Tikko tulkotā S. Haikina fundamentālā mācību grāmata (tika iztulkots 1999. gada otrais izdevums Amerikā) pilnībā pretendē uz 2006. gada notikumu krievu neiroinformātikas literatūrā. Taču jāatzīmē, ka, lai arī tulkojums tika veikts bez acīmredzamām kļūdām, tulkotāju zemsvītras piezīmes-komentāri nenāktu par ļaunu, lai precizētu terminoloģiju (tā kā neiroinformātikā, statistikā un sistēmu identificēšanā vienu un to pašu var saukt ar dažādiem vārdiem, ir nepieciešams vai nu terminus reducēt uz vienu jomu, vai dot sinonīmu sarakstus - ne visiem lasītājiem būs plašs skatījums). Komentāri varētu atspoguļot arī progresu mākslīgo neironu tīklu jomā, kas noticis kopš angļu oriģināla publicēšanas. Ceru, ka grāmata būs pieprasīta un izdevuma pārpublicēšanas brīdī tiks veiktas izmaiņas. Turklāt matemātiskajās formulās ir ievērojams skaits drukas kļūdu. Šī lapa galvenokārt ir veltīta drukas kļūdu labošanai. Bet jāpiebilst, ka es negarantēju šeit sniegtā neprecizitāšu saraksta pilnīgumu - grāmatu lasīju "pa diagonāli", iesākumā dažādas pakāpes vērīgums, lai es varētu kaut ko palaist garām (vai pats kļūdīties).
1. nodaļa
- lpp.32 otrā rindkopa. Tikai šeit vārdu "veiktspēja" var saprast kā darba ātrumu, kalkulatora jaudu. Tālāk grāmatā "veiktspēja" nozīmēs precizitāti, neironu tīkla kvalitāti (piemēram, 73. lpp. otrajā rindkopā no apakšas).
- S.35 7. lpp. "VLSI Implementability" ir labāk tulkots nevis kā "mērogojamība", bet gan kā "efektīva implementējamība uz VLSI — ļoti lielas integrālās shēmas".
- 39.lpp.7.lpp. Vārds "smaile" - "izgrūšana, impulss" krievu neirozinātnē bieži un parasti tiek vienkārši transliterēts kā "smaile".
- P.49 rindkopas nosaukums. Varbūt labāks termins būtu "virzīts grafiks", nevis "virzītais grafiks".
- C.76 trešā daļa. Saites vietā, iespējams, vajadzētu būt saitei uz Ešbija grāmatu.
- P.99 secinājums 1. Jāpievieno arī gadījums, kad vienlaicīgi tiek izpildīti vienādi nosacījumi un ar zīmi "
- C.105 2. punkts. Pirms (redzams) ievietojiet vārdu "redzams".
2. nodaļa
- P.94 2. zemsvītras piezīme. Atsauce uz, visticamāk, ir nepareiza, jo Tā nav grāmata, un nosaukums īsti neder.
- P.122 pēdējā rindkopa. Viņš pasmējās par frāzi "neironu struktūras deformācija": kamēr ārējais smadzeņu satricinājuma notikums nav piemērots, cilvēks šo notikumu neatcerēsies. Visticamāk, tika apgalvots, ka atmiņa tiek realizēta, tikai atvienojot sinaptiskos ievadus (galus) no dendrītu taustekļiem vai pārslēdzoties no viena tausteļa uz otru (termini no 1.2. līdz 40. lpp., jo šis skaitlis ir labi piemērots ilustrācijai). Tie. mūsu smadzenes ir dzīvas un kustas.
- C.129 formula (2.39). Tā vietā X vajadzētu būt X.
- C.129 formulas (2.40), (2.41), (2.44). Virsrakstam jābūt q tā vietā m.
- C.137 pirmā daļa un formula (2.61). E ir jābūt slīprakstā. Un arī formulās (2.64), (2.65), (2.67), (2.68) 138. lpp.
- P.142 formula (142). Pievienojiet 0 aiz pirmās bultiņas.
- C.142 pēdējā rindkopa. Pirms tam pēdējais vārds ievietot mīnusu.
- C.147 pirmā rindkopa. | L|=l. Tie. mainīgs l izteiciena labajā pusē jādod slīprakstā (jo variants grāmatā to jauc ar vienību).
- P.151 formula (2.90). Augšējā līnijā, pēc cirtainā lencēja, ievietojiet F.
- C.151 formula (2.91). Pirms tam ievietojiet "at". N.
- C.160 pēdējā rindkopa zemsvītras piezīmē. "ar nelielu daudzumu" aizstāj ar "ar lielu daudzumu".
3. nodaļa
- P.173 3.1.att. Mainīgie lielumi jānorāda slīprakstā saskaņā ar grāmatā pieņemto apzīmējumu, jo šie mainīgie ir skalāri.
- P.176 formulas (3.5), (3.7). Jābūt w* tā vietā w* .
- C.176 pēdējā rindiņa. Visticamāk, jums ir jāatsaucas, lai gan šo jautājumu var izskatīt arī norādītajā.
- P.179 zemsvītras piezīme. Jābūt "f(w) atvasinājums attiecībā pret w"
- P.180 pēdējā rindiņa pirms zemsvītras piezīmes. Tā vietā var būt labāk izmantot, un saite var būt nepareiza.
