prevedeno kao Huber, a ne Haber (na primjer, prijevod njegove knjige za vrijeme SSSR-a: Huber, “Robusnost u statistici”).
Poglavlje 7 (ne u potpunosti)
- P.459 treći redak odozgo. Definicija pojma "algoritam slabog učenja" data je na str. 467 u drugom paragrafu odozgo.
- P.459 nenumerirani podstavci u stavku 2. Izraz "gateway network" kao prijevod izraza "gateway network" je previše nespretan, ali još nema druge (i dobre) opcije na ruskom. Vjerojatno bi bilo bolje koristiti izraz "mreža ponderiranja", koji je univerzalan i za slučaj tvrdog prebacivanja (množitelji 0 ili 1 za kontrolirani signal) i za meku kontrolu koeficijenta prigušenja (množitelji iz raspona ).
- Str.463 str.2. Iz ove rečenice uklanjamo česticu "ne" - disperzija ansambla manja je od disperzije pojedinačnih funkcija.
- Str.471 prvi redovi. “Performanse” (podsjećamo da se “performanse” ovdje ne shvaćaju u smislu brzine, već u smislu točnosti rješenja i generalizacije - vidi naš komentar na str. 32) originalne metode pojačanja također ovise o distribucijama formirana tijekom njezina djelovanja za drugog i sljedeće stručnjake.
- P.472 tablica 7.2 posljednji redak. Mora biti F peraja ( x)=…
Bibliografija
- Mnogo puta se riječi primjena, aproksimacija, pristup, primijenjeno, podrška, mapiranje, primjenjivost, gornji pišu s jednim str.
- . Ispravno pisanje Imena jednog od autora mogu se vidjeti u.
- . Müllerovo ispravno prezime je isto kao i njegov imenjak.
- . Prvi autor - B u ntine.
- . Objavljeno u istom NIPS-u kao i .
- . Posljednji od autora točno je naveden u.
- . Trebamo slabe umjesto tjedna.
- . Posljednji autor točno je naveden u .
- . Prvo - Landa u.
- . Ovo je poglavlje u knjizi.
- . Sch ö lkopf.
- . U naslovu - “…bia s pojam". Točno je napisano u duplikatu.
- . U naslovu - "…gamm na".
- . Ponoviti.

U opisali smo najviše jednostavna svojstva formalni neuroni. Razgovarali smo o činjenici da zbrajalo praga točnije reproducira prirodu jednog šiljka, a linearno zbrajalo omogućuje simulaciju odgovora neurona koji se sastoji od niza impulsa. Pokazali su da se vrijednost na izlazu linearnog zbrajala može usporediti s učestalošću izazvanih šiljaka pravog neurona. Sada ćemo pogledati osnovna svojstva koja imaju takvi formalni neuroni.
Hebb filter
U nastavku ćemo se često pozivati na modele neuronske mreže. U principu, gotovo svi osnovni pojmovi iz teorije neuronskih mreža izravno su povezani sa strukturom pravog mozga. Čovjek je, suočen s određenim problemima, došao do mnogih zanimljivih dizajna neuronskih mreža. Evolucija je, prolazeći kroz sve moguće neuralne mehanizme, odabrala sve što joj se pokazalo korisnim. Ne treba čuditi da se za mnoge modele koje je izmislio čovjek mogu pronaći jasni biološki prototipovi. Budući da naš narativ nema za cilj detaljno predstaviti teoriju neuronskih mreža, dotaknut ćemo se samo onih naj općim točkama potrebno za opisivanje glavnih ideja. Za dublje razumijevanje toplo preporučujem da se obratite specijaliziranoj literaturi. Za mene je najbolji udžbenik o neuronskim mrežama "Neuralne mreže" Simona Khaikina. Kompletan tečaj" (Khaikin, 2006).Mnogi modeli neuronskih mreža temelje se na dobro poznatom Hebbianovom pravilu učenja. Predložio ga je fiziolog Donald Hebb 1949. godine (Hebb, 1949.). U pomalo slobodnoj interpretaciji, to ima vrlo jednostavno značenje: veze između neurona koji se aktiviraju zajedno trebaju biti ojačane, veze između neurona koji se aktiviraju neovisno trebaju oslabiti.
