Il libro di testo fondamentale appena tradotto di S. Khaikin (è stata tradotta la seconda edizione americana del 1999) afferma di essere l'evento del 2006 nella letteratura russa sulla neuroinformatica. Ma va notato che, sebbene la traduzione sia stata effettuata senza errori evidenti, le note a piè di pagina e i commenti dei traduttori non farebbero male a chiarire la terminologia (poiché la stessa cosa può essere chiamata in neuroinformatica, statistica e identificazione di sistemi con parole diverse, è necessario ridurre i termini a un'area o fornire elenchi di sinonimi (non tutti i lettori avranno una visione ampia). I commenti potrebbero anche riflettere i progressi nel campo delle reti neurali artificiali avvenuti dopo la pubblicazione dell'originale in lingua inglese. Spero che il libro sia richiesto e che vengano apportate modifiche quando l'edizione verrà ristampata. Inoltre, ci sono un numero significativo di errori di battitura nelle formule matematiche. Questa pagina è dedicata principalmente alla correzione degli errori di battitura. Ma va notato che non garantisco la completezza dell'elenco delle inesattezze qui fornito: ho letto il libro "in diagonale", a singhiozzo vari gradi attenzione, quindi potrei essermi perso qualcosa (o aver commesso un errore anch'io).
Capitolo 1
- P.32 secondo paragrafo. Solo qui la parola “prestazione” può essere intesa come velocità di funzionamento, potenza del computer. Più avanti nel libro, “prestazione” significherà l’accuratezza, la qualità del lavoro della rete neurale (ad esempio, a pag. 73 nel secondo paragrafo dal basso).
- P.35 p.7. "Implementabilità VLSI" è meglio tradotta non come "scalabilità", ma come "implementabilità effettiva su VLSI - circuiti integrati su larga scala".
- P.39 p.7. La parola "picco" - "emissione, impulso" nella neuroscienza in lingua russa è abbastanza spesso e abitualmente traslitterata semplicemente come "picco".
- P.49 titolo del paragrafo. Forse un termine migliore sarebbe "grafo diretto" invece di "grafo diretto".
- P.76 terzo paragrafo. Invece di un collegamento, probabilmente dovrebbe esserci un collegamento al libro di Ashby.
- P.99 conclusione 1. È inoltre necessario aggiungere il caso di contemporaneo soddisfacimento di queste stesse condizioni e con il segno "
- P.105 paragrafo 2. È necessario inserire la parola “visibile” prima di (visibile).
capitolo 2
- P.94 nota 2. Il riferimento a è molto probabilmente errato, perché Non è un libro e il titolo non gli si addice molto.
- P.122 ultimo paragrafo. Ho riso della frase “deformazione della struttura dei neuroni”: fino a quando l'evento esterno di una commozione cerebrale non sarà soddisfatto, una persona non ricorderà questo evento. Molto probabilmente, si è sostenuto che la memoria si realizza solo disconnettendo gli input sinaptici (terminali) dai tentacoli dei dendriti o passando da un tentacolo all'altro (termini dalla Fig. 1.2 a pag. 40, poiché questa figura è ben adatta per l'illustrazione) . Quelli. Il nostro cervello è vivo e in movimento.
- P.129 formula (2.39). Invece di X ci deve essere X.
- P.129 formule (2.40), (2.41), (2.44). L'apice dovrebbe essere Q invece di M.
- P.137 primo paragrafo e formula (2.61). La E dovrebbe essere in corsivo. E anche nelle formule (2.64), (2.65), (2.67), (2.68) a pagina 138.
- P.142 formula (142). Aggiungi 0 dopo la prima freccia.
- P.142 ultimo paragrafo. Prima l'ultima parola inserire "meno".
- P.147 primo paragrafo. | l|=l. Quelli. variabile l a destra dell'espressione va data in corsivo (poiché la versione del libro la confonde con una).
- P.151 formula (2.90). Inserisci nella riga superiore dopo la parentesi graffa F.
- Formula C.151 (2.91). Inserisci "a" prima N.
- C.160 ultimo paragrafo della nota. “per piccole quantità” dovrebbe essere sostituito con “per grandi quantità”.
capitolo 3
- P.173 Fig.3.1. Le variabili dovrebbero essere indicate in corsivo secondo la notazione utilizzata nel libro, perché queste variabili sono scalari.
- P.176 formule (3.5), (3.7). Deve essere w* invece di w* .
- C.176 ultima riga. Molto probabilmente è necessario fare riferimento a, sebbene questo problema possa essere considerato anche in quello specificato.
- P.179 nota a piè di pagina. Dovrebbe essere "derivata di f(w) rispetto a w"
- P.180 ultima riga prima della nota a piè di pagina. Potrebbe essere meglio prenderlo, ma il collegamento potrebbe non essere corretto.
- P.184 espressione intermedia nella riga superiore della formula (3.30). Invece di X(N) dovrebbe essere X(io)
- P.200 paragrafo dopo la formula (3.59). Ha riso della "disuguaglianza Gucci-Schwartz". Dovrebbe esserci la disuguaglianza di Cauchy-Schwarz, che è nota a tutti dal corso universitario.
