Čerstvo preložená základná učebnica S. Chaikina (preložené bolo druhé americké vydanie z roku 1999) sa plne hlási k udalosti roku 2006 v ruskej literatúre o neuroinformatike. No treba podotknúť, že hoci bol preklad urobený bez zjavných chýb, poznámky pod čiarou-komentáre prekladateľov by nezaškodili na objasnenie terminológie (keďže to isté možno nazvať v neuroinformatike, štatistike a systémovej identifikácii rôznymi slovami, je to potrebné buď zredukovať pojmy na jednu oblasť, alebo uviesť zoznam synoným – nie všetci čitatelia budú mať široký rozhľad). Komentáre by mohli odrážať aj pokrok v oblasti umelých neurónových sietí, ktorý nastal od vydania anglického originálu. Dúfam, že po knihe bude dopyt a pri dotlači vydania sa urobia zmeny. Okrem toho existuje značný počet preklepov v matematických vzorcoch. Táto stránka je venovaná hlavne opravám preklepov. Ale treba si uvedomiť, že neručím za úplnosť tu uvedeného zoznamu nepresností - knihu som čítal "uhlopriečne", v záchvatoch a začiatkoch rôznej miere pozornosť, takže mi môže niečo uniknúť (alebo sa sám pomýliť).
Kapitola 1
- s.32 druhý odsek. Len tu možno slovo „výkon“ chápať ako rýchlosť práce, silu kalkulačky. Ďalej v knihe bude „výkon“ znamenať presnosť, kvalitu neurónovej siete (napríklad na str. 73 v druhom odseku zdola).
- S.35 s.7. „VLSI Implementability“ sa lepšie prekladá nie ako „škálovateľnosť“, ale ako „efektívna implementovateľnosť na VLSI – veľmi veľké integrované obvody“.
- str.39 str.7. Slovo "spike" - "vysunutie, impulz" v ruskej neurovede sa často a zvyčajne jednoducho prepisuje ako "hrot".
- S.49 názov odseku. Možno by bol lepší výraz „riadený graf“ namiesto „riadený graf“.
- C.76 tretí odsek. Namiesto odkazu by tam asi mal byť odkaz na Ashbyho knihu.
- P.99 záver 1. Je potrebné doplniť aj prípad súčasného splnenia rovnakých podmienok a so znakom "
- C.105 odsek 2. Pred (viditeľné) vložte slovo „viditeľné“.
Kapitola 2
- P.94 poznámka pod čiarou 2. Odkaz na je s najväčšou pravdepodobnosťou nesprávny, pretože Nie je to kniha a ani názov veľmi nesedí.
- S.122 posledný odsek. Pousmial sa nad frázou „deformácia štruktúry neurónov“: kým nebude vyhovovať vonkajšia udalosť otrasu mozgu, človek si túto udalosť nebude pamätať. Najpravdepodobnejšie sa tvrdilo, že pamäť sa realizuje iba odpojením synaptických vstupov (koncov) z chápadiel dendritov alebo prepnutím z jedného chápadla na druhé (pojmy z obr. 1.2 až s. 40, keďže tento obrázok sa dobre hodí na ilustráciu ). Tie. naše mozgy sú živé a pohybujúce sa.
- Vzorec C.129 (2,39). Namiesto X by mala byť X.
- C.129 vzorce (2.40), (2.41), (2.44). Horný index musí byť q namiesto m.
- C.137 prvý odsek a vzorec (2.61). E by malo byť uvedené kurzívou. A tiež vo vzorcoch (2.64), (2.65), (2.67), (2.68) na str.138.
- Vzorec P.142 (142). Pridajte 0 za prvú šípku.
- C.142 posledný odsek. Predtým posledné slovo vložte mínus.
- C.147 prvý odsek. | L|=l. Tie. premenlivý l na pravej strane výrazu treba uviesť kurzívou (pretože variant v knihe si to mýli s jednotkou).
- Vzorec P.151 (2,90). Na hornú líniu, po kučeravej ortéze, vložte F.
- Vzorec C.151 (2,91). Predtým vložte „at“. N.
- C.160 posledný odsek v poznámke pod čiarou. „s malým množstvom“ sa nahrádza „s veľkým množstvom“.
Kapitola 3
- S.173 Obr.3.1. Premenné by mali byť uvedené kurzívou v súlade so zápisom prijatým v knihe, pretože tieto premenné sú skalárne.
- S.176 vzorce (3.5), (3.7). Musí byť w* namiesto w* .
- C.176 posledný riadok. S najväčšou pravdepodobnosťou sa musíte odvolať, hoci tento problém možno zvážiť aj v uvedenom.