- C.184 starpposma izteiksme formulas (3.30.) augšējā rindā. Tā vietā x(n) vajadzētu būt x(i)
- C.200 rindkopa aiz formulas (3.59.). Smējās par "Gucci-Schwartz nevienlīdzību". Ir jābūt labi zināmajai Košī nevienlīdzībai no torņa universitātes kursa.
- C.204. 3.10. sadaļas pirmā rindkopa ir par Bajesa klasifikatora pārveidošanu par lineāro separatoru Gausa vidē. Tas attiecas uz nosacījumu, ka abu klašu kovariācijas matricas ir vienādas (tiks iepazīstināts sadaļā 207. lpp.), bet, kad es saku "Gausa vide", es parasti atceros divu normālu sadalījumu vispārinātu situāciju ar patvaļīgām kovariācijas matricām, kad Bayes var nevis deģenerēties par lineāru atdalītāju, bet dot kvadrātveida atdalīšanas virsmu.
- C.206 formula (3.77). Tālāk formulā norādītā λ vietā tekstā un 3.10. attēlā vairākas reizes tiks iespiests Λ.
- P.216 uzdevums 3.11. Summas augšējā robežā norādītais ir jāpārvieto zem summas zīmes (un mīnusu var izņemt pirms summas). Arī rindkopā pēc šīs formulas, vietā w T x vajadzētu būt w T x
4. nodaļa
Mans komentārs par nodaļu: murgs, iesācējs neironu tīklos un optimizācijas metodēs, pat pēc vairākkārtējas nodaļas lasīšanas un atkārtotām pārbaudēm (mērķtiecīgi vai iedurot), diez vai spēs pareizi ieprogrammēt neironu tīklu apmācību, izmantojot backpropagation metodi. Autors vismaz, ņemot vērā, tikai provinču tehnisko universitāšu studenti ir gatavi par to strīdēties ar diezgan lielām likmēm. Prezentācija sajauca kaudzē gan nepieciešamās, gan nesvarīgās lietas, neuzsverot un nesarežģot prezentāciju (ejot ar pieeju "visu vai neko", nevis soli pa solim pievienojot procedūras). Plus daudz empīrisma. Kāpēc gan vienkārši ieskicēt sarežģītas funkcijas gradienta aprēķināšanas paņēmienu (neironu tīkls plus objektīva funkcija pār tā izvadi un, ja nepieciešams, pār neironu tīkla īpašībām), pēc tam, kā 6.nodaļā, lasītājus novirzīt uz gradienta optimizācijas metodēm bez ierobežojumiem (6.nodaļā atsauce attiecas uz kvadrātiskās programmēšanas metodēm), un sniegt vairākus vēsturiskus piemērus, izmantojot gradienta gradienta pieeju no tīkla optimizācijas viedokļa. teoriju un maksimizējot konverģences ātrumu (mācīšanās ātrumu).
Ko jūs vēlētos redzēt nodaļā (vai grāmatā) papildus. Pirmkārt, mērķfunkcijas, kas nav mazāko kvadrātu metode, īpaši klasifikatora tīkla apmācībai (piemēram, krustentropijas funkcija). Otrkārt, skaidrāka izvēle iespējai izmantot objektīvu funkciju, kas sastāv no vairākiem terminiem: izmantojot regularizācijas piemēru pēc Tihonova ar nepārprotamu minimizēšanu, papildus kļūdas faktiskajai vērtībai, arī tīkla izejas signālu gradienta skalārais kvadrāts pēc sinapses svariem (LeCun un Drucker 1991-92 kopīgs darbs, izmantojot Flāmīdhūbera vai Flāmīdhūberes vai 1992. gada Flamidhūberes piemēru). izmantojot Andreas Weigend ar līdzautoriem CLearning metodes piemēru tīkla ievades signālu tīrīšanai. Treškārt, sīkāks apraksts par otro atvasinājumu aprēķināšanas iespēju tīklā (norādītie LeCun un Drucker darbi, pārskatā uzskaitītās metodes). Ceturtkārt, detalizētāks dažādu elementu un signālu informācijas satura-lietderības aprēķināšanas metožu apraksts tīklā (t.i., ievades informācijas satura noteikšana, iespēja samazināt ne tikai sinapses, izmantojot grāmatā aprakstītās metodes, bet arī veselu neironu samazināšanu, un ir arī virkne citu sinapšu samazināšanas metožu). Piektkārt, skaidra norāde (galu galā lasītāji paši to neizdomās) par spēju aprēķināt gradientu, izmantojot tīkla ievades signālus (lai atrisinātu apgrieztās problēmas par neironu tīkliem, kas apmācīti risināt tiešu problēmu, prezentēt CLearning metodi). Turklāt šajā un citās nodaļās, kur rodas uzdevums mācīties kopā ar skolotāju, sīkāk aprakstiet ideju par mācīšanās līknēm neironu tīkliem.
5. nodaļa
- P.357 aiz formulas (5.23). Tālāk uz dažām lapām E var norādīt slīprakstā vai treknrakstā, un apzīmējuma formas izmaiņas ir diezgan nesistemātiskas. Pareizāk, slīprakstā, par E(F), E s (F), E c (F), E(F,h).
- C.361 formula (5.31). Indeksa vietā H vajadzētu būt H .
- P.363 pēdējā rindkopa. "...lineāra kombinācija..." vietā "...lineāra superpozīcija...".
- C.364 formula (5.43). Noņemiet 1/λ.
- P.367 formula (5.59). σ δ vietā.
- P.369 aiz formulas (5.65). Vajadzētu būt vēlreiz lineāra kombinācija"lineāra superpozīcijas vietā".