- P.204 il primo paragrafo della sezione 3.10 riguarda la trasformazione di un classificatore bayesiano in un separatore lineare in un ambiente gaussiano. Questo si riferisce alla condizione che le matrici di covarianza di entrambe le classi siano identiche (sarà introdotta nella sezione a p. 207), ma quando sento la frase “ambiente gaussiano” di solito ricordo la situazione generalizzata di due distribuzioni normali con covarianza arbitraria matrici, quando Bayes non può degenerare in un separatore lineare, ma dare una superficie di divisione quadratica.
- P.206 formula (3.77). Successivamente, al posto di λ indicato nella formula, Λ verrà stampato più volte nel testo e in Fig. 3.10.
- P.216 compito 3.11. Ciò che è indicato nel limite superiore dell'importo deve essere spostato sotto il segno della somma (e il meno può essere anteposto alla somma). Anche nel paragrafo successivo a questa formula, invece di w T X ci deve essere w T X
capitolo 4
Il mio commento sul capitolo: un incubo, un principiante in reti neurali e metodi di ottimizzazione, anche dopo aver letto il capitolo più volte e ripetute prove (intenzionalmente o casualmente), è improbabile che programmi correttamente l'addestramento di una rete neurale utilizzando la backpropagation metodo. Di almeno, considerando solo gli studenti delle università tecniche provinciali, sono disposto a discuterne con una posta in gioco piuttosto alta. La presentazione ha mescolato in un mucchio sia le cose necessarie che quelle non necessarie, senza porre enfasi e complicare eccessivamente la presentazione (adottando un approccio "tutto o niente" invece di aggiungere procedure passo dopo passo). Oltre a un sacco di empirici. Perché non delineare semplicemente la metodologia per calcolare il gradiente di una funzione complessa (una rete neurale più una funzione obiettivo sul suo output e, se necessario, sulle proprietà della rete neurale), quindi, come nel capitolo 6, rimandare i lettori al gradiente metodi di ottimizzazione senza restrizioni (nel Capitolo 6 il riferimento va ai metodi di programmazione quadratica) e delinea diversi esempi storici di approcci corretti e errati all'uso dei gradienti calcolati in rete dal punto di vista della teoria dell'ottimizzazione del gradiente e della massimizzazione del tasso di convergenza (tasso di apprendimento).
Quali cose aggiuntive ti piacerebbe vedere nel capitolo (o nel libro). Innanzitutto, funzioni obiettivo diverse dai minimi quadrati, in particolare per l'addestramento di una rete di classificazione (ad esempio, la funzione di entropia incrociata). In secondo luogo, evidenziare più chiaramente la possibilità di avere una funzione obiettivo composta da più termini: utilizzando l'esempio della regolarizzazione secondo Tikhonov attraverso la minimizzazione esplicita, oltre al valore dell'errore stesso, anche del gradiente scalare quadratico dei segnali in uscita dalla rete mediante pesi delle sinapsi (lavoro congiunto di LeCun e Drucker 1991-92), utilizzando l'esempio del metodo di ricerca Flat minina di Hochreiter e Schmidhuber, o l'esempio del metodo CLearning per pulire i segnali di input della rete di Andreas Weigend et al. In terzo luogo, una descrizione più dettagliata della possibilità di calcolare le derivate seconde nella rete (lavori indicati di LeCun e Drucker, metodi elencati nella recensione). In quarto luogo, una descrizione più dettagliata dei metodi per calcolare il contenuto informativo-utilità di diversi elementi e segnali nella rete (vale a dire, determinazione del contenuto informativo degli input, possibilità di ridurre non solo le sinapsi utilizzando i metodi descritti nel libro, ma anche riducendo interi neuroni e ci sono anche molte opzioni per ridurre le sinapsi con altri metodi). In quinto luogo, c’è un’indicazione esplicita (i lettori non lo capiranno da soli) sulla possibilità di calcolare il gradiente utilizzando i segnali di ingresso della rete (per risolvere problemi inversi su reti neurali addestrate a risolvere un problema diretto per presentare il metodo CLearning). Inoltre, per questo e altri capitoli in cui si pone il compito dell'apprendimento supervisionato, descriveremo più in dettaglio l'idea delle curve di apprendimento per le reti neurali.
Capitolo 5
- P.357 dopo la formula (5.23). Più avanti in diverse pagine E può essere scritto in corsivo o in grassetto e cambiare la forma della scrittura è abbastanza casuale. Più correttamente - in corsivo, per E(F), E s (F), Mic(F), E(F,h).
- P.361 formula (5.31). Invece di pedice H ci deve essere H .
- P.363 ultimo paragrafo. "...per combinazione lineare..." invece di "...per sovrapposizione lineare...".
- P.364 formula (5.43). Rimuovere 1/λ.
- P.367 formula (5.59). σ invece di δ.