Izlazno stanje linearnog zbrajala može se napisati:
Ako iniciramo početne vrijednosti težine s malim vrijednostima i dostavimo različite slike kao ulaz, tada nas ništa ne sprječava da pokušamo trenirati ovaj neuron prema Hebbovom pravilu:
Gdje n– diskretni vremenski korak, – parametar brzine učenja.
Ovim postupkom povećavamo težine onih ulaza na koje se signal primjenjuje, ali to činimo to jače, što je aktivnija reakcija samog neurona koji uči. Ako nema reakcije, tada se učenje ne događa.
Istina, takve težine će rasti bez ograničenja, tako da se normalizacija može primijeniti za stabilizaciju. Na primjer, podijelite s duljinom vektora dobivenog iz "novih" sinaptičkih težina.
S takvim učenjem, težine se preraspodjeljuju između sinapsi. Bit redistribucije lakše ćete shvatiti ako promjenu utega pratite u dva koraka. Prvo, kada je neuron aktivan, one sinapse koje primaju signal dobivaju dodatak. Težine sinapsi bez signala ostaju nepromijenjene. Opća normalizacija tada smanjuje težine svih sinapsi. Ali u isto vrijeme, sinapse bez signala gube u usporedbi s prethodnom vrijednošću, a sinapse sa signalima preraspodjeljuju te gubitke među sobom.
Hebbovo pravilo nije ništa drugo nego implementacija metode gradijentnog spuštanja duž površine pogreške. U biti, tjeramo neuron da se prilagodi dostavljenim signalima, svaki put pomičući svoje težine u smjeru suprotnom od pogreške, odnosno u smjeru antigradijenta. Kako bi nas silazak uz gradijent doveo do lokalnog ekstrema, a da ga ne pređemo, brzina spuštanja mora biti prilično mala. Što se u Hebbian učenju uzima u obzir malenošću parametra.
Mala vrijednost parametra stope učenja omogućuje nam da prepišemo prethodnu formulu kao niz u:
Ako odbacimo članove drugog reda i više, dobivamo Ojino pravilo učenja (Oja, 1982.):
Pozitivni aditiv odgovoran je za Hebbian učenje, a negativni aditiv za opću stabilnost. Snimanje u ovom obliku omogućuje vam da osjetite kako se takav trening može provesti u analognom okruženju bez upotrebe izračuna, radeći samo s pozitivnim i negativnim vezama.
Dakle, takav iznimno jednostavan trening ima nevjerojatno svojstvo. Ako postupno smanjujemo stopu učenja, težine sinapsi treniranog neurona će konvergirati do takvih vrijednosti da njegov izlaz počinje odgovarati prvoj glavnoj komponenti, što bi se dobilo ako bismo primijenili odgovarajuće postupke analize glavnih komponenti na dostavljene podatke. Ovaj dizajn se naziva Hebbov filter.
Na primjer, pustimo sliku piksela na ulaz neurona, to jest, pridružujemo jednu točku slike svakoj sinapsi neurona. Na ulaz neurona dostavit ćemo samo dvije slike - slike okomitih i vodoravnih linija koje prolaze središtem. Jedan korak učenja - jedna slika, jedna linija, vodoravna ili okomita. Ako se ove slike izračunaju u prosjeku, dobit ćete križić. Ali rezultat učenja neće biti sličan prosjeku. Ovo će biti jedna od linija. Ona koja će se češće pojavljivati na poslanim slikama. Neuron neće istaknuti prosjek ili presjek, već one točke koje se najčešće pojavljuju zajedno. Ako su slike složenije, rezultat možda neće biti tako jasan. Ali ovo će uvijek biti glavna komponenta.
Treniranje neurona dovodi do činjenice da je određena slika istaknuta (filtrirana) na njegovim ljestvicama. Kada se da novi signal, što je točnije podudaranje između signala i postavki težine, veći je odgovor neurona. Istrenirani neuron se može nazvati detektorskim neuronom. U tom se slučaju slika koja je opisana svojim mjerilima obično naziva karakterističnim podražajem.