- P.373 formulas trešā rinda (5.74). Pirms otrā ievietojiet atvēršanas kronšteinu t i .
- C.382 formula (5.112). Summas apakšējā robežā pievienojiet "nav vienāds ar k".
- C.390 5.12. sadaļas nosaukums. Krievvalodīgajā zinātnē "kodolregresijas" vietā parasti tiek lietoti termini "neparametriskā regresija" (tā šo statistikas metodi sauc krieviski) vai "kodolregresija" (ja tulko "pierē").
- S.393 formula (5.135). Nākamajā lapā ievietojiet "...visiem..." tāpat kā (5.139.).
- P.399 "vidējā" rindkopa. "...algoritms klasterēšanai pēc k-vidējs…”, tad vārds "vidēji" vairs netiks izlaists.
- C.403 nesakārtots saraksts. Pārāk globālus un nepārprotamus secinājumus autori izdara no viena eksperimenta, lai gan daudzējādā ziņā piekrītu.
- P.404 pirmais vienums sarakstā. Nesapratu, īpaši attiecībā uz "ietekmi uz ievades parametriem". Drīzāk nekā lielāka vērtībaλ, jo mazāka ir datu ietekme kopumā uz modeļa galīgajām īpašībām.
- P.408 pirmā rindkopa. Apšaubāma atsauce uz , varbūt piemērota .
- С.408 2. punkta 6. rindiņa "pamatfunkcija" vietā "pamatfunkcija".
6. nodaļa
- P.431 pēdējais teikums pirms 6.4. sadaļas. Es nesapratu piedāvātās izvēles “labāko” no izlases vidējā rādītāja (un šķiet, ka tajā pašā laikā iegūstu pareizo izvēli b 0 nebūs iespējams).
- S.434 formula (6.35). Rādītājs i pēdējo x nevajadzētu būt.
- P.435 nenumurētas formulas Mersera teorēmā. ψ vietā jābūt φ.
- P.444 zemsvītras piezīme. Uzvārdu Hūbers krieviski mēdza tulkot kā Hūbers, nevis Gābers (piemēram, viņa grāmatas tulkojums padomju laikā: Hūbers "Robustness statistikā").
7. nodaļa (nav pilnīga)
- P.459 trešā rinda no augšas. Termina "vājš mācīšanās algoritms" interpretācija ir sniegta 467. lpp. otrajā rindkopā no augšas.
- C.459 2. punktā nenosauktie apakšpunkti. Termins "vārtu tīkls" kā jēdziena "vārtu tīkls" tulkojums ir pārāk neveikls, taču citu (un tajā pašā laikā labu) variantu krievu valodā nav. Iespējams, labāk būtu lietot terminu "svēršanas tīkls", kas ir universāls gan stingras pārslēgšanas gadījumā (reizinātāji 0 vai 1 kontrolētam signālam), gan vājuma koeficienta mīkstai kontrolei (reizinātāji no diapazona ).
- S.463 2. lpp. Mēs noņemam no šī teikuma daļiņu "ne" - ansambļa dispersija ir mazāka par atsevišķu funkciju dispersiju.
- P.471 pirmās rindas. Sākotnējās pastiprināšanas metodes "veiktspēja" (atgādinām, ka "veiktspēja-veiktspēja" šeit tiek saprasta nevis ātruma, bet risinājuma precizitātes un vispārinājuma nozīmē - skat. mūsu komentāru 32. lpp.) arī ir atkarīga no tās darbības laikā izveidotajiem sadalījumiem otrajam un nākamajiem ekspertiem.
- C.472 tabulas 7.2 pēdējā rinda. Jābūt F fin( x)=…
Bibliogrāfija
- Vairākas reizes vārdi pielietojums, tuvināšana, pieeja, pielietojums, atbalsts, kartēšana, piemērojamība, augšējais ir rakstīti no viena lpp.
- . Pareiza rakstīšana viena autora vārdus var redzēt .
- . Pareizais Mullera uzvārds ir kā viņa vārdabrāļa uzvārds.
- . Pirmais autors - B u ntine.
- . Izlaists tajā pašā NIPS kā .
- . Pēdējais no autoriem ir pareizi nosaukts .
- . Mums vajag vāju, nevis nedēļu.
- . Pēdējais autors ir pareizi nosaukts .
- . Pirmā - Landa u.
- . Šī ir nodaļa grāmatā.
- . Sch ö lkopf.
- . Nosaukumā - "... bia s termins". Dubultā tas ir rakstīts pareizi.
- . Nosaukumā - "…gamm ieslēgts".
- . Atkārtojiet.

Mēs esam aprakstījuši visvairāk vienkāršas īpašības formālie neironi. Mēs runājām par to, ka sliekšņa summators precīzāk atveido viena smaile, un lineārais summators ļauj simulēt neirona reakciju, kas sastāv no virknes impulsu. Tika parādīts, ka vērtību lineārā summatora izejā var salīdzināt ar reāla neirona inducēto smaiļu biežumu. Tagad mēs apskatīsim galvenās īpašības, kas piemīt šādiem formāliem neironiem.
