Gudri matemātiķi un statistiķi nāca klajā ar ticamāku rādītāju, lai gan nedaudz citam mērķim - vidējā lineārā novirze. Šis rādītājs raksturo datu kopas vērtību izkliedes mēru ap to vidējo vērtību.
Lai parādītu datu izkliedes mēru, vispirms jāizlemj, pret ko šī izkliede tiks aprēķināta – parasti tā ir vidējā vērtība. Tālāk jums jāaprēķina, cik tālu analizētās datu kopas vērtības ir no vidējās. Skaidrs, ka katra vērtība atbilst noteiktai novirzes vērtībai, bet mūs interesē kopējais novērtējums, kas aptver visu populāciju. Tāpēc vidējo novirzi aprēķina, izmantojot parasto vidējo aritmētisko formulu. Bet! Bet, lai aprēķinātu noviržu vidējo lielumu, tās vispirms ir jāsaskaita. Un, ja mēs saskaitām pozitīvos un negatīvos skaitļus, tie viens otru izslēgs un to summai būs nulle. Lai no tā izvairītos, visas novirzes tiek ņemtas modulo, tas ir, visi negatīvie skaitļi kļūst pozitīvi. Tagad vidējā novirze parādīs vispārinātu vērtību izplatības mērījumu. Rezultātā vidējā lineārā novirze tiks aprēķināta, izmantojot formulu:
a- vidējā lineārā novirze,
x– analizētais rādītājs ar domuzīmi virs – rādītāja vidējā vērtība,
n– vērtību skaits analizētajā datu kopā,
Ceru, ka summēšanas operators nevienu nenobiedēs.
Vidējā lineārā novirze, kas aprēķināta, izmantojot norādīto formulu, atspoguļo vidējo absolūto novirzi no konkrētās populācijas vidējās vērtības.

Attēlā sarkanā līnija ir vidējā vērtība. Katra novērojuma novirzes no vidējā ir norādītas ar mazām bultiņām. Tie tiek ņemti modulo un summēti. Tad viss tiek dalīts ar vērtību skaitu.
Lai pabeigtu attēlu, mums jāsniedz piemērs. Teiksim, ir uzņēmums, kas ražo spraudeņus lāpstām. Katram griezumam jābūt 1,5 metrus garam, bet, vēl svarīgāk, tiem visiem jābūt vienādiem vai atbilstoši vismaz, plus mīnus 5 cm Tomēr neuzmanīgi strādnieki vai nu nozāģēja 1,2 m vai 1,8 m. Vasaras iedzīvotāji ir neapmierināti. Uzņēmuma direktors nolēma veikt spraudeņu garuma statistisko analīzi. Es atlasīju 10 gabalus un izmērīju to garumu, atradu vidējo un aprēķināju vidējo lineāro novirzi. Vidējais izrādījās tieši tas, kas vajadzīgs - 1,5 m. Bet vidējā lineārā novirze bija 0,16 m. Tātad sanāk, ka katrs cirtiens ir garāks vai īsāks nekā nepieciešams vidēji par 16 cm. Ir par ko runāt ar strādnieki. Patiesībā es neesmu redzējis reālu šī indikatora izmantošanu, tāpēc es pats izdomāju piemēru. Taču statistikā ir šāds rādītājs.
Izkliede
Tāpat kā vidējā lineārā novirze, arī dispersija atspoguļo datu izplatības apmēru ap vidējo vērtību.
Formula dispersijas aprēķināšanai izskatās šādi:
 (variāciju sērijām (svērtā dispersija))
(variāciju sērijām (svērtā dispersija))
 (negrupētiem datiem (vienkārša dispersija))
(negrupētiem datiem (vienkārša dispersija))
kur: σ 2 – dispersija, Sji– analizējam kvadrātveida rādītāju (pazīmes vērtību), – rādītāja vidējo vērtību, f i – vērtību skaitu analizētajā datu kopā.
Izkliede ir noviržu vidējais kvadrāts.
Vispirms aprēķina vidējo vērtību, pēc tam ņem starpību starp katru sākotnējo un vidējo vērtību, kvadrātā, reizina ar atbilstošās atribūta vērtības biežumu, pievieno un pēc tam dala ar vērtību skaitu populācijā.
Tomēr iekšā tīrā formā, piemēram, vidējais aritmētiskais vai indekss, dispersija netiek izmantota. Tas drīzāk ir palīg- un starpposma rādītājs, ko izmanto cita veida statistiskai analīzei.
Vienkāršots dispersijas aprēķināšanas veids
![]()
Standarta novirze
Lai izmantotu dispersiju datu analīzei, tiek ņemta dispersijas kvadrātsakne. Izrādās t.s standarta novirze.