Glavne komponente
Sama ideja metode glavne komponente je jednostavna i genijalna. Recimo da imamo niz događaja. Svaku od njih opisujemo kroz njen utjecaj na senzore kojima percipiramo svijet. Recimo da imamo senzore koji opisuju značajke. Svi događaji za nas su opisani vektorima dimenzija. Svaka komponenta takvog vektora označava vrijednost odgovarajućeg atributa. Zajedno čine slučajnu varijablu x . Te događaje možemo prikazati kao točke u -dimenzionalnom prostoru, gdje će osi biti znakovi koje promatramo.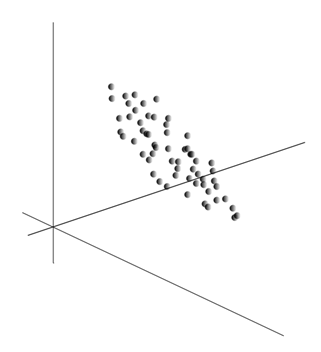
Usrednjavanje vrijednosti daje matematičko očekivanje slučajne varijable x, označen kao E( x). Ako centriramo podatke tako da E( x)=0, onda će oblak točaka biti koncentriran oko ishodišta.
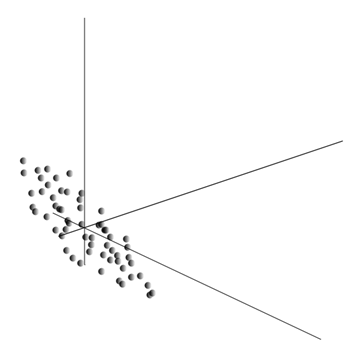
Ovaj oblak može biti izdužen u bilo kojem smjeru. Probavši sve mogući pravci, možemo pronaći onu duž koje će disperzija podataka biti maksimalna.
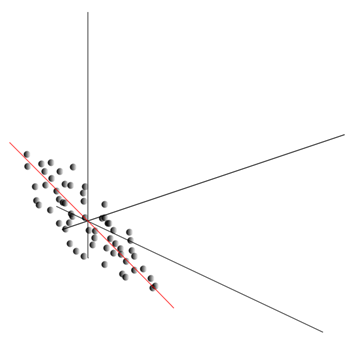
Dakle, ovaj smjer odgovara prvoj glavnoj komponenti. Sama glavna komponenta određena je jediničnim vektorom koji izlazi iz ishodišta i podudara se s tim smjerom.
Zatim možemo pronaći drugi pravac, okomit na prvu komponentu, tako da je duž njega disperzija također najveća među svim okomitim pravcima. Pronašavši ga, dobivamo drugu komponentu. Zatim možemo nastaviti pretragu, postavljajući uvjet da moramo tražiti između pravaca okomitih na već pronađene komponente. Ako su početne koordinate bile linearno neovisne, onda to možemo činiti jednom do kraja dimenzije prostora. Tako ćemo dobiti međusobno ortogonalne komponente, poredane po postotku varijance u podacima koje objašnjavaju.
Naravno, rezultirajuće glavne komponente odražavaju unutarnje obrasce naših podataka. Ali postoje jednostavnije karakteristike koje također opisuju bit postojećih obrazaca.
Pretpostavimo da imamo ukupno n događaja. Svaki događaj je opisan vektorom. Komponente ovog vektora:
Za svaki znak možete napisati kako se manifestirao u svakom od događaja:
Za bilo koje dvije karakteristike na kojima se temelji opis moguće je izračunati vrijednost koja pokazuje stupanj njihove zajedničke manifestacije. Ova veličina se naziva kovarijanca: 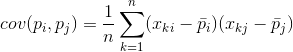
Pokazuje kako se odstupanja od prosječne vrijednosti jednog obilježja podudaraju u manifestaciji sa sličnim odstupanjima drugog obilježja. Ako su srednje vrijednosti karakteristika jednake nuli, tada kovarijanca ima oblik: 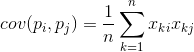
Ako ispravimo kovarijancu za standardna odstupanja svojstvena karakteristikama, dobit ćemo linearni koeficijent korelacije, koji se također naziva Pearsonov koeficijent korelacije: ![]()
Koeficijent korelacije ima izvanrednu osobinu. Uzima vrijednosti od -1 do 1. Štoviše, 1 znači izravnu proporcionalnost dviju veličina, a -1 označava njihov inverzni linearni odnos.