Hebb filtrs
Turpmāk mēs bieži atsauksimies uz neironu tīklu modeļiem. Principā gandrīz visi neironu tīklu teorijas pamatjēdzieni ir tieši saistīti ar reālo smadzeņu struktūru. Cilvēks, saskaroties ar noteiktiem uzdevumiem, nāca klajā ar daudziem interesantiem neironu tīklu projektiem. Evolūcija, šķirojot visus iespējamos neironu mehānismus, atlasīja visu, kas tai izrādījās noderīgs. Nav jābrīnās, ka tik daudziem cilvēku izgudrotiem modeļiem var atrast skaidrus bioloģiskos prototipus. Tā kā mūsu stāstījuma mērķis nav detalizēti izklāstīt neironu tīklu teoriju, mēs pieskarsimies tikai visvairāk. kopīgi mirkļi nepieciešams, lai aprakstītu galvenās idejas. Lai iegūtu dziļāku izpratni, es ļoti iesaku atsaukties uz specializēto literatūru. Man labākā pamācība par neironu tīkliem ir Saimons Heikins “Neironu tīkli. Pilns kurss” (Khaikin, 2006).Daudzi neironu tīklu modeļi ir balstīti uz labi zināmo Hebbian mācīšanās noteikumu. To 1949. gadā ierosināja fiziologs Donalds Hebs (Hebb, 1949). Nedaudz brīvā interpretācijā tam ir ļoti vienkārša nozīme: jānostiprina kopā uzliesmojošo neironu savienojumi, jānovājinās neironu savienojumi, kas uzliesmo neatkarīgi.
Lineārā summatora izvades stāvokli var uzrakstīt:
Ja mēs inicializējam svaru sākotnējās vērtības ar mazām vērtībām un kā ievadi piegādājam dažādus attēlus, nekas neliedz mums mēģināt apmācīt šo neironu saskaņā ar Heba likumu:
Kur n ir diskrēts laika posms, ir mācīšanās ātruma parametrs.
Ar šo procedūru mēs palielinām to ieeju svaru, kurām tiek pielietots signāls, bet mēs to darām, jo spēcīgāka, jo aktīvāka ir paša apmācītā neirona reakcija. Ja nav reakcijas, tad nav arī mācīšanās.
Tiesa, šādi svari augs bezgalīgi, tāpēc stabilizēšanai var piemērot normalizāciju. Piemēram, daliet ar vektora garumu, kas iegūts no "jaunajiem" sinaptiskajiem svariem.
Ar šādu mācīšanos svari tiek pārdalīti starp sinapsēm. Pārdales būtību ir vieglāk saprast, ja sekojat līdzi svaru izmaiņām divos soļos. Pirmkārt, kad neirons ir aktīvs, tās sinapses, kas saņem signālu, saņem piedevu. Sinapses bez signāla svari paliek nemainīgi. Tad vispārējā normalizācija samazina visu sinapšu svarus. Bet tajā pašā laikā sinapses bez signāliem zaudē salīdzinājumā ar to iepriekšējo vērtību, un sinapses ar signāliem pārdala šos zaudējumus savā starpā.
Heba noteikums ir nekas vairāk kā gradienta nolaišanās metodes ieviešana kļūdas virsmā. Faktiski mēs piespiežam neironu pielāgoties dotajiem signāliem, katru reizi novirzot tā svarus virzienā, kas ir pretējs kļūdai, tas ir, antigradienta virzienā. Lai gradienta nolaišanās mūs novestu pie lokālas ekstremitātes, nepārkāpjot to, nolaišanās ātrumam jābūt pietiekami mazam. Kas Hebbian mācībās tiek ņemts vērā, ņemot vērā parametra mazumu.
Mācību ātruma parametra mazums ļauj pārrakstīt iepriekšējo formulu kā sēriju:
Ja mēs atmetam otrās kārtas un augstākus terminus, tad iegūstam Oja mācīšanās likumu (Oja, 1982):
Pozitīvs papildinājums ir atbildīgs par hebiešu mācīšanos, bet negatīvs - par vispārējo stabilitāti. Ieraksts šādā formā ļauj sajust, kā šādu apmācību var realizēt analogā vidē, neizmantojot aprēķinus, darbojoties tikai ar pozitīviem un negatīviem sakariem.
Tātad šādai ārkārtīgi vienkāršai apmācībai ir pārsteidzoša īpašība. Ja mēs pakāpeniski samazināsim mācīšanās ātrumu, tad apmācītā neirona sinapses svari saplūdīs līdz tādām vērtībām, ka tā izvade sāks atbilst pirmajam galvenajam komponentam, kas tiktu iegūts, ja ievades datiem piemērotu atbilstošas galveno komponentu analīzes procedūras. Šo dizainu sauc par Hebb filtru.
Piemēram, pielietosim pikseļa attēlu neirona ievadei, tas ir, salīdzināsim vienu attēla punktu ar katru neirona sinapses. Mēs ievadīsim tikai divus attēlus neirona ievadei - vertikālu un horizontālu līniju attēlus, kas iet caur centru. Viens mācīšanās solis – viens attēls, viena līnija, horizontāli vai vertikāli. Ja šiem attēliem tiek aprēķināts vidējais rādītājs, jūs saņemat krustiņu. Bet treniņu rezultāts nebūs līdzīgs vidējam. Šī būs viena no līnijām. Tāda, kas iesūtītajos attēlos būs biežāk sastopama. Neirons izcels nevis vidējo vērtību vai krustojumu, bet gan tos punktus, kas visbiežāk sastopami kopā. Ja attēli ir sarežģītāki, rezultāts var nebūt tik skaidrs. Bet tā vienmēr būs galvenā sastāvdaļa.