Starp citu, standarta novirzi sauc arī par sigmu - no grieķu burta, kas to apzīmē.
Standartnovirze, protams, raksturo arī datu izkliedes mēru, taču tagad (atšķirībā no dispersijas) to var salīdzināt ar sākotnējiem datiem. Parasti vidējie kvadrātiskie mēri statistikā sniedz precīzākus rezultātus nekā lineārie. Tāpēc vidējais standarta novirze ir precīzāks datu izkliedes mērījums nekā lineārā vidējā novirze.
$X$. Sākumā atcerēsimies šādu definīciju:
1. definīcija
Populācija- nejauši izvēlētu noteikta veida objektu kopums, pār kuriem tiek veikti novērojumi, lai iegūtu konkrētas gadījuma lieluma vērtības, kas tiek veikti konstantos apstākļos, pētot vienu noteikta veida gadījuma lielumu.
2. definīcija
Vispārējā dispersija- populācijas varianta vērtību kvadrātu noviržu no vidējās vērtības aritmētiskais vidējais.
Ļaujiet opcijas $x_1,\ x_2,\dots ,x_k$ vērtībām attiecīgi būt $n_1,\ n_2,\dots ,n_k$. Tad vispārējo dispersiju aprēķina, izmantojot formulu:
Apsvērsim īpašs gadījums. Ļaujiet visām opcijām $x_1,\ x_2,\dots ,x_k$ atšķirties. Šajā gadījumā $n_1,\ n_2,\dots ,n_k=1$. Mēs atklājam, ka šajā gadījumā vispārējo dispersiju aprēķina, izmantojot formulu:
Šis jēdziens ir saistīts arī ar vispārējās standartnovirzes jēdzienu.
3. definīcija
Vispārējā standarta novirze
\[(\sigma )_g=\sqrt(D_g)\]
Izlases dispersija
Ļaujiet mums dot izlases populāciju attiecībā uz nejaušu lielumu $X$. Sākumā atcerēsimies šādu definīciju:
4. definīcija
Izlases populācija-- daļa no atlasītajiem objektiem no vispārējās populācijas.
5. definīcija
Izlases dispersija- izlases kopas vērtību vidējais aritmētiskais.
Ļaujiet opcijas $x_1,\ x_2,\dots ,x_k$ vērtībām attiecīgi būt $n_1,\ n_2,\dots ,n_k$. Pēc tam izlases dispersiju aprēķina, izmantojot formulu:
Apskatīsim īpašu gadījumu. Ļaujiet visām opcijām $x_1,\ x_2,\dots ,x_k$ atšķirties. Šajā gadījumā $n_1,\ n_2,\dots ,n_k=1$. Mēs atklājam, ka šajā gadījumā izlases dispersiju aprēķina, izmantojot formulu:
Ar šo jēdzienu ir saistīts arī izlases standartnovirzes jēdziens.
6. definīcija
Parauga standarta novirze-- kvadrātsakne no vispārējās dispersijas:
\[(\sigma )_в=\sqrt(D_в)\]
Izlabota dispersija
Lai atrastu laboto dispersiju $S^2$, izlases dispersija jāreizina ar daļu $\frac(n)(n-1)$, tas ir
Šis jēdziens ir saistīts arī ar koriģētās standarta novirzes jēdzienu, kas atrodams pēc formulas:
Gadījumā, ja variantu vērtības nav diskrētas, bet attēlo intervālus, tad vispārīgo vai izlases dispersiju aprēķināšanas formulās par $x_i$ vērtību tiek uzskatīta intervāla vidus vērtība. kuram pieder $x_i.$.
Problēmas piemērs, lai atrastu dispersiju un standarta novirzi
1. piemērs
Izlases populāciju nosaka šāda sadalījuma tabula:
1. attēls.
Ļaujiet mums atrast tai izlases dispersiju, izlases standartnovirzi, koriģēto dispersiju un koriģēto standartnovirzi.
Lai atrisinātu šo problēmu, vispirms izveidojam aprēķinu tabulu:
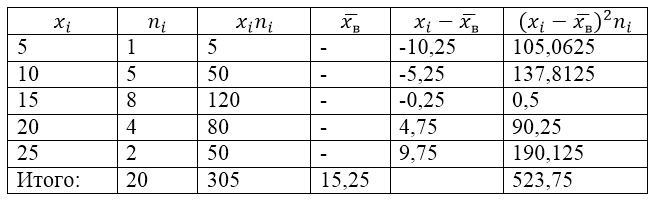
2. attēls.
Vērtību $\overline(x_в)$ (izlases vidējā vērtība) tabulā atrod pēc formulas:
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15,25\]
Atradīsim izlases dispersiju, izmantojot formulu:
Standartnovirzes paraugs:
\[(\sigma )_в=\sqrt(D_в)\apmēram 5,12\]
Labotā dispersija:
\[(S^2=\frac(n)(n-1)D)_в=\frac(20)(19)\cdot 26,1875\aptuveni 27,57\]
Koriģēta standarta novirze.
Standarta novirze(sinonīmi: standarta novirze, standarta novirze, kvadrātveida novirze; saistītie termini: standarta novirze, standarta izplatība) - varbūtības teorijā un statistikā visizplatītākais nejaušā lieluma vērtību izkliedes rādītājs attiecībā pret tā matemātisko cerību. Ar ierobežotiem vērtību paraugu masīviem matemātiskās cerības vietā tiek izmantots paraugu kopas vidējais aritmētiskais.
Enciklopēdisks YouTube
-
1 / 5
Standartnovirze tiek mērīta paša nejaušā lieluma mērvienībās un tiek izmantota, aprēķinot vidējā aritmētiskā standarta kļūdu, konstruējot ticamības intervālus, statistiski pārbaudot hipotēzes, mērot lineāro sakarību starp nejaušajiem mainīgajiem. Definēta kā nejauša lieluma dispersijas kvadrātsakne.
Standarta novirze:
s = n n − 1 σ 2 = 1 n − 1 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s=(\sqrt ((\frac (n)(n-1))\sigma ^(2)))=(\sqrt ((\frac (1)(n-1))\sum _( i=1)^(n)\left(x_(i)-(\bar (x))\right)^(2)));)- Piezīme: Ļoti bieži MSD (Root Mean Square Deviation) un STD (standarta novirze) nosaukumos ar to formulām ir neatbilstības. Piemēram, Python programmēšanas valodas modulī numPy funkcija std() ir aprakstīta kā "standarta novirze", savukārt formula atspoguļo standarta novirzi (dalījumu ar parauga sakni). Programmā Excel funkcija STANDARDEVAL() ir atšķirīga (dalīšana ar n-1 sakni).
Standarta novirze(gadījuma lieluma standartnovirzes aprēķins x attiecībā pret tā matemātiskajām prognozēm, pamatojoties uz objektīvu tās dispersijas novērtējumu) s (\displaystyle s):
σ = 1 n ∑ i = 1 n (x i − x ¯) 2 . (\displaystyle \sigma =(\sqrt ((\frac (1)(n))\sum _(i=1)^(n)\left(x_(i)-(\bar (x))\right) ^(2))).)Kur σ 2 (\displaystyle \sigma ^(2))- dispersija; x i (\displaystyle x_(i)) - i atlases elements; n (\displaystyle n)- izlases lielums; - izlases vidējais aritmētiskais:
x ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + … + x n) . (\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\lpunkti +x_(n)).Jāatzīmē, ka abas aplēses ir neobjektīvas. Vispārīgā gadījumā nav iespējams izveidot objektīvu tāmi. Tomēr aprēķins, kas balstīts uz objektīvu dispersijas novērtējumu, ir konsekvents.
Saskaņā ar GOST R 8.736-2011 standarta novirzi aprēķina, izmantojot šīs sadaļas otro formulu. Lūdzu, pārbaudiet rezultātus.
Trīs sigmu noteikums
Trīs sigmu noteikums (3 σ (\displaystyle 3\sigma)) - gandrīz visas normāli sadalītā gadījuma lieluma vērtības atrodas intervālā (x ¯ − 3 σ ; x ¯ + 3 σ) (\displaystyle \left((\bar (x))-3\sigma ;(\bar (x))+3\sigma \right)). Stingrāk - ar aptuveni varbūtību 0,9973 normāli sadalīta gadījuma lieluma vērtība atrodas norādītajā intervālā (ar nosacījumu, ka vērtība x ¯ (\displaystyle (\bar (x))) patiess, un tas nav iegūts parauga apstrādes rezultātā).
Ja patiesā vērtība x ¯ (\displaystyle (\bar (x))) nav zināms, tad nevajadzētu lietot σ (\displaystyle \sigma ), A s. Tādējādi trīs sigmu noteikums tiek pārveidots par trīs sigmu likumu s .
Standartnovirzes vērtības interpretācija
Lielāka standarta novirzes vērtība parāda lielāku vērtību izplatību uzrādītajā komplektā ar kopas vidējo vērtību; mazāka vērtība attiecīgi parāda, ka vērtības komplektā ir sagrupētas ap vidējo vērtību.
Piemēram, mums ir trīs skaitļu kopas: (0, 0, 14, 14), (0, 6, 8, 14) un (6, 6, 8, 8). Visām trim kopām ir vidējās vērtības, kas vienādas ar 7, un standarta novirzes, attiecīgi, ir vienādas ar 7, 5 un 1. Pēdējā komplektā ir neliela standarta novirze, jo kopas vērtības ir sagrupētas ap vidējo vērtību; pirmajai kopai ir vislielākā standarta novirzes vērtība - vērtības komplektā ievērojami atšķiras no vidējās vērtības.
Vispārīgā nozīmē standarta novirzi var uzskatīt par nenoteiktības mēru. Piemēram, fizikā standarta novirzi izmanto, lai noteiktu kāda daudzuma secīgu mērījumu sērijas kļūdu. Šī vērtība ir ļoti svarīga, lai noteiktu pētāmās parādības ticamību salīdzinājumā ar teorijas prognozēto vērtību: ja mērījumu vidējā vērtība ļoti atšķiras no teorijas prognozētajām vērtībām (liela standartnovirze), tad vēlreiz jāpārbauda iegūtās vērtības vai to iegūšanas metode. identificēts ar portfeļa risku.
Klimats
Pieņemsim, ka ir divas pilsētas ar vienādu vidējo maksimālo diennakts temperatūru, bet viena atrodas piekrastē, bet otra - līdzenumā. Ir zināms, ka pilsētās, kas atrodas piekrastē, ir daudz dažādu maksimālo dienas temperatūru, kas ir zemāka nekā pilsētās, kas atrodas iekšzemē. Tāpēc maksimālās diennakts temperatūras standartnovirze piekrastes pilsētai būs mazāka nekā otrai pilsētai, neskatoties uz to, ka to vidējā vērtība ir vienāda, kas praksē nozīmē, ka varbūtība, ka Maksimālā temperatūra katras konkrētās gada dienas gaiss vairāk atšķirsies no vidējās vērtības, augstāks pilsētai, kas atrodas kontinenta iekšienē.
Sports
Pieņemsim, ka ir vairākas futbola komandas, kuras tiek vērtētas pēc kāda parametru kopuma, piemēram, gūto un ielaisto vārtu skaits, gūšanas iespējas utt. Visticamāk, ka šīs grupas labākajai komandai būs labākās vērtības pēc vairākiem parametriem. Jo mazāka ir komandas standarta novirze katram no uzrādītajiem parametriem, jo prognozējamāks ir komandas rezultāts, šādas komandas ir līdzsvarotas. No otras puses, komanda ar liela vērtība standarta novirze ir grūti paredzēt rezultātu, kas savukārt ir izskaidrojams ar nelīdzsvarotību, piemēram, spēcīga aizsardzība, bet ar vāju uzbrukumu.
Izmantojot komandu parametru standartnovirzi, vienā vai otrā pakāpē ir iespējams paredzēt divu komandu spēles rezultātu, novērtējot spēkus un komandas. vājās puses komandas un līdz ar to arī izvēlētās cīņas metodes.
Definēts kā vispārinošs raksturlielums, kas raksturo pazīmes variācijas lielumu kopumā. Tas ir vienāds ar kvadrātsakni no atribūta individuālo vērtību vidējās kvadrātiskās novirzes no vidējā aritmētiskā, t.i. Sakni un var atrast šādi:
1. Primārajai rindai:
2. Variāciju sērijām:

Standartnovirzes formulas pārveidošana padara to praktiskiem aprēķiniem ērtākā formā:
Vidēji standarta novirze nosaka, cik vidēji konkrētas opcijas atšķiras no to vidējās vērtības, kā arī ir absolūts raksturlieluma mainīguma mērs un tiek izteikts tajās pašās vienībās kā opcijas, un tāpēc ir labi interpretēts.
Standarta novirzes atrašanas piemēri: ,
Alternatīvajiem raksturlielumiem standarta novirzes formula izskatās šādi:

kur p ir to vienību īpatsvars populācijā, kurām ir noteikts raksturlielums;
q ir to vienību īpatsvars, kurām nav šīs pazīmes.
Vidējās lineārās novirzes jēdziens
Vidējā lineārā novirze definēts kā vidējais aritmētiskais absolūtās vērtības individuālo iespēju novirzes no .
1. Primārajai rindai:

2. Variāciju sērijām:

kur ir summa n variāciju rindu frekvenču summa.
Vidējās lineārās novirzes atrašanas piemērs:
Vidējās absolūtās novirzes kā izkliedes mēra priekšrocība variāciju diapazonā ir acīmredzama, jo šis rādītājs ir balstīts uz visu iespējamās novirzes. Bet šim rādītājam ir būtiski trūkumi. Patvaļīga algebrisko noviržu pazīmju noraidīšana var novest pie tā, ka šī rādītāja matemātiskās īpašības ir tālu no elementārām. Tas ļoti apgrūtina vidējās absolūtās novirzes izmantošanu, risinot problēmas, kas saistītas ar varbūtības aprēķiniem.
Tāpēc vidējā lineārā novirze kā raksturlieluma variācijas mērs statistikas praksē tiek izmantota reti, proti, rādītāju summēšanai, neņemot vērā zīmes, ir ekonomiska jēga. Ar tās palīdzību, piemēram, tiek analizēts ārējās tirdzniecības apgrozījums, strādnieku sastāvs, ražošanas ritms u.c.
Vidējais kvadrāts
Lietots vidējais kvadrāts, piemēram, lai aprēķinātu vidējo izmēru n kvadrātveida sekcijām, vidējos stumbru, cauruļu diametrus utt. Tas ir sadalīts divos veidos.
Vienkāršs vidējais kvadrāts. Ja, aizstājot atsevišķas raksturlieluma vērtības ar vidējā vērtība Ja ir nepieciešams saglabāt sākotnējo vērtību kvadrātu summu nemainīgu, tad vidējā vērtība būs kvadrātiskā vidējā vērtība.
Tā ir kvadrātsakne no koeficienta, kas dala atsevišķu atribūtu vērtību kvadrātu summu ar to skaitu:
Svērto vidējo kvadrātu aprēķina pēc formulas:

kur f ir svara zīme.
Vidējais kub
Tiek piemērots vidējais kub, piemēram, nosakot malas un kubu vidējo garumu. Tas ir sadalīts divos veidos.
Vidējais kubiskais vienkāršais:

Aprēķinot vidējās vērtības un dispersiju intervālu sadalījuma sērijās, atribūta patiesās vērtības tiek aizstātas ar intervālu centrālajām vērtībām, kas atšķiras no vidējām. aritmētiskās vērtības iekļauts intervālā. Tas noved pie sistemātiskas kļūdas, aprēķinot dispersiju. V.F. Šepards to noteica kļūda dispersijas aprēķinā, ko izraisa grupētu datu izmantošana, ir 1/12 no intervāla kvadrāta gan novirzes augšup, gan lejupvērstā virzienā.
Šeparda grozījums jāizmanto, ja sadalījums ir tuvu normālam, attiecas uz raksturlielumu ar nepārtrauktu variāciju raksturu un ir balstīts uz ievērojamu sākotnējo datu apjomu (n > 500). Taču, pamatojoties uz to, ka dažos gadījumos abas kļūdas, kas darbojas dažādos virzienos, viena otru kompensē, dažkārt ir iespējams atteikties no labojumu ieviešanas.
Kā mazāka vērtība dispersiju un standartnovirzi, jo viendabīgāka populācija un tipiskāka būs vidējais rādītājs.
Statistikas praksē bieži vien ir jāsalīdzina variācijas dažādas zīmes. Piemēram, ir ļoti interesanti salīdzināt darbinieku vecuma un viņu kvalifikācijas, darba stāža un lieluma atšķirības algas, izmaksas un peļņa, darba stāžs un darba ražīgums utt. Šādiem salīdzinājumiem nav piemēroti raksturlielumu absolūtās mainīguma rādītāji: nav iespējams salīdzināt gados izteiktu darba pieredzes mainīgumu ar rubļos izteiktu darba samaksas svārstībām.Lai veiktu šādus salīdzinājumus, kā arī vienas un tās pašas pazīmes mainīguma salīdzinājumus vairākās populācijās ar dažādiem vidējiem aritmētiskajiem rādītājiem, tiek izmantots relatīvais rādītājs variācija - variācijas koeficients.
Strukturālie vidējie rādītāji
Centrālās tendences raksturošanai statistiskajos sadalījumos bieži vien ir racionāli izmantot kopā ar vidējo aritmētisko raksturlieluma X noteiktu vērtību, kas, pateicoties noteiktām atrašanās vietas iezīmēm sadalījuma rindā, var raksturot tā līmeni.
Tas ir īpaši svarīgi, ja sadalījuma sērijās raksturlieluma galējām vērtībām ir neskaidras robežas. Sakarā ar šo precīza definīcija Vidējais aritmētiskais parasti ir neiespējams vai ļoti grūts. Tādos gadījumos vidējais līmenis var noteikt, ņemot, piemēram, iezīmes vērtību, kas atrodas frekvenču sērijas vidū vai kas notiek visbiežāk pašreizējā sērijā.
Šādas vērtības ir atkarīgas tikai no frekvenču rakstura, t.i., no sadalījuma struktūras. Tās ir raksturīgas pēc atrašanās vietas virknē frekvenču, tāpēc šādas vērtības tiek uzskatītas par sadalījuma centra pazīmēm, un tāpēc tās saņēma strukturālo vidējo vērtību definīciju. Tos izmanto mācībām iekšējā struktūra un atribūtu vērtību sadalījuma sērijas struktūra. Šādi rādītāji ietver:
Vispilnīgākais variācijas raksturlielums ir vidējā kvadrātiskā novirze, ko sauc par standartu (vai standarta novirzi). Standarta novirze() ir vienāds ar kvadrātsakni no atribūta individuālo vērtību vidējās kvadrātiskās novirzes no vidējā aritmētiskā:
Standarta novirze ir vienkārša:


Grupētiem datiem tiek piemērota svērtā standarta novirze:

Starp vidējo kvadrātisko un vidējo lineāro novirzi normālā sadalījuma apstākļos notiek šāda attiecība: ~ 1,25.
Standartnovirze, kas ir galvenais absolūtais variācijas mērs, tiek izmantota normālā sadalījuma līknes ordinātu vērtību noteikšanā, aprēķinos, kas saistīti ar paraugu novērošanas organizēšanu un parauga raksturlielumu precizitātes noteikšanu, kā arī, novērtējot raksturlieluma variācijas robežas viendabīgā populācijā.
Dispersija, tās veidi, standartnovirze.
Gadījuma lieluma dispersija— dotā gadījuma lieluma izplatības mērs, t.i., tā novirze no matemātiskās cerības. Statistikā bieži tiek lietots apzīmējums vai. Kvadrātsakne dispersiju sauc par standarta novirzi, standarta novirzi vai standarta izkliedi.
Kopējā dispersija (σ 2) mēra iezīmes izmaiņas kopumā visu faktoru ietekmē, kas izraisīja šīs izmaiņas. Tajā pašā laikā, pateicoties grupēšanas metodei, ir iespējams identificēt un izmērīt variāciju grupēšanas raksturlieluma dēļ un variāciju, kas rodas neņemtu faktoru ietekmē.
Starpgrupu dispersija (σ 2 m.gr) raksturo sistemātisku variāciju, t.i., pētāmās pazīmes vērtības atšķirības, kas rodas pazīme - grupas pamatā esošā faktora - ietekmē.
Standarta novirze(sinonīmi: standarta novirze, standarta novirze, kvadrātiskā novirze; saistītie termini: standarta novirze, standarta izkliede) - varbūtības teorijā un statistikā visizplatītākais nejaušā mainīgā lieluma vērtību izkliedes rādītājs attiecībā pret tā matemātisko cerību. Ar ierobežotiem vērtību paraugu masīviem matemātiskās cerības vietā tiek izmantots paraugu kopas vidējais aritmētiskais.
Standartnovirze tiek mērīta paša gadījuma lieluma vienībās un tiek izmantota, aprēķinot vidējā aritmētiskā standarta kļūdu, konstruējot ticamības intervālus, statistiski pārbaudot hipotēzes, mērot lineāro sakarību starp nejaušajiem mainīgajiem. Definēta kā nejauša lieluma dispersijas kvadrātsakne.
Standarta novirze:

Standarta novirze(gadījuma lieluma standartnovirzes aprēķins x attiecībā pret tā matemātisko cerību, pamatojoties uz objektīvu tās dispersijas aplēsi):

kur ir dispersija; — i atlases elements; — izlases lielums; — izlases vidējais aritmētiskais:

Jāatzīmē, ka abas aplēses ir neobjektīvas. Vispārīgā gadījumā nav iespējams izveidot objektīvu tāmi. Tomēr aprēķins, kas balstīts uz objektīvu dispersijas novērtējumu, ir konsekvents.
Režīma un mediānas noteikšanas būtība, apjoms un procedūra.
Papildus jaudas vidējiem rādītājiem statistikā mainīga raksturlieluma vērtības un sadalījuma rindu iekšējās struktūras relatīvai raksturošanai tiek izmantoti strukturālie vidējie lielumi, kurus galvenokārt attēlo mode un mediāna.
Mode- Šis ir visizplatītākais sērijas variants. Mode tiek izmantota, piemēram, klientu vidū pieprasītāko apģērbu un apavu izmēru noteikšanai. Diskrētās sērijas režīms ir tas, kuram ir visaugstākā frekvence. Aprēķinot režīmu intervāla variāciju sērijai, vispirms ir jānosaka modālais intervāls (ar maksimālā frekvence), un pēc tam - atribūta modālās vērtības vērtība saskaņā ar formulu:

- - modes vērtība
- — modālā intervāla apakšējā robeža
- — intervāla lielums
- — modālā intervāla biežums
- — intervāla biežums pirms modāla
- — intervāla biežums pēc modāla
Vidējā —šī ir atribūta vērtība, kas ir ranžētās sērijas pamatā un sadala šo sēriju divās vienādās daļās.
Lai noteiktu mediānu diskrētā virknē frekvenču klātbūtnē, vispirms aprēķiniet frekvenču pussummu un pēc tam nosakiet, kura varianta vērtība uz to attiecas. (Ja sakārtotajā sērijā ir nepāra skaits pazīmju, tad vidējo skaitli aprēķina, izmantojot formulu:
M e = (n (pazīmju skaits kopā) + 1)/2,
pāra pazīmju skaita gadījumā mediāna būs vienāda ar abu rindas vidū esošo pazīmju vidējo vērtību).
Aprēķinot mediānas intervāla variāciju sērijai vispirms nosakiet vidējo intervālu, kurā atrodas mediāna, un pēc tam nosakiet mediānas vērtību, izmantojot formulu:

- — nepieciešamā mediāna
- - intervāla apakšējā robeža, kas satur mediānu
- — intervāla lielums
- — frekvenču summa vai sērijas terminu skaits
Intervālu uzkrāto biežumu summa pirms mediānas
- — vidējā intervāla biežums
Piemērs. Atrodiet režīmu un mediānu.
Risinājums:
Šajā piemērā modālais intervāls ir vecuma grupā no 25 līdz 30 gadiem, jo šim intervālam ir visaugstākais biežums (1054).Aprēķināsim režīma lielumu:
Tas nozīmē, ka studentu modālais vecums ir 27 gadi.
Aprēķināsim mediānu. Vidējais intervāls ir iekšā vecuma grupa 25-30 gadi, jo šajā intervālā ir iespēja sadalīt iedzīvotājus divās vienādās daļās (Σf i /2 = 3462/2 = 1731). Tālāk formulā aizstājam nepieciešamos skaitliskos datus un iegūstam vidējo vērtību:

Tas nozīmē, ka puse skolēnu ir jaunāki par 27,4 gadiem, bet otra puse ir vecāki par 27,4 gadiem.
Papildus režīmam un mediānai var izmantot tādus rādītājus kā kvartiles, sadalot sakārtotās sērijas 4 vienādās daļās, deciles- 10 daļas un procentiles - uz 100 daļām.
Selektīvā novērošanas jēdziens un tā apjoms.
Selektīvs novērojums attiecas uz nepārtrauktas uzraudzības izmantošanu fiziski neiespējami liela datu apjoma dēļ vai nav ekonomiski izdevīgi. Fiziska neiespējamība rodas, piemēram, pētot pasažieru plūsmas, tirgus cenas, ģimenes budžeti. Ekonomiskā neizdevība rodas, novērtējot ar to iznīcināšanu saistīto preču kvalitāti, piemēram, degustējot, pārbaudot ķieģeļu stiprību utt.
Novērošanai atlasītās statistikas vienības veido izlases ietvaru vai izlasi, un viss to masīvs veido vispārējo populāciju (GS). Šajā gadījumā vienību skaitu izlasē apzīmē ar n, un visā HS - N. Attieksme n/N sauc par parauga relatīvo lielumu vai proporciju.
Izlases novērošanas rezultātu kvalitāte ir atkarīga no izlases reprezentativitātes, tas ir, no tā, cik reprezentatīvs tas ir HS. Lai nodrošinātu izlases reprezentativitāti, ir jāievēro vienību nejaušas izvēles princips, kas pieņem, ka HS vienības iekļaušanu izlasē nevar ietekmēt neviens cits faktors, izņemot nejaušību.
Pastāv 4 nejaušās atlases veidi lai paraugs:
- Patiesībā nejauši atlase vai "loto metode", ja tiek piešķirtas statistiskās vērtības sērijas numuri, kas novietoti uz noteiktiem priekšmetiem (piemēram, mucām), kurus pēc tam sajauc kādā traukā (piemēram, maisā) un atlasa pēc nejaušības principa. Praksē šī metode tiek veikta, izmantojot nejaušo skaitļu ģeneratoru vai nejaušu skaitļu matemātiskās tabulas.
- Mehānisks atlase, saskaņā ar kuru katrs ( N/n)-th kopējās populācijas vērtība. Piemēram, ja tajā ir 100 000 vērtību un jums ir jāatlasa 1000, tad izlasē tiks iekļauta katra 100 000 / 1000 = 100. vērtība. Turklāt, ja tie nav sarindoti, tad pirmais tiek nejauši izvēlēts no pirmā simta, bet pārējo skaits būs par simts lielāks. Piemēram, ja pirmā vienība bija Nr.19, tad nākamajai jābūt Nr.119, tad Nr.219, tad Nr.319 utt. Ja iedzīvotāju vienības ir sarindotas, tad vispirms tiek izvēlēts Nr.50, tad Nr.150, tad Nr.250 un tā tālāk.
- Tiek veikta vērtību atlase no neviendabīga datu masīva stratificēts(stratificētā) metode, kad populāciju vispirms sadala homogēnās grupās, kurām piemēro nejaušu vai mehānisku atlasi.
- Īpaša paraugu ņemšanas metode ir seriāls atlase, kurā nejauši vai mehāniski izvēlas nevis atsevišķas vērtības, bet to sērijas (secības no kāda skaitļa līdz kādam skaitlim pēc kārtas), kuras ietvaros tiek veikta nepārtraukta novērošana.
Izlases novērojumu kvalitāte ir atkarīga arī no parauga veids: atkārtoja vai neatkārtojami.
Plkst atkārtota atlase Izlasē iekļautās statistiskās vērtības vai to sērijas pēc izmantošanas tiek atgrieztas vispārējai populācijai ar iespēju iekļauties jaunā izlasē. Turklāt visām populācijas vērtībām ir vienāda varbūtība iekļauties izlasē.
Neatkārtota atlase nozīmē, ka izlasē iekļautās statistiskās vērtības vai to sērijas pēc izmantošanas neatgriežas vispārējā populācijā, un tāpēc pēdējās atlikušajām vērtībām palielinās varbūtība tikt iekļautam nākamajā izlasē.
Neatkārtota paraugu ņemšana dod precīzākus rezultātus, tāpēc to izmanto biežāk. Bet ir situācijas, kad to nevar pielietot (pētot pasažieru plūsmas, patērētāju pieprasījumu utt.) un tad tiek veikta atkārtota atlase.
Maksimālā novērojumu izlases kļūda, vidējā izlases kļūda, to aprēķināšanas kārtība.
Ļaujiet mums sīkāk apsvērt iepriekš uzskaitītās izlases kopas veidošanas metodes un kļūdas, kas rodas, to darot. reprezentativitāte .
Pareizi nejauši izlases pamatā ir vienību atlase no populācijas izlases veidā bez sistemātiskiem elementiem. Tehniski faktiskā nejaušā atlase tiek veikta, izlozējot (piemēram, loterijas) vai izmantojot nejaušo skaitļu tabulu.Pareiza izlases veida atlase “tīrā veidā” selektīvās novērošanas praksē tiek izmantota reti, taču tā ir oriģināla starp citiem atlases veidiem, tā īsteno selektīvās novērošanas pamatprincipus. Apskatīsim dažus jautājumus par izlases metodes teoriju un kļūdas formulu vienkāršai nejaušai izlasei.
Izlases neobjektivitāte ir starpība starp parametra vērtību vispārējā populācijā un tā vērtību, kas aprēķināta no izlases novērošanas rezultātiem. Vidējam kvantitatīvajam raksturlielumam izlases kļūdu nosaka ar
Indikatoru sauc par marginālo izlases kļūdu.
Izlases vidējais lielums ir nejaušs mainīgais, ko var ņemt dažādas nozīmes atkarībā no tā, kuras vienības tika iekļautas izlasē. Tāpēc izlases kļūdas ir arī nejauši mainīgie un var iegūt dažādas vērtības. Tāpēc nosakiet vidējo no iespējamās kļūdas - vidējā izlases kļūda, kas ir atkarīgs no:Parauga lielums: nekā vairāk skaitļu, jo mazāka ir vidējā kļūda;
Pētāmā raksturlieluma izmaiņu pakāpe: jo mazāka ir raksturlieluma variācija un līdz ar to arī dispersija, jo mazāka ir vidējā izlases kļūda.
Plkst nejauša atkārtota atlase vidējo kļūdu aprēķina:
.
Praksē vispārējā dispersija nav precīzi zināma, bet gan varbūtības teorija tas ir pierādīts .
.
Tā kā pietiekami liela n vērtība ir tuvu 1, mēs varam pieņemt, ka . Tad var aprēķināt vidējo izlases kļūdu:
.
Bet neliela izlases gadījumā (ar n<30) коэффициент необходимо учитывать, и среднюю ошибку малой выборки рассчитывать по формуле .
.Plkst izlases veida neatkārtota paraugu ņemšana dotās formulas koriģē ar vērtību . Tad vidējā neatkārtojamā izlases kļūda ir:
 Un
Un  .
.
Jo vienmēr ir mazāks, tad reizinātājs () vienmēr ir mazāks par 1. Tas nozīmē, ka vidējā kļūda neatkārtotās atlases laikā vienmēr ir mazāka nekā atkārtotas atlases laikā.
Mehāniskā paraugu ņemšana tiek izmantots, ja vispārējie iedzīvotāji ir kaut kādā veidā sakārtoti (piemēram, alfabētiski balsotāju saraksti, tālruņu numuri, māju numuri, dzīvokļu numuri). Vienību atlase tiek veikta ar noteiktu intervālu, kas ir vienāds ar paraugu ņemšanas procentu apgriezto vērtību. Tātad ar 2% izlasi tiek atlasītas katras 50 vienības = 1/0,02, ar 5% izlasi - katras 1/0,05 = 20 vispārējās populācijas vienības.Atskaites punkts tiek izvēlēts dažādos veidos: nejauši, no intervāla vidus, mainot atskaites punktu. Galvenais ir izvairīties no sistemātiskām kļūdām. Piemēram, ar 5% izlasi, ja pirmā vienība ir 13., tad nākamās ir 33, 53, 73 utt.
Precizitātes ziņā mehāniskā atlase ir tuvu faktiskajai izlases veida izlasei. Tāpēc, lai noteiktu mehāniskās izlases vidējo kļūdu, tiek izmantotas pareizas nejaušās atlases formulas.
Plkst tipiska atlase aptaujātie iedzīvotāji provizoriski sadalīti viendabīgās, līdzīgās grupās. Piemēram, apsekojot uzņēmumus, tās var būt nozares, apakšnozares, pētot iedzīvotājus, tie var būt reģioni, sociālās vai vecuma grupas. Pēc tam mehāniski vai tīri nejauši tiek veikta neatkarīga atlase no katras grupas.
Parastā paraugu ņemšana dod precīzākus rezultātus nekā citas metodes. Vispārīgās populācijas tipizēšana nodrošina katras tipoloģiskās grupas pārstāvniecību izlasē, kas ļauj novērst starpgrupu dispersijas ietekmi uz vidējo izlases kļūdu. Līdz ar to, atrodot tipiskas izlases kļūdu pēc dispersiju saskaitīšanas likuma (), jāņem vērā tikai grupas dispersiju vidējā vērtība. Tad vidējā izlases kļūda ir:
pēc atkārtotas atlases
,
ar neatkārtotu atlasi ,
,
Kur - vidējās atšķirības starp grupām izlasē.
- vidējās atšķirības starp grupām izlasē.Sērijas (vai ligzdas) atlase izmanto, ja kopa ir sadalīta sērijās vai grupās pirms izlases apsekojuma sākuma. Šīs sērijas var būt gatavās produkcijas iepakojums, studentu grupas, komandas. Sērijas pārbaudei tiek atlasītas mehāniski vai tīri nejauši, un sērijas ietvaros tiek veikta nepārtraukta vienību pārbaude. Tāpēc vidējā izlases kļūda ir atkarīga tikai no starpgrupu (starprindu) dispersijas, ko aprēķina pēc formulas:

kur r ir atlasīto sēriju skaits;
- i-tās sērijas vidējais rādītājs.Vidējo sērijas paraugu ņemšanas kļūdu aprēķina:
pēc atkārtotas atlases:
,
ar neatkārtotu atlasi: ,
,
kur R ir kopējais epizožu skaits.Kombinēts atlase ir aplūkoto atlases metožu kombinācija.
Vidējā izlases kļūda jebkurai izlases metodei galvenokārt ir atkarīga no parauga absolūtā lieluma un mazākā mērā no parauga procentuālās daļas. Pieņemsim, ka pirmajā gadījumā tiek veikti 225 novērojumi no 4500 vienību populācijas, bet otrajā - no 225 000 vienību populācijas. Abos gadījumos novirzes ir vienādas ar 25. Tad pirmajā gadījumā ar 5% atlasi izlases kļūda būs:

Otrajā gadījumā ar 0,1% atlasi tas būs vienāds ar:
Tādējādi, samazinoties paraugu ņemšanas procentam par 50 reizēm, izlases kļūda nedaudz palielinājās, jo izlases lielums nemainījās.
Pieņemsim, ka izlases lielums ir palielināts līdz 625 novērojumiem. Šajā gadījumā izlases kļūda ir:
Izlases palielināšana 2,8 reizes ar tādu pašu populācijas lielumu samazina izlases kļūdas lielumu vairāk nekā 1,6 reizes.Izlases populācijas veidošanas metodes un metodes.
Statistikā tiek izmantotas dažādas izlases populāciju veidošanas metodes, kuras nosaka pētījuma mērķi un ir atkarīga no pētāmā objekta specifikas.
Galvenais nosacījums izlases veida apsekojuma veikšanai ir nepieļaut sistemātisku kļūdu rašanos, kas izriet no vienlīdzīgu iespēju principa pārkāpuma katrai izlasē iekļaujamās vispārējās populācijas vienībai. Sistemātisku kļūdu novēršana tiek panākta, izmantojot zinātniski pamatotas metodes izlases kopas veidošanai.
Ir šādas metodes vienību atlasei no populācijas:
1) individuālā atlase - izlasei tiek atlasītas atsevišķas vienības;
2) grupu atlase - izlasē iekļautas kvalitatīvi viendabīgas pētāmās grupas vai vienību sērijas;
3) kombinētā atlase ir individuālās un grupu atlases kombinācija.
Atlases metodes nosaka izlases kopas veidošanas noteikumi.Paraugs varētu būt:
- patiesībā nejauši sastāv no tā, ka izlases kopa veidojas nejaušas (neapzinātas) atsevišķu vienību atlases rezultātā no vispārējās populācijas. Šajā gadījumā izlases populācijā atlasīto vienību skaitu parasti nosaka, pamatojoties uz pieņemto izlases proporciju. Izlases proporcija ir izlases kopas n vienību skaita attiecība pret vienību skaitu vispārējā populācijā N, t.i.
- mehānisks sastāv no tā, ka vienību atlase izlases populācijā tiek veikta no vispārējās populācijas, kas sadalīta vienādos intervālos (grupās). Šajā gadījumā intervāla lielums populācijā ir vienāds ar izlases proporcijas apgriezto vērtību. Tātad ar 2% izlasi tiek atlasīta katra 50. vienība (1:0,02), ar 5% paraugu katra 20. vienība (1:0,05) utt. Tādējādi saskaņā ar pieņemto atlases proporciju vispārējā populācija tiek it kā mehāniski sadalīta vienāda lieluma grupās. No katras grupas izlasei tiek izvēlēta tikai viena vienība.
- tipisks - kurā vispārējā populācija vispirms tiek sadalīta viendabīgās tipiskās grupās. Pēc tam no katras tipiskās grupas tiek izmantots tīri nejaušs vai mehānisks paraugs, lai atsevišķi atlasītu vienības izlases populācijā. Svarīga tipiskas izlases iezīme ir tā, ka tā sniedz precīzākus rezultātus salīdzinājumā ar citām vienību atlases metodēm izlases populācijā;
- seriāls- kurā vispārējā populācija ir sadalīta vienāda lieluma grupās - sērijas. Sērijas tiek atlasītas izlases populācijā. Sērijas ietvaros tiek veikta nepārtraukta sērijā iekļauto vienību novērošana;
- apvienots- paraugu ņemšana var būt divpakāpju. Šajā gadījumā iedzīvotāji vispirms tiek sadalīti grupās. Pēc tam tiek atlasītas grupas, un tajās tiek atlasītas atsevišķas vienības.
Statistikā izšķir šādas metodes vienību atlasei izlases populācijā::
- viens posms paraugu ņemšana - katra izvēlētā vienība tiek nekavējoties pakļauta izpētei saskaņā ar doto kritēriju (pareiza nejauša un sērijveida izlase);
- daudzpakāpju paraugu ņemšana - atlase tiek veikta no atsevišķu grupu vispārējās populācijas, un no grupām tiek atlasītas atsevišķas vienības (tipiska izlase ar mehānisku vienību atlases metodi izlases populācijā).
Turklāt ir:
- atkārtota atlase- pēc atdotās bumbas shēmas. Šādā gadījumā katra izlasē iekļautā vienība vai sērija tiek atgriezta kopējā populācijā, un tāpēc tai ir iespēja atkal tikt iekļautai izlasē;
- atkārtojiet atlasi- pēc neatgrieztās bumbas shēmas. Tam ir precīzāki rezultāti ar tādu pašu izlases lielumu.
Nepieciešamā izlases lieluma noteikšana (izmantojot Stjudenta t-tabulu).
Viens no izlases teorijas zinātniskajiem principiem ir nodrošināt, lai tiktu izvēlēts pietiekams skaits vienību. Teorētiski šī principa ievērošanas nepieciešamība ir parādīta varbūtību teorijas robežteorēmu pierādījumos, kas ļauj noteikt, kāds vienību apjoms būtu jāizvēlas no kopas, lai tas būtu pietiekams un nodrošinātu izlases reprezentativitāti.
Standarta izlases kļūdas samazināšanās un līdz ar to arī aplēses precizitātes palielināšanās vienmēr ir saistīta ar izlases lieluma palielināšanos, tāpēc jau izlases novērošanas organizēšanas posmā ir jāizlemj, kāds ir izlases lielums. izlases populācijai jābūt tādai, lai nodrošinātu nepieciešamo novērojumu rezultātu precizitāti. Nepieciešamā izlases lieluma aprēķins tiek konstruēts, izmantojot formulas, kas iegūtas no maksimālās izlases kļūdu (A) formulām, kas atbilst noteiktam atlases veidam un metodei. Tātad nejaušam atkārtotam izlases lielumam (n) mums ir:

Šīs formulas būtība ir tāda, ka ar vajadzīgā skaitļa nejaušu atkārtotu atlasi izlases lielums ir tieši proporcionāls ticamības koeficienta kvadrātam. (t2) un variācijas raksturlieluma dispersiju (?2) un ir apgriezti proporcionāla maksimālās izlases kļūdas kvadrātam (?2). Jo īpaši, palielinoties maksimālajai kļūdai divas reizes, nepieciešamo izlases lielumu var samazināt par četriem koeficientiem. No trim parametriem divus (t un?) nosaka pētnieks.
Tajā pašā laikā pētnieks, pamatojoties uz No izlases aptaujas mērķa un uzdevumiem ir jāatrisina jautājums: kādā kvantitatīvā kombinācijā ir labāk iekļaut šos parametrus, lai nodrošinātu optimālo variantu? Vienā gadījumā viņš var būt vairāk apmierināts ar iegūto rezultātu ticamību (t) nekā ar precizitātes mēru (?), citā - otrādi. Grūtāk ir atrisināt jautājumu par maksimālās izlases kļūdas vērtību, jo pētniekam šī rādītāja nav izlases novērojuma projektēšanas stadijā, tāpēc praksē ir ierasts noteikt maksimālās izlases kļūdas vērtību parasti 10% robežās no paredzamā atribūta vidējā līmeņa. Novērtētā vidējā lieluma noteikšanai var pieiet dažādos veidos: izmantojot datus no līdzīgām iepriekšējām aptaujām vai izmantojot datus no izlases rāmja un veicot nelielu izmēģinājuma izlasi.
Visgrūtāk noteikt, veidojot izlases novērojumu, ir trešais parametrs formulā (5.2) - izlases kopas izkliede. Šajā gadījumā ir jāizmanto visa pētnieka rīcībā esošā informācija, kas iegūta iepriekš veiktās līdzīgās un pilotaptaujās.
Jautājums par definīciju nepieciešamais izlases lielums kļūst sarežģītāks, ja izlases apsekojumā tiek pētītas vairākas izlases vienību pazīmes. Šajā gadījumā katras pazīmes vidējie līmeņi un to variācijas, kā likums, ir atšķirīgas, un tāpēc izlemt, kurai no pazīmēm dot priekšroku, ir iespējams, tikai ņemot vērā pazīmju mērķi un mērķus. aptauja.
Veidojot izlases novērojumu, tiek pieņemta iepriekš noteikta pieļaujamās izlases kļūdas vērtība atbilstoši konkrētā pētījuma mērķiem un secinājumu iespējamībai, pamatojoties uz novērojumu rezultātiem.
Kopumā izlases vidējās maksimālās kļūdas formula ļauj noteikt:
Vispārējo populācijas rādītāju iespējamo noviržu lielums no izlases populācijas rādītājiem;
Nepieciešamais izlases lielums, nodrošinot nepieciešamo precizitāti, pie kuras iespējamās kļūdas robežas nepārsniegs noteiktu noteikto vērtību;
Varbūtība, ka kļūdai paraugā būs noteikta robeža.
Studentu sadale varbūtības teorijā tā ir viena parametra absolūti nepārtrauktu sadalījumu saime.
Dinamiskās sērijas (intervāls, moments), noslēdzot dinamiskās sērijas.
Dinamikas sērija- tās ir statistisko rādītāju vērtības, kas tiek parādītas noteiktā hronoloģiskā secībā.
Katrā laikrindā ir divi komponenti:
1) laika periodu rādītāji (gadi, ceturkšņi, mēneši, dienas vai datumi);
2) pētāmo objektu raksturojošie rādītāji laika periodos vai atbilstošos datumos, kurus sauc par sēriju līmeņiem.
Sērijas līmeņi ir izteikti gan absolūtās, gan vidējās vai relatīvās vērtības. Atkarībā no rādītāju rakstura tiek veidotas absolūto, relatīvo un vidējo vērtību laikrindas. Dinamiskās rindas no relatīvajām un vidējām vērtībām tiek veidotas, pamatojoties uz atvasinātām absolūto vērtību sērijām. Ir dinamikas intervālu un momentu sērijas.
Dinamiskās intervālu sērijas satur indikatoru vērtības noteiktiem laika periodiem. Intervālu sērijās līmeņus var summēt, lai iegūtu parādības apjomu ilgākā laika posmā jeb tā sauktos uzkrātos kopsummas.
Dinamisku mirkļu sērija atspoguļo rādītāju vērtības noteiktā laika brīdī (laika datums). Momentu sērijās pētnieku var interesēt tikai parādību atšķirība, kas atspoguļo rindas līmeņa izmaiņas starp noteiktiem datumiem, jo līmeņu summai šeit nav reāla satura. Šeit netiek aprēķinātas kumulatīvās summas.
Svarīgākais nosacījums pareizai laikrindu konstruēšanai ir dažādiem periodiem piederošo rindu līmeņu salīdzināmība. Līmeņi ir jāuzrāda viendabīgos daudzumos, un dažādu parādības daļu pārklājumam jābūt vienādam.
Lai Lai izvairītos no reālās dinamikas izkropļojumiem, statistikas pētījumā tiek veikti provizoriskie aprēķini (noslēdzot dinamikas rindu), kas ir pirms laikrindu statistiskās analīzes. Ar dinamisko sēriju slēgšanu saprot apvienošanu vienā sērijā no divām vai vairākām sērijām, kuru līmeņi tiek aprēķināti pēc atšķirīgas metodoloģijas vai neatbilst teritoriālajām robežām utt. Dinamikas sērijas slēgšana var nozīmēt arī dinamikas sēriju absolūto līmeņu apvienošanu uz vienotu pamatu, kas neitralizē dinamikas sēriju līmeņu nesalīdzināmību.
Dinamikas rindu, koeficientu, pieauguma un pieauguma tempu salīdzināmības jēdziens.
Dinamikas sērija- tie ir statistikas rādītāju virkne, kas raksturo dabas un sociālo parādību attīstību laika gaitā. Krievijas Valsts statistikas komitejas publicētajos statistikas krājumos ir liels skaits dinamikas rindu tabulas veidā. Dinamiskās sērijas ļauj noteikt pētāmo parādību attīstības modeļus.
Dinamikas sērijas satur divu veidu rādītājus. Laika rādītāji(gadi, ceturkšņi, mēneši utt.) vai laika punkti (gada sākumā, katra mēneša sākumā utt.). Rindu līmeņa indikatori. Dinamikas rindu līmeņu rādītājus var izteikt absolūtās vērtībās (produkta produkcija tonnās vai rubļos), relatīvajās vērtībās (pilsētu iedzīvotāju īpatsvars procentos) un vidējās vērtībās (nozares strādnieku vidējās algas pa gadiem utt.). Tabulas veidā laikrindā ir divas kolonnas vai divas rindas.
Lai pareizi izveidotu laikrindas, ir jāizpilda vairākas prasības:
- visiem dinamikas sērijas rādītājiem jābūt zinātniski pamatotiem un uzticamiem;
- dinamikas sērijas rādītājiem jābūt salīdzināmiem laika gaitā, t.i. jāaprēķina par tiem pašiem laika periodiem vai tajos pašos datumos;
- vairāku dinamiku rādītājiem jābūt salīdzināmiem visā teritorijā;
- virknes dinamikas rādītājiem jābūt saturiski salīdzināmiem, t.i. aprēķina pēc vienas metodoloģijas, tādā pašā veidā;
- vairāku dinamiku rādītājiem jābūt salīdzināmiem visās ņemtajās saimniecībās. Visi dinamikas sērijas rādītāji jānorāda vienādās mērvienībās.
Statistikas rādītāji var raksturot vai nu pētāmā procesa rezultātus noteiktā laika periodā, vai pētāmās parādības stāvokli noteiktā laika momentā, t.i. indikatori var būt intervāli (periodiski) un momentāli. Attiecīgi sākotnēji dinamikas rindas var būt gan intervāls, gan moments. Momentu dinamikas rindas savukārt var būt ar vienādiem vai nevienādiem laika intervāliem.
Sākotnējās dinamikas sērijas var pārveidot par vidējo vērtību sēriju un relatīvo vērtību sēriju (ķēdes un pamata). Šādas laika rindas sauc par atvasinātām laikrindām.
Vidējā līmeņa aprēķināšanas metodika dinamikas rindās ir atšķirīga atkarībā no dinamikas rindas veida. Izmantojot piemērus, apskatīsim dinamikas rindu veidus un formulas vidējā līmeņa aprēķināšanai.
Absolūtie pieaugumi (Δy) parāda, cik vienību ir mainījies sērijas nākošais līmenis, salīdzinot ar iepriekšējo (gr. 3. - ķēdes absolūtais pieaugums) vai salīdzinājumā ar sākotnējo līmeni (gr. 4. - pamata absolūtais pieaugums). Aprēķinu formulas var uzrakstīt šādi:

Kad sērijas absolūtās vērtības samazinās, būs attiecīgi “samazinājums” vai “samazinājums”.
Absolūtās izaugsmes rādītāji liecina, ka, piemēram, 1998.gadā produkta “A” ražošana pieauga par 4 tūkstošiem tonnu, salīdzinot ar 1997.gadu, un par 34 tūkstošiem tonnu, salīdzinot ar 1994.gadu; par citiem gadiem skatīt tabulu. 11,5 gr. 3 un 4.
Pieauguma temps parāda, cik reizes ir mainījies rindas līmenis, salīdzinot ar iepriekšējo (gr. 5 - ķēdes pieauguma vai krituma koeficienti) vai salīdzinājumā ar sākotnējo līmeni (gr. 6 - pamata pieauguma vai krituma koeficienti). Aprēķinu formulas var uzrakstīt šādi:

Izaugsmes tempi parādīt, cik procentos ir nākamais sērijas līmenis, salīdzinot ar iepriekšējo (gr. 7 - ķēdes pieauguma tempi) vai salīdzinājumā ar sākotnējo līmeni (gr. 8 - pamata pieauguma tempi). Aprēķinu formulas var uzrakstīt šādi:

Tā, piemēram, 1997.gadā produkta “A” ražošanas apjoms, salīdzinot ar 1996.gadu, bija 105,5% (
Pieauguma temps parāda, par cik procentiem pieauga pārskata perioda līmenis, salīdzinot ar iepriekšējo (9.aile - ķēdes pieauguma tempi) vai salīdzinājumā ar sākotnējo līmeni (10.aile -pamata pieauguma tempi). Aprēķinu formulas var uzrakstīt šādi:
T pr = T r - 100% vai T pr = absolūtais pieaugums / iepriekšējā perioda līmenis * 100%
Tā, piemēram, 1996.gadā, salīdzinot ar 1995.gadu, produkts “A” tika saražots par 3,8% (103,8% - 100%) jeb (8:210)x100% vairāk, savukārt, salīdzinot ar 1994.gadu - par 9% (109% - 100%).
Ja absolūtie līmeņi rindā samazinās, tad likme būs mazāka par 100% un attiecīgi būs krituma temps (pieauguma temps ar mīnusa zīmi).
Absolūtā vērtība 1% pieaugums(11. aile) parāda, cik vienību ir jāsaražo noteiktā periodā, lai iepriekšējā perioda līmenis pieaugtu par 1%. Mūsu piemērā 1995.gadā bija nepieciešams saražot 2,0 tūkstošus tonnu, bet 1998.gadā - 2,3 tūkstošus tonnu, t.i. daudz lielāka.
1% pieauguma absolūto vērtību var noteikt divos veidos:
Iepriekšējā perioda līmenis tiek dalīts ar 100;
Sadaliet ķēdes absolūtos pieaugumus ar atbilstošajiem ķēdes pieauguma tempiem.
1% pieauguma absolūtā vērtība =