Od svih uparenih kovarijancija značajki, možemo stvoriti matricu kovarijancije, koja je, kao što možete lako vidjeti, matematičko očekivanje proizvoda: ![]()
Tako se ispostavlja da za glavne komponente vrijedi sljedeće:
To jest, glavne komponente, ili, kako se još nazivaju, faktori, su svojstveni vektori korelacijske matrice. One odgovaraju svojstvenim vrijednostima. Istovremeno, što više svojstvena vrijednost, veći je postotak varijance objašnjen ovim faktorom.
Poznavanje svih glavnih komponenti, za svaki događaj koji je realizacija x
, možemo napisati njegove projekcije na glavne komponente:
Dakle, moguće je prikazati sve početne događaje u novim koordinatama, koordinatama glavnih komponenti: 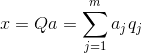
Općenito, razlikujemo postupak traženja glavnih komponenti od postupka traženja baze iz faktora i njegove naknadne rotacije, što olakšava interpretaciju faktora, ali budući da su ti postupci ideološki bliski i daju sličan rezultat, oboje će nazvati faktorskom analizom.
Iza prilično jednostavnog postupka faktorske analize krije se vrlo duboko značenje. Činjenica je da ako je prostor početnih obilježja prostor koji se može promatrati, onda su faktori obilježja koja, iako opisuju svojstva okolnog svijeta, u općem slučaju (ako se ne poklapaju s promatranim obilježjima) predstavljaju skrivene entitete. To jest, formalni postupak faktorske analize omogućuje nam prijelaz s vidljivih pojava na otkrivanje pojava, iako izravno nevidljivih, ali ipak postoje u okolnom svijetu.
Može se pretpostaviti da naš mozak aktivno koristi odabir čimbenika kao jedan od postupaka za razumijevanje svijeta oko nas. Identificiranjem čimbenika dobivamo priliku izgraditi nove opise onoga što nam se događa. Osnova ovih novih opisa je izražavanje u onome što se događa onih pojava koje odgovaraju identificiranim čimbenicima.
Dopustite mi da malo objasnim bit faktora na svakodnevnoj razini. Recimo da ste menadžer ljudskih resursa. Dolazi vam mnogo ljudi, a za svakoga od njih ispunjavate određeni formular u koji bilježite razne vidljive podatke o posjetitelju. Nakon što kasnije pregledate svoje bilješke, možda ćete otkriti da neki grafikoni imaju određeni odnos. Na primjer, muške frizure će u prosjeku biti kraće od ženskih. Najvjerojatnije ćete sresti ćelave samo među muškarcima, a samo će žene nositi ruž. Ako se primjenjuje na osobne podatke faktorska analiza, tada će spol biti jedan od čimbenika koji objašnjava nekoliko obrazaca odjednom. Ali analiza faktora omogućuje vam da pronađete sve faktore koji objašnjavaju korelacije u skupu podataka. To znači da će osim faktora spola, koji možemo promatrati, postojati i drugi, uključujući implicitne, nevidljive čimbenike. A ako se spol eksplicitno pojavljuje u upitniku, onda drugi važan faktor ostat će između redaka. Procjenjujući sposobnost ljudi da izraze svoje misli, procjenjujući njihovu uspješnost u karijeri, analizirajući ocjene na diplomi i slične znakove, doći ćete do zaključka da postoji Cjelokupna ocjena ljudske inteligencije, što nije eksplicitno zabilježeno u upitniku, ali koje objašnjava mnoge njegove točke. Procjena inteligencije je to što jest skriveni faktor, glavna komponenta s visokim eksplanatornim učinkom. Ovu komponentu ne promatramo eksplicitno, ali bilježimo znakove koji su s njom u korelaciji. S obzirom na životno iskustvo, možemo podsvjesno na temelju određenih karakteristika stvoriti predodžbu o inteligenciji našeg sugovornika. Procedura koju naš mozak u ovom slučaju koristi je u biti faktorska analiza. Promatrajući kako se određeni fenomeni pojavljuju zajedno, mozak formalnom procedurom identificira čimbenike kao odraz stabilnih statističkih obrazaca svojstvenih svijetu oko nas.