- P.369 dopo la formula (5.65). Ci deve essere di nuovo" combinazione lineare" invece di "sovrapposizione lineare".
- P.373 terza riga della formula (5.74). Inserisci una parentesi di apertura prima della seconda T io .
- P.382 formula (5.112). Al limite inferiore dell'importo aggiungere “non uguale a K".
- P.390 titolo della sezione 5.12. Nella scienza in lingua russa, invece di “regressione del kernel”, vengono solitamente utilizzati i termini “regressione non parametrica” (così viene chiamato questo metodo statistico in russo) o “regressione del kernel” (se tradotto “frontalmente”).
- P.393 formula (5.135). Inserire “...per tutti...” come in (5.139) nella pagina successiva.
- P.399 paragrafo “centrale”. "...algoritmo di clustering di K-media...”, la parola “media” non verrà più saltata.
- P.403 elenco non numerato. Gli autori traggono conclusioni troppo globali e inequivocabili da un esperimento, sebbene siano ampiamente d'accordo.
- P.404 è il primo elemento dell'elenco. Non capisco, soprattutto per quanto riguarda “l’influenza sui parametri di input”. Piuttosto che più valoreλ, minore è l'influenza dei dati in generale sulle proprietà finali del modello.
- P.408 primo paragrafo. Il collegamento a è discutibile, forse funzionerà.
- P.408 riga 6 del paragrafo 2. “funzione di base” anziché “funzione fondamentale”.
Capitolo 6
- P.431 ultima frase prima della sezione 6.4. Non ho capito la “migliorità” della scelta proposta attraverso la media campionaria (e mi sembra di aver capito bene b0 non sarà possibile).
- P.434 formula (6.35). Indice io l'ultimo X non dovrebbe esserci.
- P.435 formule non numerate nel teorema di Mercer. Al posto di ψ dovrebbe esserci φ.
- Nota a piè di pagina P.444. Il cognome Huber era stato precedentemente tradotto in russo come Huber, non Haber (ad esempio, la traduzione del suo libro durante l’URSS: Huber, “Robustezza nella statistica”).
Capitolo 7 (non completamente)
- P.459 terza riga dall'alto. La definizione del termine “algoritmo di apprendimento debole” è riportata a pagina 467 nel secondo paragrafo dall'alto.
- P.459 commi non numerati del paragrafo 2. Il termine “rete gateway” come traduzione del termine “rete di accesso” è troppo goffo, ma non esiste ancora un’altra (e buona) opzione in russo. Probabilmente sarebbe meglio usare il termine “rete di ponderazione”, che è universale sia per il caso di hard switching (moltiplicatori di 0 o 1 per il segnale controllato) sia per il controllo soft del coefficiente di attenuazione (moltiplicatori di range).
- P.463 pag.2. Rimuoviamo la particella "non" da questa frase: la dispersione dell'insieme è inferiore alla dispersione delle singole funzioni.
- P.471 prime righe. La “prestazione” (ricordiamo che “prestazione” qui è intesa non nel senso di velocità, ma nel senso di accuratezza della soluzione e generalizzazione - vedi il nostro commento a pag. 32) del metodo di amplificazione originale dipende anche dalle distribuzioni formato durante il suo funzionamento per il secondo e i successivi esperti.
- P.472 tabella 7.2 ultima riga. Deve essere F pinna ( X)=…
Bibliografia
- Molte volte le parole applicazione, approssimazione, approccio, applicato, supporto, mappatura, applicabilità, superiore sono scritte con una P.
- . Scrittura corretta I nomi di uno degli autori possono essere visti in.
- . Il cognome corretto di Müller è lo stesso del suo omonimo.
- . Primo autore: B tu ntina.
- . Rilasciato nello stesso NIPS del .
- . L'ultimo degli autori è citato correttamente.
- . Abbiamo bisogno di debolezza invece che di settimana.
- . L'ultimo autore è correttamente nominato in .
- . Primo: Landa tu.
- . Questo è un capitolo di un libro.
- . Sch ö lkopf.
- . Nel titolo - “…bia S termine". È scritto correttamente nel duplicato.
- . Nel titolo - "…gamm SU".
- . Ripetere.

In abbiamo descritto di più proprietà semplici neuroni formali. Abbiamo parlato del fatto che il sommatore di soglia riproduce più accuratamente la natura di un singolo picco e il sommatore lineare consente di simulare la risposta di un neurone, costituita da una serie di impulsi. Hanno dimostrato che il valore all'uscita di un sommatore lineare può essere paragonato alla frequenza dei picchi evocati di un neurone reale. Considereremo ora le proprietà di base possedute da tali neuroni formali.