Dinamikā, īpaši ilgtermiņā, svarīga ir kopīga izaugsmes ātruma analīze ar katra procentuālā pieauguma vai samazinājuma saturu.
Ņemiet vērā, ka aplūkotā laikrindu analīzes metodika ir piemērojama gan laikrindām, kuru līmeņi ir izteikti absolūtās vērtībās (t, tūkstoši rubļu, darbinieku skaits utt.), gan laikrindām, kuru līmeņi ir izteikti relatīvos rādītājos (procenti no defektiem, % pelnu saturs oglēs utt.) vai vidējās vērtībās (vidējā raža c/ha, vidējā alga utt.).
Līdzās aplūkotajiem analītiskajiem rādītājiem, kas aprēķināti katram gadam salīdzinājumā ar iepriekšējo vai sākotnējo līmeni, analizējot dinamikas rindas, ir jāaprēķina perioda vidējie analītiskie rādītāji: rindas vidējais līmenis, gada vidējais absolūtais pieaugums. (samazinājums) un vidējais gada pieauguma temps un pieauguma temps.
Dinamikas sērijas vidējā līmeņa aprēķināšanas metodes tika apspriestas iepriekš. Intervālu dinamikas rindā, kuru mēs aplūkojam, sērijas vidējo līmeni aprēķina, izmantojot vienkāršu aritmētiskā vidējā formula:
Produkta vidējais ražošanas apjoms gadā 1994.-1998. sastādīja 218,4 tūkst.t.
Arī vidējo gada absolūto pieaugumu aprēķina, izmantojot vienkāršu aritmētisko vidējo formulu:
Gada absolūtais pieaugums gadu gaitā mainījās no 4 līdz 12 tūkstošiem tonnu (sk. 3. aili), un vidējais gada ražošanas pieaugums laika posmā no 1995. līdz 1998. gadam. sastādīja 8,5 tūkst.t.
Vidējā pieauguma ātruma un vidējā pieauguma ātruma aprēķināšanas metodes ir jāapsver sīkāk. Aplūkosim tos, izmantojot tabulā sniegto gada sēriju līmeņa rādītāju piemēru.
Dinamikas sērijas vidējais līmenis.
Dinamiskās sērijas (vai laikrindas)- tās ir noteikta statistiskā rādītāja skaitliskās vērtības secīgos brīžos vai laika periodos (t.i., sakārtoti hronoloģiskā secībā).
Tiek izsauktas viena vai cita statistiskā rādītāja, kas veido dinamikas rindas, skaitliskās vērtības sērijas līmeņi un parasti to apzīmē ar burtu y. Pirmais sērijas posms y 1 sauc par sākotnējo vai pamata līmenis, un pēdējais g n - galīgais. Brīžus vai laika periodus, uz kuriem attiecas līmeņi, norāda t.
Dinamikas sērijas parasti tiek parādītas tabulas vai diagrammas veidā, un laika skala tiek konstruēta gar abscisu asi t, un pa ordinātu asi - sēriju līmeņu skala y.
Dinamikas sērijas vidējie rādītāji
Katru dinamikas sēriju var uzskatīt par noteiktu kopu n laikā mainīgi rādītāji, kurus var apkopot kā vidējos rādītājus. Šādi vispārināti (vidējie) rādītāji ir īpaši nepieciešami, salīdzinot konkrēta rādītāja izmaiņas dažādos periodos, dažādās valstīs utt.
Dinamikas sērijas vispārināts raksturlielums var kalpot, pirmkārt, vidējās rindas līmenis. Vidējā līmeņa aprēķināšanas metode ir atkarīga no tā, vai sērija ir īslaicīga vai intervāla (periodiska).
Kad intervāls sērijas, tās vidējo līmeni nosaka pēc rindas līmeņu vienkārša aritmētiskā vidējā formula, t.i.
=
Ja ir pieejama brīdis rinda, kurā ir n līmeņi ( y1, y2, …, yn) ar vienādiem intervāliem starp datumiem (laikiem), tad šādu sēriju var viegli pārvērst vidējo vērtību sērijā. Šajā gadījumā rādītājs (līmenis) katra perioda sākumā vienlaikus ir rādītājs iepriekšējā perioda beigās. Tad katra perioda indikatora vidējo vērtību (intervālu starp datumiem) var aprēķināt kā pusi no vērtību summas plkst perioda sākumā un beigās, t.i. Kā . Šādu vidējo rādītāju skaits būs . Kā minēts iepriekš, vidējo vērtību sērijām vidējo līmeni aprēķina, izmantojot vidējo aritmētisko.Tāpēc mēs varam rakstīt:
 .
.
Pēc skaitītāja pārveidošanas mēs iegūstam: ,
,Kur Y1 Un Yn— rindas pirmais un pēdējais līmenis; Yi— vidējais līmenis.
Šis vidējais rādītājs statistikā ir zināms kā vidēji hronoloģiski uz mirkli sērijām. Tas saņēma savu nosaukumu no vārda “cronos” (laiks, latīņu valodā), jo tas tiek aprēķināts no rādītājiem, kas laika gaitā mainās.
Nevienlīdzības gadījumā intervālos starp datumiem hronoloģisko vidējo momentu sērijai var aprēķināt kā vidējo aritmētisko vērtību no katra momentu pāra līmeņu vidējām vērtībām, kas svērtas ar attālumiem (laika intervāliem) starp datumiem, t.i.
 .
.
Šajā gadījumā tiek pieņemts, ka intervālos starp datumiem līmeņi ieguva dažādas vērtības, un mēs esam viens no diviem zināmajiem ( yi Un yi+1) mēs nosakām vidējos rādītājus, no kuriem pēc tam aprēķinām kopējo vidējo vērtību visam analizējamajam periodam.
Ja tiek pieņemts, ka katra vērtība yi paliek nemainīgs līdz nākamajam (i+ 1)- brīdis, t.i. Ja ir zināms precīzs līmeņu izmaiņu datums, tad aprēķinu var veikt, izmantojot vidējo svērto aritmētisko formulu:
,kur ir laiks, kurā līmenis nemainījās.
Papildus vidējam līmenim dinamikas rindās tiek aprēķināti arī citi vidējie rādītāji - rindas līmeņu vidējās izmaiņas (pamata un ķēdes metodes), vidējais izmaiņu ātrums.
Bāzes līnija nozīmē absolūtas izmaiņas ir pēdējo pamatā esošo absolūto izmaiņu koeficients, kas dalīts ar izmaiņu skaitu. Tas ir
Ķēde nozīmē absolūtas izmaiņas rindas līmeņi ir koeficients, kurā visu ķēdes absolūto izmaiņu summa tiek dalīta ar izmaiņu skaitu, tas ir
Vidējo absolūto izmaiņu zīmi izmanto arī, lai spriestu par parādības izmaiņu raksturu vidēji: izaugsme, lejupslīde vai stabilitāte.
No pamata un ķēdes absolūto izmaiņu kontroles noteikuma izriet, ka pamata un ķēdes vidējām izmaiņām ir jābūt vienādām.
Kopā ar vidējām absolūtajām izmaiņām, izmantojot pamata un ķēdes metodi, tiek aprēķināts arī relatīvais vidējais.
Sākotnējās vidējās relatīvās izmaiņas nosaka pēc formulas:
Ķēdes vidējās relatīvās izmaiņas nosaka pēc formulas:
Dabiski, ka pamata un ķēdes vidējām relatīvajām izmaiņām ir jābūt vienādām, un, salīdzinot tās ar kritērija vērtību 1, tiek izdarīts secinājums par parādības izmaiņu raksturu vidēji: pieaugums, kritums vai stabilitāte.
Atņemot 1 no bāzes vai ķēdes vidējās relatīvās izmaiņas, atbilstošā vidējais izmaiņu ātrums, pēc kuras zīmes var spriest arī par pētāmās parādības izmaiņu raksturu, ko atspoguļo šī dinamikas virkne.Sezonālās svārstības un sezonalitātes indeksi.
Sezonālās svārstības ir stabilas gada svārstības.
Vadības pamatprincips, lai iegūtu maksimālu efektu, ir maksimizēt ienākumus un samazināt izmaksas. Pētot sezonālās svārstības, tiek atrisināta maksimālā vienādojuma problēma katrā gada līmenī.
Pētot sezonālās svārstības, tiek atrisinātas divas savstarpēji saistītas problēmas:
1. Parādības attīstības specifikas apzināšana intragada dinamikā;
2. Sezonālo svārstību mērīšana, veidojot sezonālo viļņu modeli;
Lai izmērītu sezonālās atšķirības, parasti tiek skaitīti sezonas tītari. Kopumā tos nosaka dinamikas rindu sākotnējo vienādojumu attiecība pret teorētiskajiem vienādojumiem, kas darbojas kā salīdzināšanas pamats.
Tā kā nejaušas novirzes tiek uzliktas uz sezonālām svārstībām, sezonalitātes indeksi tiek aprēķināti vidēji, lai tās novērstu.
Šajā gadījumā katram gada cikla periodam vispārīgos rādītājus nosaka vidējo sezonas indeksu veidā:
Vidējie sezonālo svārstību indeksi ir brīvi no galvenās attīstības tendences nejaušu noviržu ietekmes.
Atkarībā no tendences veida vidējā sezonalitātes indeksa formulai var būt šādas formas:
1.Gada iekšējās dinamikas sērijām ar skaidri izteiktu galveno attīstības tendenci:
2. Gada iekšējās dinamikas sērijām, kurās nav pieaugošas vai samazinošas tendences vai tās ir nenozīmīgas:
Kur ir kopējais vidējais rādītājs;
Galvenās tendences analīzes metodes.
Parādību attīstību laika gaitā ietekmē dažāda rakstura un ietekmes stipruma faktori. Dažiem no tiem ir nejaušs raksturs, citiem ir gandrīz nemainīga ietekme un tie veido noteiktu attīstības tendenci dinamikā.
Svarīgs statistikas uzdevums ir identificēt tendenču dinamiku sērijās, kas atbrīvotas no dažādu nejaušu faktoru ietekmes. Šim nolūkam laikrindas tiek apstrādātas, izmantojot intervālu palielināšanas, mainīgā vidējā un analītiskās izlīdzināšanas metodes utt.
Intervāla palielināšanas metode ir balstīta uz laika periodu palielināšanu, kas ietver virknes dinamikas līmeņus, t.i. ir ar maziem laika periodiem saistīto datu aizstāšana ar datiem par lielākiem periodiem. Tas ir īpaši efektīvs, ja sērijas sākotnējie līmeņi attiecas uz īsu laika periodu. Piemēram, rādītāju sērijas, kas saistītas ar ikdienas notikumiem, tiek aizstātas ar sērijām, kas saistītas ar nedēļas, mēneša utt. Tas parādīsies skaidrāk "Parādības attīstības ass". Vidējais rādītājs, kas aprēķināts palielinātos intervālos, ļauj noteikt galvenās attīstības tendences virzienu un raksturu (izaugsmes paātrinājums vai palēnināšanās).
Slīdošā vidējā metode līdzīgi kā iepriekšējā, taču šajā gadījumā faktiskos līmeņus aizstāj ar vidējiem līmeņiem, kas aprēķināti secīgi kustīgiem (slīdošiem) palielinātiem intervāliem, kas aptver m sērijas līmeņi.
Piemēram, ja mēs pieņemam m=3, tad vispirms aprēķina sērijas pirmo trīs līmeņu vidējo, pēc tam - no tāda paša līmeņu skaita, bet sākot no otrā, tad - sākot no trešā utt. Tādējādi vidējais “slīd” pa dinamikas rindām, pārvietojoties par vienu termiņu. Aprēķināts no m locekļi, mainīgie vidējie rādītāji attiecas uz katra intervāla vidu (centru).
Šī metode novērš tikai nejaušas svārstības. Ja sērijai ir sezonāls vilnis, tas saglabāsies arī pēc izlīdzināšanas, izmantojot slīdošā vidējā metode.
Analītiskā izlīdzināšana. Lai novērstu nejaušas svārstības un noteiktu tendenci, tiek izmantota sēriju līmeņu izlīdzināšana, izmantojot analītiskās formulas (vai analītisko nivelēšanu). Tās būtība ir aizstāt empīriskos (faktiskos) līmeņus ar teorētiskajiem, kas tiek aprēķināti, izmantojot noteiktu vienādojumu, kas pieņemts par matemātisko tendenču modeli, kur teorētiskie līmeņi tiek uzskatīti par laika funkciju: . Šajā gadījumā katrs faktiskais līmenis tiek uzskatīts par divu komponentu summu: , kur ir sistemātisks komponents, kas izteikts ar noteiktu vienādojumu, un ir nejaušs mainīgais, kas izraisa svārstības ap tendenci.
Analītiskās izlīdzināšanas uzdevums ir šāds:
1. Pamatojoties uz faktiskajiem datiem, tāda hipotētiskās funkcijas veida noteikšana, kas visprecīzāk var atspoguļot pētāmā rādītāja attīstības tendenci.
2. Norādītās funkcijas (vienādojuma) parametru atrašana no empīriskiem datiem
3. Aprēķins, izmantojot atrasto teorētisko (saskaņoto) līmeņu vienādojumu.
Konkrētas funkcijas izvēle parasti tiek veikta, pamatojoties uz empīrisko datu grafisko attēlojumu.
Modeļi ir regresijas vienādojumi, kuru parametrus aprēķina, izmantojot mazāko kvadrātu metodi
Tālāk ir sniegti visbiežāk izmantotie regresijas vienādojumi laikrindu saskaņošanai, norādot, kuras konkrētas attīstības tendences tie ir vispiemērotākie atspoguļošanai.
Lai atrastu iepriekš minēto vienādojumu parametrus, ir speciāli algoritmi un datorprogrammas. Jo īpaši, lai atrastu taisnās līnijas vienādojuma parametrus, var izmantot šādu algoritmu:

Ja periodi vai laika momenti ir numurēti tā, lai St = 0, tad iepriekš minētie algoritmi tiks ievērojami vienkāršoti un pārvērsti par

Izlīdzinātie līmeņi diagrammā atradīsies uz vienas taisnas līnijas, kas iet tuvākajā attālumā no šīs dinamiskās sērijas faktiskajiem līmeņiem. Noviržu kvadrātā summa atspoguļo nejaušu faktoru ietekmi.
Izmantojot to, mēs aprēķinām vienādojuma vidējo (standarta) kļūdu:

Šeit n ir novērojumu skaits, un m ir parametru skaits vienādojumā (mums ir divi no tiem - b 1 un b 0).
Galvenā tendence (tendence) parāda, kā sistemātiski faktori ietekmē virknes dinamikas līmeņus, un līmeņu svārstības ap tendenci () kalpo kā atlikušo faktoru ietekmes mērs.
Lai novērtētu izmantotā laikrindas modeļa kvalitāti, to arī izmanto Fišera F tests. Tā ir divu dispersiju attiecība, proti, regresijas izraisītās dispersijas attiecība, t.i. pētāmajam faktoram līdz nejaušu iemeslu izraisītai dispersijai, t.i. atlikušā dispersija:

Izvērstā veidā šī kritērija formulu var attēlot šādi:

kur n ir novērojumu skaits, t.i. rindu līmeņu skaits,
m ir parametru skaits vienādojumā, y ir sērijas faktiskais līmenis,
Izlīdzināts rindas līmenis — vidējās rindas līmenis.
Modelis, kas ir veiksmīgāks par citiem, ne vienmēr var būt pietiekami apmierinošs. To par tādu var atpazīt tikai tad, ja tā kritērijs F pārsniedz zināmo kritisko robežu. Šī robeža tiek noteikta, izmantojot F sadalījuma tabulas.
Indeksu būtība un klasifikācija.
Statistikā indekss tiek saprasts kā relatīvs rādītājs, kas raksturo parādības lieluma izmaiņas laikā, telpā vai salīdzinājumā ar jebkuru standartu.
Indeksa attiecības galvenais elements ir indeksētā vērtība. Ar indeksēto vērtību saprot statistiskās kopas raksturlieluma vērtību, kuras maiņa ir izpētes objekts.
Izmantojot indeksus, tiek atrisināti trīs galvenie uzdevumi:
1) sarežģītas parādības izmaiņu novērtējums;
2) atsevišķu faktoru ietekmes uz sarežģītās parādības izmaiņām noteikšana;
3) parādības lieluma salīdzinājums ar pagājušā perioda lielumu, citas teritorijas lielumu, kā arī ar standartiem, plāniem un prognozēm.
Indeksus klasificē pēc 3 kritērijiem:
2) pēc populācijas elementu pārklājuma pakāpes;
3) pēc vispārējo indeksu aprēķināšanas metodēm.
Pēc satura indeksētos daudzumus, indeksi tiek sadalīti kvantitatīvo (apjoma) rādītāju indeksos un kvalitatīvo rādītāju indeksos. Kvantitatīvo rādītāju indeksi - rūpniecības produkcijas fiziskā apjoma, realizācijas fiziskā apjoma, darbinieku skaita u.c. Kvalitatīvo rādītāju indeksi - cenu, izmaksu, darba ražīguma, vidējās darba samaksas u.c.
Atbilstoši iedzīvotāju vienību pārklājuma pakāpei indeksi tiek iedalīti divās klasēs: individuālajā un vispārējā. Lai tos raksturotu, mēs ieviešam šādas konvencijas, kas pieņemtas indeksa metodes izmantošanas praksē:
q- jebkura produkta daudzums (tilpums) fiziskajā izteiksmē ; R- vienības cena; z- ražošanas vienības izmaksas; t— laiks, kas pavadīts, lai ražotu produkta vienību (darba intensitāte) ; w- produkcijas ražošana vērtības izteiksmē laika vienībā; v- produkcijas izlaide fiziskajā izteiksmē laika vienībā; T— kopējais pavadītais laiks vai darbinieku skaits.
Lai atšķirtu, kuram periodam vai objektam pieder indeksētie lielumi, ir pieņemts attiecīgā simbola apakšējā labajā stūrī ievietot apakšindeksus. Tā, piemēram, dinamikas indeksos parasti tiek izmantots apakšindekss 1 salīdzināmajiem periodiem (pašreizējais, atskaites) un periodiem, ar kuriem tiek veikts salīdzinājums,
Individuālie indeksi kalpo, lai raksturotu izmaiņas sarežģītas parādības atsevišķos elementos (piemēram, viena produkta veida izlaides apjoma izmaiņas). Tie atspoguļo relatīvās dinamikas vērtības, saistību izpildi, indeksēto vērtību salīdzinājumu.
Tiek noteikts individuālais produktu fiziskā apjoma indekss
No analītiskā viedokļa dotie individuālie dinamikas indeksi ir līdzīgi pieauguma koeficientiem (likmēm) un raksturo indeksētās vērtības izmaiņas pašreizējā periodā, salīdzinot ar bāzes periodu, t.i., parāda, cik reižu tā ir palielinājusies (samazinājusies) vai cik procenti tas ir pieaugums (samazinājums). Indeksa vērtības ir izteiktas koeficientos vai procentos.
Vispārējais (saliktais) indekss atspoguļo izmaiņas visos sarežģītas parādības elementos.
Kopējais indekss ir indeksa pamatforma. To sauc par agregātu, jo tā skaitītājs un saucējs ir “agregātu” kopa.
Vidējie indeksi, to definīcija.
Papildus apkopotajiem indeksiem statistikā tiek izmantota arī cita to forma - vidējie svērtie indeksi. To aprēķins tiek izmantots, ja pieejamā informācija neļauj aprēķināt vispārējo kopējo indeksu. Tātad, ja nav datu par cenām, bet ir informācija par produkcijas pašizmaksu kārtējā periodā un ir zināmi katrai precei individuālie cenu indeksi, tad vispārējo cenu indeksu nevar noteikt kā summētu, bet ir iespējams lai to aprēķinātu kā vidējo no atsevišķiem. Tādā pašā veidā, ja nav zināmi atsevišķu saražotās produkcijas veidu daudzumi, bet ir zināmi individuālie indeksi un bāzes perioda ražošanas pašizmaksa, tad ražošanas fiziskā apjoma vispārējo indeksu var noteikt kā vidējo svērto. vērtību.
Vidējais indekss -Šis indekss, ko aprēķina kā atsevišķu indeksu vidējo vērtību. Apkopotais indekss ir vispārējā indeksa pamatforma, tāpēc vidējam indeksam ir jābūt identiskam apkopotajam indeksam. Aprēķinot vidējos indeksus, tiek izmantotas divas vidējo rādītāju formas: aritmētiskā un harmoniskā.
Vidējais aritmētiskais indekss ir identisks kopējam indeksam, ja atsevišķo indeksu svari ir kopējā indeksa saucēja vārdi. Tikai šajā gadījumā indeksa vērtība, kas aprēķināta, izmantojot vidējo aritmētisko formulu, būs vienāda ar kopējo indeksu.