Neirona apmācība noved pie tā, ka noteikts attēls tiek izcelts (filtrēts) tā mērogos. Kad tiek dots jauns signāls, jo precīzāka atbilst signāla un svara iestatījumiem, jo augstāka ir neirona reakcija. Apmācītu neironu var saukt par detektorneironu. Šajā gadījumā attēlu, ko raksturo tā svari, parasti sauc par raksturīgu stimulu.
Galvenās sastāvdaļas
Pati galveno komponentu analīzes ideja ir vienkārša un ģeniāla. Pieņemsim, ka mums ir notikumu secība. Mēs aprakstām katru no tiem, izmantojot tā ietekmi uz sensoriem, ar kuriem mēs uztveram pasauli. Pieņemsim, ka mums ir sensori, kas apraksta funkcijas . Visi notikumi mums ir aprakstīti ar dimensiju vektoriem. Katra šāda vektora sastāvdaļa norāda uz atbilstošās i-tās pazīmes vērtību. Kopā tie veido nejaušu lielumu X . Mēs varam attēlot šos notikumus kā punktus -dimensiju telpā, kur mūsu novērotās zīmes darbosies kā asis.
Vērtību vidējā aprēķināšana dod nejaušā mainīgā matemātisko cerību X, apzīmēts kā E( X). Ja mēs centrējam datus tā, lai E( X)=0, tad punktu mākonis tiks koncentrēts ap izcelsmi.
Šis mākonis var tikt izstiepts jebkurā virzienā. Izmēģinājis visu iespējamie virzieni, mēs varam atrast tādu, kurā datu dispersija būs maksimāla.
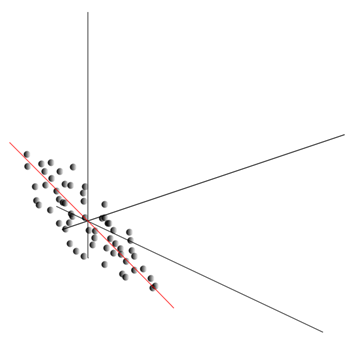
Tātad šis virziens atbilst pirmajam galvenajam komponentam. Pašu galveno komponentu nosaka vienības vektors, kas iziet no sākuma un sakrīt ar šo virzienu.
Tālāk mēs varam atrast citu virzienu, kas ir perpendikulārs pirmajai komponentei, lai gar to dispersija būtu arī maksimālā starp visiem perpendikulārajiem virzieniem. Atrodot to, mēs iegūstam otro komponentu. Pēc tam varam turpināt meklēšanu, ievērojot nosacījumu, ka jāmeklē starp virzieniem, kas ir perpendikulāri jau atrastajiem komponentiem. Ja sākotnējās koordinātas bija lineāri neatkarīgas, mēs to varam izdarīt vienu reizi, līdz telpas dimensija beidzas. Tādējādi mēs iegūstam savstarpēji ortogonālus komponentus, kas sakārtoti pēc to izskaidrotās datu dispersijas procentuālās daļas.
Protams, iegūtie galvenie komponenti atspoguļo mūsu datu iekšējās likumsakarības. Bet ir vienkāršāki raksturlielumi, kas arī raksturo esošo modeļu būtību.
Pieņemsim, ka mums kopumā ir n notikumu. Katrs notikums ir aprakstīts ar vektoru. Šī vektora sastāvdaļas ir:
Katrai zīmei varat pierakstīt, kā tā izpaudās katrā notikumā:
Jebkurām divām pazīmēm, uz kurām ir balstīts apraksts, var aprēķināt vērtību, kas parāda to kopīgās izpausmes pakāpi. Šo vērtību sauc par kovariāciju: 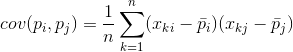
Tas parāda, kā novirzes no vienas zīmes vidējās vērtības izpausmē sakrīt ar līdzīgām otras zīmes novirzēm. Ja pazīmju vidējās vērtības ir vienādas ar nulli, tad kovariācija izpaužas šādā formā: 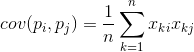
Ja izlabojam kovariāciju pazīmēm raksturīgajām standarta novirzēm, tad iegūstam lineāro korelācijas koeficientu, ko sauc arī par Pīrsona korelācijas koeficientu: ![]()
Korelācijas koeficientam ir ievērojama īpašība. Tas aizņem vērtības no -1 līdz 1. Turklāt 1 nozīmē abu vērtību tiešu proporcionalitāti, bet -1 norāda to apgriezto lineāro attiecību.
No visām pazīmju kovariācijām pa pāriem varat izveidot kovariācijas matricu, kas, kā jūs viegli varat redzēt, ir produkta matemātiskā cerība: ![]()
Tātad izrādās, ka galvenajām sastāvdaļām tā ir:
Tas ir, galvenie komponenti vai, kā tos sauc arī, faktori ir korelācijas matricas īpašvektori. Tie atbilst viņu pašu numuriem. Tajā pašā laikā, jo vairāk savu numuru, jo lielāka dispersijas procentuālā daļa izskaidro šo faktoru.
Zinot visas galvenās sastāvdaļas katram pasākumam, kas ir īstenošana X
, mēs varam pierakstīt tās prognozes uz galvenajām sastāvdaļām:
Tādējādi ir iespējams attēlot visus sākotnējos notikumus jaunās koordinātēs, galveno komponentu koordinātēs: 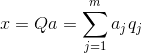
Kopumā tiek izšķirta principiālo komponentu atrašanas procedūra un faktoru bāzes atrašanas un tās sekojošās rotācijas procedūra, kas atvieglo faktoru interpretāciju, taču, tā kā šīs procedūras ir ideoloģiski tuvas un dod līdzīgu rezultātu, tad abas nosauksim par faktoru analīzi.