Filtro Hebb
Nel seguito faremo spesso riferimento ai modelli di reti neurali. In linea di principio, quasi tutti i concetti fondamentali della teoria delle reti neurali sono direttamente correlati alla struttura del cervello reale. L'uomo, di fronte a determinati problemi, ha inventato molti progetti interessanti di reti neurali. L'evoluzione, attraversando tutti i possibili meccanismi neurali, ha selezionato tutto ciò che si è rivelato utile. Non dovrebbe sorprendere che per molti modelli inventati dall'uomo si possano trovare chiari prototipi biologici. Poiché la nostra narrazione non mira a presentare in alcun dettaglio la teoria delle reti neurali, ne toccheremo solo le principali punti generali necessario per descrivere le idee principali. Per una comprensione più approfondita consiglio vivamente di rivolgersi alla letteratura specializzata. Per me, il miglior libro di testo sulle reti neurali è “Neural Networks. Corso completo" (Khaikin, 2006).Molti modelli di reti neurali si basano sulla nota regola di apprendimento Hebbiana. Fu proposto dal fisiologo Donald Hebb nel 1949 (Hebb, 1949). In un’interpretazione un po’ libera, ha un significato molto semplice: le connessioni tra neuroni che si attivano insieme dovrebbero essere rafforzate, le connessioni tra neuroni che si attivano in modo indipendente dovrebbero indebolirsi.
Lo stato di uscita del sommatore lineare può essere scritto:
Se iniziamo i valori iniziali dei pesi con valori piccoli e forniamo diverse immagini come input, nulla ci impedisce di provare ad addestrare questo neurone secondo la regola di Hebb:
Dove N– passo temporale discreto, – parametro della velocità di apprendimento.
Con questa procedura aumentiamo il peso degli input a cui viene applicato il segnale, ma lo facciamo tanto più fortemente quanto più attiva è la reazione del neurone di apprendimento stesso. Se non c’è reazione, l’apprendimento non avviene.
È vero, tali pesi aumenteranno senza limiti, quindi è possibile applicare la normalizzazione per stabilizzarli. Ad esempio, dividi per la lunghezza del vettore ottenuto dai “nuovi” pesi sinaptici.
Con tale apprendimento, i pesi vengono ridistribuiti tra le sinapsi. È più facile comprendere l'essenza della ridistribuzione se si monitora la variazione dei pesi in due passaggi. Innanzitutto, quando un neurone è attivo, le sinapsi che ricevono un segnale ricevono un supplemento. I pesi delle sinapsi senza segnale rimangono invariati. La normalizzazione generale riduce quindi i pesi di tutte le sinapsi. Ma allo stesso tempo, le sinapsi senza segnali perdono rispetto al loro valore precedente e le sinapsi con segnali ridistribuiscono queste perdite tra loro.
La regola di Hebb non è altro che un'implementazione del metodo di discesa del gradiente lungo la superficie di errore. In sostanza costringiamo il neurone ad adattarsi ai segnali forniti, spostando ogni volta i suoi pesi nella direzione opposta all'errore, cioè nella direzione dell'antigradiente. Affinché la discesa in pendenza ci conduca all'estremo locale senza oltrepassarlo, la velocità di discesa deve essere piuttosto bassa. Che nell’apprendimento hebbiano si tiene conto dell’esiguità del parametro.
L'esiguità del parametro del tasso di apprendimento ci consente di riscrivere la formula precedente come una serie in:
Se scartiamo i termini del secondo ordine e superiori, otteniamo la regola di apprendimento di Oja (Oja, 1982):
L'additivo positivo è responsabile dell'apprendimento hebbiano e l'additivo negativo è responsabile della stabilità generale. La registrazione in questa forma consente di sentire come tale allenamento possa essere implementato in un ambiente analogico senza l'uso di calcoli, operando solo con connessioni positive e negative.
Quindi, un allenamento così estremamente semplice ha una proprietà straordinaria. Se riduciamo gradualmente la velocità di apprendimento, i pesi delle sinapsi del neurone addestrato convergeranno a valori tali che il suo output inizierà a corrispondere alla prima componente principale, che si otterrebbe se applicassimo le opportune procedure di analisi delle componenti principali a i dati forniti. Questo disegno è chiamato filtro Hebb.
Ad esempio, diamo un'immagine pixel all'input di un neurone, cioè associamo un punto dell'immagine a ciascuna sinapsi del neurone. Forniremo solo due immagini all'input del neurone: immagini di linee verticali e orizzontali che passano attraverso il centro. Una fase di apprendimento: un'immagine, una linea, orizzontale o verticale. Se viene calcolata la media di queste immagini, ottieni una croce. Ma il risultato dell’apprendimento non sarà simile alla media. Questa sarà una delle linee. Quello che apparirà più spesso nelle immagini inviate. Il neurone non evidenzierà la media o l'intersezione, ma quei punti che più spesso si verificano insieme. Se le immagini sono più complesse, il risultato potrebbe non essere così chiaro. Ma questa sarà sempre la componente principale.
L'addestramento di un neurone porta al fatto che una determinata immagine viene evidenziata (filtrata) sulle sue scale. Quando viene dato un nuovo segnale, più accurata è la corrispondenza tra il segnale e le impostazioni del peso, maggiore è la risposta del neurone. Un neurone addestrato può essere chiamato neurone rivelatore. In questo caso, l'immagine descritta dalle sue scale viene solitamente chiamata stimolo caratteristico.