Identifikacija skupa faktora
Pokazali smo kako Hebbov filter odabire prvu glavnu komponentu. Ispada da uz pomoć neuronskih mreža možete lako dobiti ne samo prvu, već i sve ostale komponente. To se može učiniti, na primjer, na sljedeći način. Pretpostavimo da imamo ulazne značajke. Uzmimo linearne neurone, gdje je .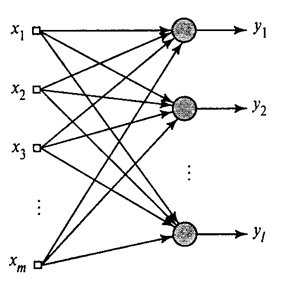
Generalizirani Hebbov algoritam(Khajkin, 2006.)
Istrenirat ćemo prvi neuron kao Hebbov filter tako da odabere prvu glavnu komponentu. Ali svaki sljedeći neuron ćemo trenirati na signalu iz kojeg ćemo isključiti utjecaj svih prethodnih komponenti.
Neuronska aktivnost tijekom koraka n definirano kao 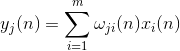
A korekcija sinoptičkih težina je kao
gdje je od 1 do , a od 1 do .
Za sve neurone ovo izgleda kao učenje slično Hebbovom filtru. Jedina razlika je u tome što svaki sljedeći neuron ne vidi cijeli signal, već samo ono što prethodni neuroni "nisu vidjeli". Ovo načelo naziva se reevaluacija. Mi zapravo vraćamo izvorni signal iz ograničenog skupa komponenti i prisiljavamo sljedeći neuron da vidi samo ostatak, razliku između izvornog signala i obnovljenog. Ovaj algoritam se naziva generalizirani Hebbov algoritam.
Ono što nije sasvim dobro kod generaliziranog Hebbovog algoritma je to što je previše "kompjuterske" prirode. Neuroni moraju biti poredani, a njihova aktivnost mora se brojiti strogo sekvencijalno. To nije baš kompatibilno s principima rada cerebralnog korteksa, gdje svaki neuron, iako je u interakciji s ostalima, djeluje autonomno i gdje ne postoji jasno definiran “centralni procesor” koji bi određivao cjelokupni slijed događaja. Iz tih razloga algoritmi koji se zovu dekorelacijski algoritmi izgledaju nešto privlačnije.
Zamislimo da imamo dva sloja neurona Z 1 i Z 2. Aktivnost neurona u prvom sloju formira određenu sliku, koja se projicira duž aksona na sljedeći sloj.
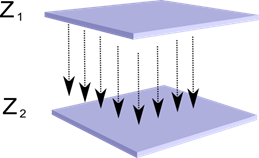
Projekcija jednog sloja na drugi
Sada zamislite da svaki neuron drugog sloja ima sinaptičke veze sa svim aksonima koji dolaze iz prvog sloja, ako su unutar granica određenog susjedstva ovog neurona (slika dolje). Aksoni koji ulaze u takvo područje formiraju receptivno polje neurona. Receptivno polje neurona je onaj fragment opće aktivnosti koji mu je dostupan za promatranje. Sve ostalo za ovaj neuron jednostavno ne postoji.