Aiz diezgan vienkāršas faktoru analīzes procedūras slēpjas ļoti dziļa nozīme. Fakts ir tāds, ka, ja sākotnējo pazīmju telpa ir novērotā telpa, tad faktori ir pazīmes, kas, lai arī raksturo apkārtējās pasaules īpašības, bet vispārīgā gadījumā (ja tās nesakrīt ar novērotajām pazīmēm) ir slēptās entītijas. Tas ir, formālā faktoru analīzes procedūra ļauj mums pāriet no novērojamām parādībām uz parādību noteikšanu, lai arī tieši neredzamu, bet tomēr pastāvošu apkārtējā pasaulē.
Var pieņemt, ka mūsu smadzenes aktīvi izmanto faktoru atlasi kā vienu no procedūrām apkārtējās pasaules izzināšanai. Izolējot faktorus, mēs iegūstam iespēju veidot jaunus aprakstus par to, kas ar mums notiek. Šo jauno aprakstu pamatā ir to parādību izpausme notiekošajā, kas atbilst izvēlētajiem faktoriem.
Ļaujiet man nedaudz paskaidrot faktoru būtību mājsaimniecības līmenī. Pieņemsim, ka esat personāla vadītājs. Pie jums nāk ļoti daudz cilvēku, un katram jūs aizpildāt noteiktu formu, kurā pierakstāt dažādus novērojamos datus par apmeklētāju. Pārskatot savas piezīmes, varat atklāt, ka dažiem grafikiem ir noteikta saistība. Piemēram, vīriešu matu griezumi vidēji būs īsāki nekā sieviešu. Visticamāk, ka plikpaurus satiksi tikai vīriešu vidū, un lūpas krāsos tikai sievietes. Ja tas attiecas uz personas datiem faktoru analīze, tad tieši dzimums būs viens no faktoriem, kas izskaidro vairākus modeļus vienlaikus. Taču faktoru analīze ļauj atrast visus faktorus, kas izskaidro korelācijas datu kopā. Tas nozīmē, ka papildus dzimuma faktoram, ko varam novērot, izcelsies citi, tostarp netieši, nenovērojami faktori. Un, ja anketā skaidri norādīts dzimums, tad otrs svarīgs faktors palikt starp rindām. Vērtējot cilvēku spēju izteikt savas domas, izvērtējot karjeras panākumus, analizējot atzīmes diplomā un līdzīgas pazīmes, nonāksiet pie secinājuma, ka ir vispārējs cilvēka intelekta novērtējums, kas anketā nav skaidri fiksēts, bet kas izskaidro daudzus tā punktus. Inteliģences novērtējums ir slēptais faktors, galvenā sastāvdaļa ar augstu skaidrojošo efektu. Acīmredzot mēs šo komponentu neievērojam, bet piefiksējam ar to saistītās pazīmes. Ņemot dzīves pieredzi, mēs varam neapzināti veidot priekšstatu par sarunu biedra intelektu, pamatojoties uz noteiktām pazīmēm. Procedūra, ko mūsu smadzenes izmanto šajā gadījumā, faktiski ir faktoru analīze. Vērojot, kā atsevišķas parādības izpaužas kopā, smadzenes, izmantojot formālu procedūru, identificē faktorus kā stabilu statistisko modeļu atspulgu, kas raksturīgs apkārtējai pasaulei.
Faktoru kopas izvēle
Mēs esam parādījuši, kā Hebb filtrs ekstrahē pirmo galveno komponentu. Izrādās, ka ar neironu tīklu palīdzību var viegli iegūt ne tikai pirmo, bet arī visas pārējās sastāvdaļas. To var izdarīt, piemēram, šādā veidā. Pieņemsim, ka mums ir ievades funkcijas. Ņemsim lineāros neironus, kur .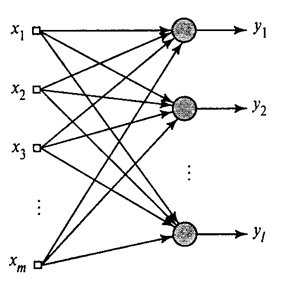
Vispārināts Hebb algoritms(Haikins, 2006)
Mēs apmācīsim pirmo neironu kā Heba filtru, lai tas iegūtu pirmo galveno komponentu. Bet mēs apmācīsim katru nākamo neironu ar signālu, no kura mēs izslēdzam visu iepriekšējo komponentu ietekmi.
Neironu aktivitāte vienā solī n definēts kā 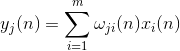
Un sinoptisko svaru korekcija kā
kur no 1 līdz , un no 1 līdz .
Visiem neironiem tas izskatās kā mācīšanās, līdzīgi kā Heba filtram. Vienīgā atšķirība ir tā, ka katrs nākamais neirons neredz visu signālu, bet tikai to, ko iepriekšējie neironi "neredzēja". Šo principu sauc par pārvērtēšanu. Faktiski mēs atjaunojam sākotnējo signālu, izmantojot ierobežotu komponentu kopumu, un piespiežam nākamo neironu redzēt tikai atlikušo daļu, atšķirību starp sākotnējo signālu un atjaunoto. Šo algoritmu sauc par vispārināto Heba algoritmu.