Componenti principali
L’idea stessa del metodo delle componenti principali è semplice e ingegnosa. Diciamo che abbiamo una sequenza di eventi. Descriviamo ciascuno di essi attraverso la sua influenza sui sensori con cui percepiamo il mondo. Diciamo che abbiamo sensori che descrivono caratteristiche. Tutti gli eventi per noi sono descritti da vettori di dimensione. Ciascuna componente di tale vettore indica il valore del corrispondente attributo th. Insieme formano una variabile casuale X . Possiamo rappresentare questi eventi come punti nello spazio bidimensionale, dove gli assi saranno i segni che osserviamo.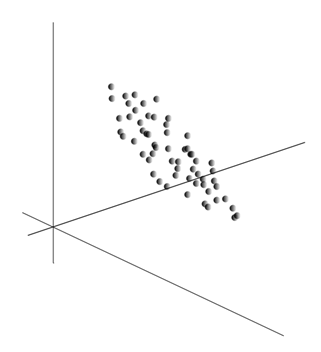
La media dei valori fornisce l'aspettativa matematica di una variabile casuale X, indicato come E( X). Se centriamo i dati in modo che E( X)=0, allora la nuvola di punti sarà concentrata attorno all'origine.
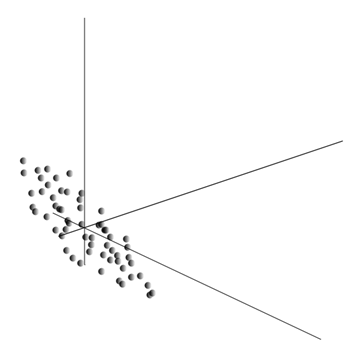
Questa nuvola può essere allungata in qualsiasi direzione. Avendo provato di tutto direzioni possibili, possiamo trovarne uno lungo il quale la dispersione dei dati sarà massima.
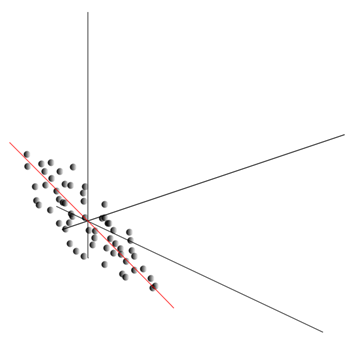
Quindi, questa direzione corrisponde alla prima componente principale. La componente principale stessa è determinata da un vettore unitario proveniente dall'origine e coincidente con questa direzione.
Successivamente possiamo trovare un'altra direzione, perpendicolare alla prima componente, tale che lungo di essa anche la dispersione sia massima tra tutte le direzioni perpendicolari. Dopo averlo trovato, otteniamo il secondo componente. Successivamente possiamo continuare la ricerca, ponendo la condizione che si debba cercare tra le direzioni perpendicolari alle componenti già trovate. Se le coordinate iniziali fossero linearmente indipendenti, allora possiamo farlo una volta fino al termine della dimensione dello spazio. Pertanto, otterremo componenti reciprocamente ortogonali, ordinate in base alla percentuale di varianza nei dati che spiegano.
Naturalmente, le componenti principali risultanti riflettono i modelli interni dei nostri dati. Ma ci sono caratteristiche più semplici che descrivono anche l’essenza dei modelli esistenti.
Supponiamo di avere n eventi in totale. Ogni evento è descritto da un vettore. Componenti di questo vettore:
Per ogni segno, puoi scrivere come si è manifestato in ciascuno degli eventi:
Per due caratteristiche qualsiasi su cui si basa la descrizione è possibile calcolare un valore che mostra il grado della loro manifestazione congiunta. Questa quantità è chiamata covarianza: 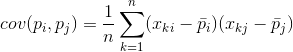
Mostra come le deviazioni dal valore medio di una delle caratteristiche coincidono nella manifestazione con deviazioni simili di un'altra caratteristica. Se i valori medi delle caratteristiche sono pari a zero, la covarianza assume la forma: 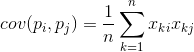
Se correggiamo la covarianza per le deviazioni standard inerenti alle caratteristiche, otteniamo un coefficiente di correlazione lineare, chiamato anche coefficiente di correlazione di Pearson: ![]()
Il coefficiente di correlazione ha una proprietà notevole. Assume valori da -1 a 1. Inoltre, 1 significa proporzionalità diretta di due quantità e -1 indica la loro relazione lineare inversa.
Da tutte le covarianze a coppie di caratteristiche, possiamo creare una matrice di covarianza che, come puoi facilmente vedere, è l'aspettativa matematica del prodotto: ![]()
Risulta quindi che per i componenti principali vale quanto segue:
Cioè, i componenti principali, o, come vengono anche chiamati, fattori, sono autovettori della matrice di correlazione. Corrispondono agli autovalori. Allo stesso tempo, di più autovalore, maggiore è la percentuale di varianza spiegata da questo fattore.