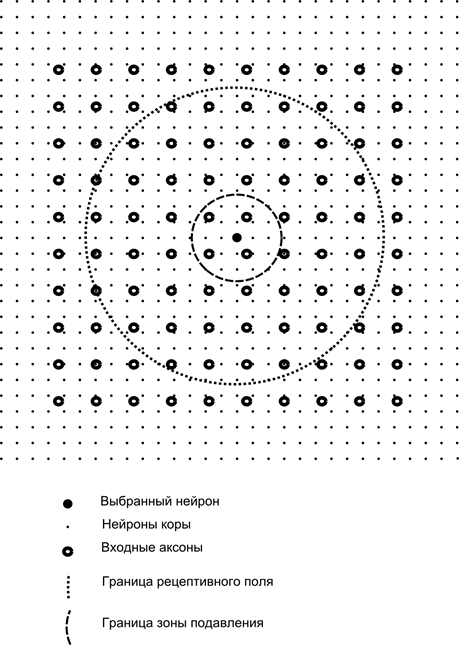
Uz receptivno polje neurona uvest ćemo nešto manje područje koje ćemo nazvati zonom supresije. Povežimo svaki neuron s njegovim susjedima koji spadaju u ovu zonu. Takve se veze nazivaju lateralne ili, prema terminologiji prihvaćenoj u biologiji, lateralne. Lateralne veze učinimo inhibicijskim, odnosno smanjenjem aktivnosti neurona. Logika njihova rada je da aktivni neuron inhibira aktivnost svih onih neurona koji spadaju u njegovu zonu inhibicije.
Ekscitatorne i inhibicijske veze mogu biti raspoređene striktno sa svim aksonima ili neuronima unutar granica odgovarajućih područja, ili se mogu odrediti nasumično, na primjer, s gustim punjenjem određenog centra i eksponencijalnim smanjenjem gustoće veza kao jednog. udaljava se od njega. Kontinuirano punjenje je lakše za modeliranje; nasumična raspodjela je anatomskija sa stajališta organizacije veza u stvarnom korteksu.
Funkcija aktivnosti neurona može se napisati:
gdje je konačna aktivnost, je skup aksona koji padaju u receptivno područje odabranog neurona, je skup neurona u čiju zonu supresije pada odabrani neuron, i je snaga odgovarajuće lateralne inhibicije, koja uzima negativne vrijednosti.
Ova funkcija aktivnosti je rekurzivna, jer se pokazalo da aktivnost neurona ovisi jedna o drugoj. To dovodi do činjenice da se praktični proračuni izvode iterativno.
Uvježbavanje sinaptičkih utega radi se slično Hebbovom filtru:
Lateralne težine uče prema anti-Hebbianovom pravilu, povećavajući inhibiciju između "sličnih" neurona:
Bit ovog dizajna je da Hebbian učenje treba dovesti do raspodjele na neuronskim ljestvicama vrijednosti koje odgovaraju prvom glavnom faktoru karakterističnom za dostavljene podatke. Ali neuron može učiti u smjeru bilo kojeg čimbenika samo ako je aktivan. Kada neuron počne lučiti faktor i, sukladno tome, reagirati na njega, on počinje blokirati aktivnost neurona koji padaju u njegovu zonu supresije. Ako se nekoliko neurona natječe za aktivaciju, tada međusobno natjecanje dovodi do toga da pobjeđuje najjači neuron, potiskujući sve ostale. Ostali neuroni nemaju drugog izbora nego učiti u onim trenucima kada u blizini nema susjeda s njima. visoka aktivnost. Tako dolazi do dekorelacije, odnosno svaki neuron unutar područja, čija je veličina određena veličinom zone supresije, počinje isticati vlastiti faktor, ortogonalno svim ostalima. Ovaj algoritam naziva se algoritam adaptivne glavne komponente (APEX) (Kung S., Diamantaras K.I., 1990.).
Ideja bočne inhibicije bliska je u duhu dobro poznatoj različiti modeli princip „pobjednik uzima sve“, koji omogućuje i dekorelaciju područja u kojem se traži pobjednik. Ovaj princip se koristi, na primjer, u neokognitronu u Fukushimi, Kohanenovim samoorganizirajućim mapama, a ovaj princip se također koristi u treniranju dobro poznatog hijerarhijskog temporalnog pamćenja Jeffa Hawkinsa.
Možete odrediti pobjednika jednostavna usporedba aktivnost neurona. Ali takvo pretraživanje, koje je lako implementirati na računalu, donekle je u suprotnosti s analogijama sa stvarnim korteksom. Ali ako postavite cilj učiniti sve na razini interakcije između neurona bez uključivanja vanjskih algoritama, tada se isti rezultat može postići ako, osim bočne inhibicije susjeda, neuron ima pozitivnu povratnu informaciju koja ga uzbuđuje. Ova tehnika za pronalaženje pobjednika koristi se, primjerice, u Grossbergovim adaptivnim rezonantnim mrežama.