Vispārinātajā Hebb algoritmā nav gluži labi tas, ka tam ir pārāk "skaitļošanas" raksturs. Neironi ir jāpasūta, un to aktivitātes aprēķins jāveic stingri secīgi. Tas nav īpaši savienojams ar smadzeņu garozas principiem, kur katrs neirons, lai arī mijiedarbojas ar citiem, darbojas autonomi un kur nav izteikta "centrālā procesora", kas noteiktu kopējo notikumu secību. Šo iemeslu dēļ algoritmi, ko sauc par dekorelācijas algoritmiem, izskatās nedaudz pievilcīgāki.
Iedomājieties, ka mums ir divi neironu slāņi Z 1 un Z 2 . Pirmā slāņa neironu darbība veido noteiktu attēlu, kas tiek projicēts pa aksoniem uz nākamo slāni.
Viena slāņa projekcija uz otru
Tagad iedomājieties, ka katram otrā slāņa neironam ir sinaptiski savienojumi ar visiem aksoniem, kas nāk no pirmā slāņa, ja tie ietilpst noteiktas šī neirona apkārtnes robežās (attēls zemāk). Aksoni, kas nonāk šādā zonā, veido neirona uztverošo lauku. Neirona uztverošais lauks ir tas vispārējās aktivitātes fragments, kas tam ir pieejams novērošanai. Viss pārējais šim neironam vienkārši neeksistē.
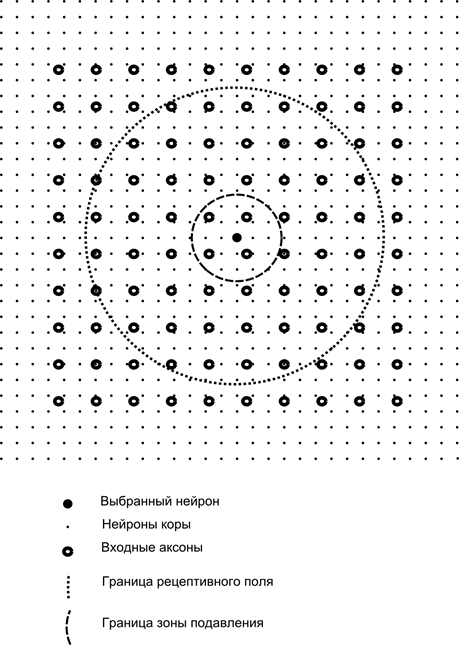
Papildus neirona uztverošajam laukam mēs ieviešam nedaudz mazāka izmēra apgabalu, ko mēs sauksim par nomākšanas zonu. Savienosim katru neironu ar kaimiņiem, kas ietilpst šajā zonā. Šādus savienojumus sauc par laterāliem vai, ievērojot bioloģijā pieņemto terminoloģiju, par laterālu. Padarīsim sānu savienojumus inhibējošus, tas ir, pazemina neironu aktivitāti. Viņu darba loģika ir tāda, ka aktīvs neirons inhibē visu to neironu darbību, kas ietilpst tā inhibīcijas zonā.
Uzbudinošie un inhibējošie savienojumi var tikt stingri sadalīti ar visiem aksoniem vai neironiem atbilstošo apgabalu robežās, vai arī tos var iestatīt nejauši, piemēram, ar blīvu noteikta centra piepildījumu un eksponenciālu savienojumu blīvuma samazināšanos, attālinoties no tā. Cieto pildījumu ir vieglāk modelēt, nejaušs sadalījums ir anatomiskāks attiecībā uz savienojumu organizēšanu reālajā garozā.
Neironu aktivitātes funkciju var uzrakstīt šādi:
kur ir galīgā aktivitāte, ir aksonu kopums, kas ietilpst izvēlētā neirona uztveršanas zonā, ir neironu kopums, kuru nomākšanas zonā ietilpst izvēlētais neirons, ir atbilstošās sānu inhibīcijas stiprums, kam ir negatīvas vērtības.
Šāda aktivitātes funkcija ir rekursīva, jo neironu darbība izrādās viena no otras atkarīga. Tas noved pie tā, ka praktiskie aprēķini tiek veikti iteratīvi.
Sinaptisko svaru apmācība tiek veikta līdzīgi kā Hebb filtram:
Sānu svars tiek apmācīts saskaņā ar anti-Hebbian likumu, palielinot inhibīciju starp "līdzīgiem" neironiem:
Šī dizaina būtība ir tāda, ka Hebbian mācīšanās rezultātā neironu skalās tiek piešķirtas vērtības, kas atbilst pirmajam galvenajam faktoram, kas raksturīgs sniegtajiem datiem. Bet neirons spēj mācīties jebkura faktora virzienā tikai tad, ja tas ir aktīvs. Kad neirons sāk atbrīvot faktoru un attiecīgi reaģēt uz to, tas sāk bloķēt neironu darbību, kas ietilpst tā nomākšanas zonā. Ja vairāki neironi apgalvo, ka ir aktivizēti, tad savstarpējā konkurence noved pie tā, ka uzvar spēcīgākais neirons, vienlaikus apspiežot visus pārējos. Citiem neironiem neatliek nekas cits kā mācīties tajos brīžos, kad tuvumā nav neviena kaimiņa augsta aktivitāte. Tādējādi notiek dekorelācija, tas ir, katrs neirons reģionā, kura lielumu nosaka slāpēšanas zonas lielums, sāk piešķirt savu faktoru, kas ir ortogonāls visiem pārējiem. Šo algoritmu sauc par adaptīvās galvenās komponentes ekstrakcijas (APEX) algoritmu (Kung S., Diamantaras K.I., 1990).