Conoscere tutte le componenti principali, per ogni evento che è una realizzazione X
, possiamo scrivere le sue proiezioni sulle componenti principali:
È quindi possibile rappresentare tutti gli eventi iniziali in nuove coordinate, le coordinate delle componenti principali: 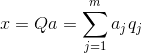
In generale si distingue tra il procedimento di ricerca delle componenti principali e il procedimento di ricerca di una base a partire dai fattori e la sua successiva rotazione, che facilita l'interpretazione dei fattori, ma poiché tali procedimenti sono ideologicamente vicini e danno un risultato simile, chiamerà analisi di entrambi i fattori.
Dietro la procedura abbastanza semplice dell'analisi fattoriale si nasconde un significato molto profondo. Il fatto è che se lo spazio delle caratteristiche iniziali è uno spazio osservabile, allora i fattori sono caratteristiche che, sebbene descrivano le proprietà del mondo circostante, nel caso generale (se non coincidono con le caratteristiche osservate) sono entità nascoste. Cioè, la procedura formale dell'analisi fattoriale ci consente di passare dai fenomeni osservabili alla rilevazione di fenomeni, sebbene direttamente invisibili, ma comunque esistenti nel mondo circostante.
Si può presumere che il nostro cervello utilizzi attivamente la selezione dei fattori come una delle procedure per comprendere il mondo che ci circonda. Identificando i fattori, abbiamo l'opportunità di costruire nuove descrizioni di ciò che ci sta accadendo. La base di queste nuove descrizioni è l'espressione in ciò che sta accadendo di quei fenomeni che corrispondono ai fattori identificati.
Lasciatemi spiegare un po' l'essenza dei fattori a livello quotidiano. Diciamo che sei un responsabile delle risorse umane. Molte persone vengono da te e per ognuna di loro compili un determinato modulo in cui registri vari dati osservabili sul visitatore. Dopo aver rivisto i tuoi appunti in seguito, potresti scoprire che alcuni grafici hanno una certa relazione. Ad esempio, i tagli di capelli degli uomini saranno in media più corti di quelli delle donne. Molto probabilmente, incontrerai persone calve solo tra gli uomini e solo le donne indosseranno il rossetto. Se applicato ai dati personali analisi fattoriale, allora il genere sarà uno dei fattori che spiegano diversi modelli contemporaneamente. Ma l'analisi fattoriale consente di trovare tutti i fattori che spiegano le correlazioni in un set di dati. Ciò significa che oltre al fattore genere, che possiamo osservare, ce ne saranno anche altri, compresi fattori impliciti e non osservabili. E se il genere appare esplicitamente nel questionario, allora è un altro fattore importante resterà tra le righe. Valutando la capacità delle persone di esprimere i propri pensieri, valutando il loro successo professionale, analizzando i voti dei diplomi e segni simili, arriverai alla conclusione che esiste valutazione complessiva intelligenza umana, che non è esplicitamente registrata nel questionario, ma che ne spiega molti dei punti. La valutazione dell’intelligence è quello che è fattore nascosto, una componente principale con un elevato effetto esplicativo. Non osserviamo esplicitamente questa componente, ma registriamo i segni ad essa correlati. Avendo esperienza di vita, possiamo inconsciamente farci un'idea dell'intelligenza del nostro interlocutore in base a determinate caratteristiche. La procedura che il nostro cervello utilizza in questo caso è, in sostanza, l'analisi fattoriale. Osservando come appaiono insieme determinati fenomeni, il cervello, utilizzando una procedura formale, identifica i fattori come riflesso di modelli statistici stabili inerenti al mondo che ci circonda.
Identificazione di un insieme di fattori
Abbiamo mostrato come il filtro Hebb seleziona il primo componente principale. Si scopre che con l'aiuto delle reti neurali puoi facilmente ottenere non solo il primo, ma anche tutti gli altri componenti. Ciò può essere fatto, ad esempio, nel modo seguente. Supponiamo di avere funzionalità di input. Prendiamo i neuroni lineari, dove .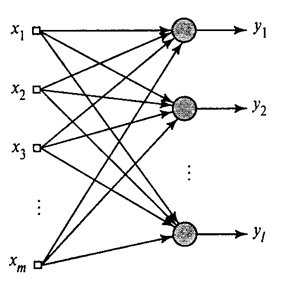
Algoritmo di Hebb generalizzato(Khaikin, 2006)
Addestreremo il primo neurone come filtro Hebb in modo che selezioni il primo componente principale. Ma addestreremo ogni neurone successivo su un segnale dal quale escluderemo l'influenza di tutti i componenti precedenti.
Attività neuronale durante un passo N definito come 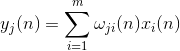
E la correzione ai pesi sinottici è simile
dove da 1 a , e da 1 a .
Per tutti i neuroni, questo sembra un apprendimento simile a un filtro Hebb. L’unica differenza è che ogni neurone successivo non vede l’intero segnale, ma solo ciò che i neuroni precedenti “non hanno visto”. Questo principio si chiama rivalutazione. In realtà ripristiniamo il segnale originale da un insieme limitato di componenti e costringiamo il neurone successivo a vedere solo il resto, la differenza tra il segnale originale e quello ripristinato. Questo algoritmo è chiamato algoritmo di Hebb generalizzato.