Ako ideologija neuronske mreže to dopušta, onda je korištenje pravila "pobjednik uzima sve" vrlo zgodno, budući da je traženje maksimalne aktivnosti puno jednostavnije od iterativnog izračunavanja aktivnosti uzimajući u obzir međusobnu inhibiciju.
Vrijeme je da završimo ovaj dio. Ispalo je dosta dugo, ali stvarno nisam želio dijeliti pripovijest koja je značenjski povezana. Neka vas KDPV ne iznenadi, ova slika je za mene bila povezana i s umjetnom inteligencijom i s glavnim faktorom.
Ovaj članak sadrži materijale - uglavnom na ruskom - za osnovno proučavanje umjetnih neuronskih mreža.
Umjetna neuronska mreža ili ANN - matematički model, kao i njegova programska ili hardverska izvedba, izgrađena na principu organizacije i funkcioniranja bioloških neuronskih mreža - mreža nervne ćeliježivi organizam. Znanost o neuronskim mrežama postoji već dosta dugo, ali je upravo u vezi s najnovija dostignuća Sa znanstvenim i tehnološkim napretkom ovo područje počinje dobivati na popularnosti.
knjige
Počnimo s odabirom klasičan način proučavanje – uz pomoć knjiga. Odabrali smo knjige na ruskom jeziku s velikim brojem primjera:
- F. Wasserman, Neuroračunalna tehnologija: teorija i praksa. 1992. godine
Knjiga u javno dostupnom obliku iznosi osnove izgradnje neuroračunala. Opisana je struktura neuronskih mreža i različiti algoritmi za njihovu konfiguraciju. Zasebna poglavlja posvećena su implementaciji neuronskih mreža. - S. Khaikin, Neuralne mreže: Cjelovit tečaj. 2006
Ovdje se raspravlja o glavnim paradigmama umjetnih neuronskih mreža. Prezentirani materijal sadrži striktno matematičko opravdanje za sve paradigme neuronskih mreža, ilustriran je primjerima, opisima računalnih eksperimenata i sadrži mnoge praktični problemi, kao i opširnu bibliografiju.
D. Forsythe, Računalni vid. Moderan pristup. 2004. godine
Računalni vid jedno je od najpopularnijih područja u ovoj fazi razvoja globalnih digitalnih računalnih tehnologija. Potreban je u proizvodnji, kontroli robota, automatizaciji procesa, medicinskim i vojnim aplikacijama, satelitskom nadzoru i aplikacijama osobnih računala kao što je pronalaženje digitalnih slika.
Video
Ne postoji ništa pristupačnije i razumljivije od vizualnog učenja pomoću videa:
- Da biste razumjeli što je strojno učenje općenito, pogledajte ovdje ova dva predavanja od Yandex ShaD.
- Uvod u osnovne principe dizajna neuronske mreže - izvrsno za nastavak vašeg uvoda u neuronske mreže.
- Tečaj predavanja na temu “Računalni vid” iz Komiteta za računalstvo Moskovskog državnog sveučilišta. Računalni vid je teorija i tehnologija stvaranja umjetnih sustava koji otkrivaju i klasificiraju objekte na slikama i video zapisima. Ova predavanja mogu se smatrati uvodom u ovu zanimljivu i složenu znanost.
Obrazovni resursi i korisne poveznice
- Portal umjetne inteligencije.
- Laboratorij “Ja sam inteligencija”.
- Neuronske mreže u Matlabu.
- Neuronske mreže u Pythonu (engleski):
- Klasificiranje teksta pomoću ;
- jednostavno .
- Neuronska mreža na .
Niz naših publikacija na tu temu
Prethodno smo objavili tečaj #neuralnamreža@tproger na neuronskim mrežama. Na ovom su popisu publikacije poredane prema redoslijedu proučavanja kako bi vam bilo lakše.