Ideja par sānu kavēšanu pēc būtības ir tuva plaši pazīstamajai dažādi modeļi uzvarētājs ņem visu, kas ļauj arī dekorēt apgabalu, kurā uzvarētājs tiek meklēts. Šis princips tiek izmantots, piemēram, Fukušimas neokognitronā, Kohanena pašorganizējošās kartēs, un šis princips tiek izmantots arī Džefa Hokinsa labi zināmās hierarhiskās temporālās atmiņas mācīšanai.
Jūs varat noteikt uzvarētāju vienkāršs salīdzinājums neironu darbība. Bet šāds uzskaitījums, kas ir viegli realizējams datorā, nedaudz neatbilst analoģijām ar reālu garozu. Bet, ja izvirzām sev mērķi visu darīt neironu mijiedarbības līmenī, neiesaistot ārējus algoritmus, tad tādu pašu rezultātu var sasniegt, ja papildus sānu kaimiņu kavēšanai neironam ir pozitīva atgriezeniskā saite, kas to vēl vairāk uzbudina. Šāds paņēmiens uzvarētāja atrašanai tiek izmantots, piemēram, Grossbergas adaptīvās rezonanses tīklos.
Ja neironu tīkla ideoloģija to pieļauj, tad ir ļoti ērti izmantot noteikumu “uzvarētājs ņem visu”, jo ir daudz vieglāk meklēt maksimālo aktivitāti, nekā iteratīvi aprēķināt aktivitātes, ņemot vērā savstarpējo kavēšanu.
Ir pienācis laiks beigt šo daļu. Tas izrādījās pietiekami ilgs, bet es patiešām negribēju sadalīt stāstījumu, kas bija saistīts ar nozīmi. Nebrīnieties par KDPV, šī bilde man asociējās vienlaikus ar mākslīgo intelektu un ar galveno faktoru.
Šajā rakstā ir materiāli - galvenokārt krievu valodā - mākslīgo neironu tīklu pamatpētījumam.
Mākslīgais neironu tīkls jeb ANN - matemātiskais modelis, kā arī tā programmatūras vai aparatūras ieviešana, kas veidota pēc bioloģisko neironu tīklu - tīklu organizācijas un funkcionēšanas principa nervu šūnas dzīvs organisms. Zinātne par neironu tīkliem pastāv jau ilgu laiku, taču tā ir tieši saistīta ar jaunākie sasniegumi Zinātnes un tehnoloģiju progresa rezultātā šī joma sāk iegūt popularitāti.
Grāmatas
Sāksim ar kolekciju klasisks veids mācīties - ar grāmatu palīdzību. Mēs esam atlasījuši krievu valodas grāmatas ar lielu skaitu piemēru:
- F. Wasserman, Neirodatoru inženierija: teorija un prakse. 1992. gads
Grāmatā ir izklāstīti neirodatoru veidošanas pamati publiskā formā. Aprakstīta neironu tīklu struktūra un dažādi to regulēšanas algoritmi. Atsevišķas nodaļas ir veltītas neironu tīklu ieviešanai. - S. Khaikin, Neironu tīkli: Pabeigts kurss. 2006. gads
Šeit tiek aplūkotas galvenās mākslīgo neironu tīklu paradigmas. Iesniegtais materiāls satur visu neironu tīklu paradigmu stingru matemātisku pamatojumu, ir ilustrēts ar piemēriem, datoreksperimentu aprakstu, satur virkni praktiskie uzdevumi kā arī plaša bibliogrāfija.
D. Forsaits, Computer Vision. Mūsdienīga pieeja. 2004. gads
Datorredze ir viena no vispieprasītākajām jomām šajā globālo digitālo datortehnoloģiju attīstības posmā. Tas ir nepieciešams ražošanā, robotu vadīšanā, procesu automatizācijā, medicīnas un militārajos lietojumos, satelītnovērošanā un personālajos datoros, piemēram, digitālo attēlu meklēšanā.
Video
Nav nekā pieejamāka un saprotamāka par vizuālo mācīšanos, izmantojot video:
- Lai saprastu, kas vispār ir mašīnmācība, skatiet šeit. šīs divas lekcijas no ShaD Yandex.
- Ievads neironu tīklu projektēšanas pamatprincipiem — lieliski piemērots neironu tīklu izpētes turpināšanai.
- Lekciju kurss par tēmu "Datorvīzija" no VMK MSU. Datorredze ir teorija un tehnoloģija mākslīgu sistēmu izveidei, kas atklāj un klasificē objektus attēlos un video. Šīs lekcijas var attiecināt uz ievadu šajā interesantajā un sarežģītajā zinātnē.
Izglītības resursi un noderīgas saites
- Mākslīgā intelekta portāls.
- Laboratorija "Es esmu intelekts".
- Neironu tīkli programmā Matlab.
- Neironu tīkli Python (angļu valodā):
- Teksta klasifikācija ar ;
- Vienkāršs .
- Neironu tīkls ieslēgts.
Mūsu publikāciju sērija par šo tēmu
Mēs jau esam publicējuši kursu #[aizsargāts ar e-pastu] ar neironu tīkliem. Šajā sarakstā jūsu ērtībai publikācijas ir sakārtotas mācību secībā.