Ciò che non è del tutto positivo nell’algoritmo di Hebb generalizzato è che è di natura troppo “computazionale”. I neuroni devono essere ordinati e la loro attività deve essere contata in modo rigorosamente sequenziale. Ciò è poco compatibile con i principi di funzionamento della corteccia cerebrale, dove ogni neurone, pur interagendo con gli altri, opera in modo autonomo, e dove non esiste un “processore centrale” chiaramente definito che determinerebbe la sequenza complessiva degli eventi. Per questi motivi, gli algoritmi chiamati algoritmi di decorrelazione sembrano un po’ più attraenti.
Immaginiamo di avere due strati di neuroni Z 1 e Z 2. L'attività dei neuroni nel primo strato forma una certa immagine, che viene proiettata lungo gli assoni allo strato successivo.
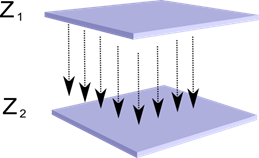
Proiezione di uno strato su un altro
Ora immagina che ciascun neurone del secondo strato abbia connessioni sinaptiche con tutti gli assoni provenienti dal primo strato, se rientrano nei confini di un certo quartiere di questo neurone (figura sotto). Gli assoni che entrano in tale area formano il campo recettivo del neurone. Il campo recettivo di un neurone è quel frammento di attività generale che è a sua disposizione per l'osservazione. Tutto il resto semplicemente non esiste per questo neurone.
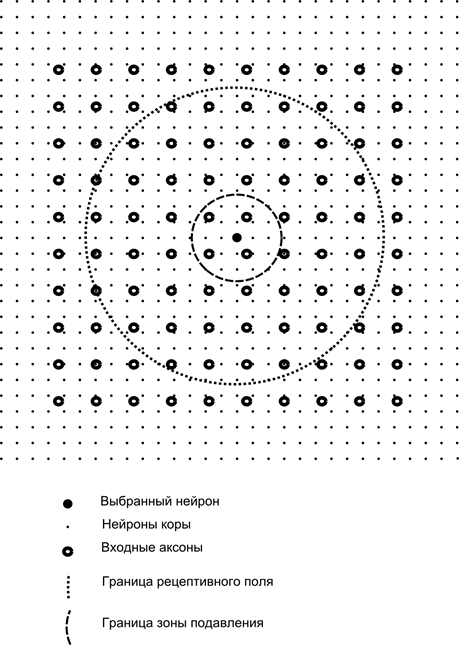
Oltre al campo recettivo del neurone, introdurremo un'area leggermente più piccola, che chiameremo zona di soppressione. Colleghiamo ogni neurone con i suoi vicini che rientrano in questa zona. Tali connessioni sono chiamate laterali o, secondo la terminologia accettata in biologia, laterali. Rendiamo inibitorie le connessioni laterali, cioè riduciamo l'attività dei neuroni. La logica del loro lavoro è che un neurone attivo inibisce l'attività di tutti quei neuroni che rientrano nella sua zona di inibizione.
Le connessioni eccitatorie e inibitorie possono essere distribuite rigorosamente con tutti gli assoni o neuroni entro i confini delle aree corrispondenti, oppure possono essere specificate in modo casuale, ad esempio, con un riempimento denso di un certo centro e una diminuzione esponenziale della densità delle connessioni come una si allontana da esso. Il riempimento continuo è più facile da modellare; la distribuzione casuale è più anatomica dal punto di vista dell'organizzazione delle connessioni nella corteccia reale.
La funzione di attività del neurone può essere scritta:
dove è l'attività finale, è l'insieme di assoni che cadono nell'area ricettiva del neurone selezionato, è l'insieme di neuroni nella zona di soppressione di cui cade il neurone selezionato, ed è la forza dell'inibizione laterale corrispondente, che assume valori negativi.
Questa funzione di attività è ricorsiva, poiché l'attività dei neuroni risulta dipendere l'una dall'altra. Ciò porta al fatto che i calcoli pratici vengono eseguiti in modo iterativo.
L'addestramento dei pesi sinaptici viene eseguito in modo simile al filtro Hebb:
I pesi laterali apprendono secondo la regola anti-Hebbiana, aumentando l’inibizione tra neuroni “simili”:
L’essenza di questo disegno è che l’apprendimento hebbiano dovrebbe portare all’assegnazione sulle scale di valori del neurone corrispondenti al primo fattore principale caratteristico dei dati forniti. Ma un neurone è in grado di apprendere in direzione di qualsiasi fattore solo se è attivo. Quando un neurone inizia a secernere un fattore e, di conseguenza, a rispondere ad esso, inizia a bloccare l'attività dei neuroni che cadono nella sua zona di soppressione. Se più neuroni competono per l'attivazione, la concorrenza reciproca porta al fatto che vince il neurone più forte, sopprimendo tutti gli altri. Gli altri neuroni non hanno altra scelta che apprendere in quei momenti in cui non ci sono vicini nelle vicinanze. attività elevata. Si verifica così una decorrelazione, cioè ogni neurone all'interno dell'area, la cui dimensione è determinata dalla dimensione della zona di soppressione, inizia ad evidenziare il proprio fattore, ortogonale a tutti gli altri. Questo algoritmo è chiamato algoritmo di estrazione adattiva delle componenti principali (APEX) (Kung S., Diamantaras K.I., 1990).
L'idea dell'inibizione laterale è vicina nello spirito a quella ben nota modelli diversi il principio “winner takes all”, che consente anche la decorrelazione dell’area in cui si cerca il vincitore. Questo principio viene utilizzato, ad esempio, nel neocognitron di Fukushima, le mappe auto-organizzanti di Kohanen, e questo principio viene utilizzato anche per allenare la nota memoria temporale gerarchica di Jeff Hawkins.
Puoi determinare il vincitore semplice confronto attività dei neuroni. Ma una tale ricerca, facilmente implementabile su un computer, è in qualche modo incoerente con le analogie con la corteccia reale. Ma se ci si prefigge l'obiettivo di fare tutto a livello di interazione tra i neuroni senza coinvolgere algoritmi esterni, allora lo stesso risultato può essere ottenuto se, oltre all'inibizione laterale dei vicini, il neurone ha un feedback positivo che lo eccita. Questa tecnica per trovare un vincitore viene utilizzata, ad esempio, nelle reti di risonanza adattativa di Grossberg.
Se l'ideologia della rete neurale lo consente, è molto conveniente utilizzare la regola del "vincitore prende tutto", poiché cercare l'attività massima è molto più semplice che calcolare iterativamente le attività tenendo conto dell'inibizione reciproca.
È ora di finire questa parte. Si è rivelato piuttosto lungo, ma non volevo davvero dividere la narrazione che era collegata nel significato. Non sorprenderti di KDPV, questa immagine per me è stata associata sia all'intelligenza artificiale che al fattore principale.
Questo articolo contiene materiali, principalmente in russo, per uno studio di base sulle reti neurali artificiali.
Rete neurale artificiale, o ANN - modello matematico, così come la sua incarnazione software o hardware, costruita sul principio di organizzazione e funzionamento delle reti neurali biologiche - reti cellule nervose organismo vivente. La scienza delle reti neurali esiste da molto tempo, ma è proprio in connessione con ultime realizzazioni Con il progresso scientifico e tecnologico, quest'area sta cominciando a guadagnare popolarità.
Libri
Iniziamo la selezione con modo classico studiare - con l'aiuto dei libri. Abbiamo selezionato libri in lingua russa con un gran numero di esempi:
- F. Wasserman, Tecnologia neuroinformatica: teoria e pratica. 1992
Il libro espone in una forma accessibile al pubblico le basi della costruzione di neurocomputer. Viene descritta la struttura delle reti neurali e vari algoritmi per la loro configurazione. Capitoli separati sono dedicati all'implementazione delle reti neurali. - S. Khaikin, Reti neurali: corso completo. 2006
Qui vengono discussi i principali paradigmi delle reti neurali artificiali. Il materiale presentato contiene una rigorosa giustificazione matematica per tutti i paradigmi delle reti neurali, è illustrato con esempi, descrizioni di esperimenti informatici e contiene molti problemi pratici, nonché un'ampia bibliografia.
D. Forsythe, Visione artificiale. Approccio moderno. 2004
La visione artificiale è una delle aree più popolari in questa fase di sviluppo delle tecnologie informatiche digitali globali. È richiesto nell'industria manifatturiera, nel controllo robot, nell'automazione dei processi, nelle applicazioni mediche e militari, nella sorveglianza satellitare e nelle applicazioni per personal computer come il recupero di immagini digitali.
video
Non c'è niente di più accessibile e comprensibile dell'apprendimento visivo tramite video:
- Per capire cos'è l'apprendimento automatico in generale, guarda qui queste due lezioni da Yandex ShAD.
- introduzione nei principi di base della progettazione delle reti neurali: ottimo per continuare la tua introduzione alle reti neurali.
- Corso di lezioni sul tema “Computer Vision” presso l'Università Statale di Mosca Computing Machinery. La visione artificiale è la teoria e la tecnologia per la creazione di sistemi artificiali che rilevano e classificano oggetti in immagini e video. Queste lezioni possono essere considerate un'introduzione a questa scienza interessante e complessa.
Risorse didattiche e link utili
- Portale dell'intelligenza artificiale.
- Laboratorio “Io sono intelligenza”.
- Reti neurali in Matlab.
- Reti neurali in Python (inglese):
- Classificare il testo utilizzando ;
- Semplice .
- Rete neurale attiva.
Una serie di nostre pubblicazioni sull'argomento
Abbiamo già pubblicato un corso #neuralnetwork@tproger sulle reti neurali. In questo elenco le pubblicazioni sono disposte in ordine di studio per comodità dell'utente.