- S.179 poznámka pod čiarou. Mal by byť "derivát f(w) vzhľadom na w"
- S.180 posledný riadok pred poznámkou pod čiarou. Namiesto toho môže byť lepšie vziať a odkaz môže byť nesprávny.
- Stredný výraz C.184 v hornom riadku vzorca (3.30). Namiesto X(n) by mala byť X(i)
- C.200 odsek za vzorcom (3.59). Smial sa „nerovnosti Gucci-Schwartz“. Mala by tam byť známa Cauchyho nerovnosť z univerzitného priebehu veže.
- C.204 prvý odsek sekcie 3.10 je o transformácii Bayesovho klasifikátora na lineárny separátor v Gaussovom prostredí. Týka sa to podmienky, že kovariančné matice oboch tried sú rovnaké (budú predstavené v časti na str. 207), ale pri slovnom spojení „Gaussovské prostredie“ si zvyčajne pripomínam zovšeobecnenú situáciu dvoch normálnych rozdelení s ľubovoľnými kovariančnými maticami. , keď sa Bayes nemusí zvrhnúť na lineárny oddeľovač, ale poskytne kvadratickú oddeľovaciu plochu.
- Vzorec C.206 (3,77). Ďalej namiesto λ uvedeného vo vzorci sa v texte a na obr. 3.10 niekoľkokrát vytlačí Λ.
- S.216 úloha 3.11. To, čo je dané v hornej hranici súčtu, treba posunúť pod znamienko súčtu (a pred súčtom je možné vybrať mínus). Aj v odseku za týmto vzorcom namiesto w T X by mala byť w T X
Kapitola 4
Môj komentár ku kapitole: nočná mora začiatočníka v neurónových sieťach a optimalizačných metódach aj po opakovanom prečítaní kapitoly a opakovaných pokusoch (zámerne alebo tykaním) pravdepodobne nedokáže správne naprogramovať trénovanie neurónových sietí metódou backpropagation. Autor: najmenej, pri zvažovaní len študentov provinčných technických univerzít je ochotný o tom polemizovať s dosť vysokými stávkami. Prezentácia zmiešala potrebné aj nedôležité veci do kopy, bez zdôrazňovania a prekomplikovania prezentácie (ide o prístup „všetko alebo nič“ namiesto postupného pridávania postupov). Plus veľa empírie. Prečo jednoducho nenačrtnúť techniku výpočtu gradientu komplexnej funkcie (neurónová sieť plus objektívna funkcia nad jej výstupom a v prípade potreby nad vlastnosťami neurónovej siete), potom, ako v kapitole 6, odkázať čitateľov na gradient optimalizačné metódy bez obmedzení (v kapitole 6 sa odkazuje na metódy kvadratického programovania) a uvádza niekoľko historických príkladov správnych a nesprávnych prístupov k použitiu gradientu vypočítaného sieťou z pohľadu teórie gradientovej optimalizácie a maximalizácie rýchlosti konvergencie (miera učenia).
Čo by ste chceli vidieť v kapitole (alebo knihe) navyše. Po prvé, objektívne funkcie iné ako metóda najmenších štvorcov, najmä na trénovanie siete klasifikátorov (napríklad funkcia krížovej entropie). Po druhé, jasnejší výber možnosti mať objektívnu funkciu pozostávajúcu z niekoľkých pojmov: na príklade regularizácie podľa Tichonova prostredníctvom explicitnej minimalizácie okrem samotnej hodnoty chyby aj skalárneho štvorca gradientu výstupných signálov siete. váhami synapsií (spoločná práca LeCuna a Druckera 1991-92), buď na príklade metódy Flat minina search Hochreitera a Schmidhubera, alebo na príklade metódy CLearning na čistenie vstupných signálov siete od Andreasa Weigenda et. al. Po tretie, podrobnejší popis možnosti výpočtu druhých derivácií v sieti (uvedené práce LeCuna a Druckera, metódy uvedené v recenzii). Po štvrté, podrobnejší popis metód výpočtu informačného obsahu-úžitku rôznych prvkov a signálov v sieti (t.j. určenie informačného obsahu vstupov, možnosť redukcie nielen synapsií pomocou metód opísaných v knihe, ale aj redukcia celých neurónov a existuje aj množstvo iných metód). Po piate, výslovná indikácia (napokon na to čitatelia sami neprídu) o schopnosti vypočítať gradient pomocou vstupných signálov siete (na vyriešenie inverzné problémy na neurónových sieťach trénovaných na riešenie priameho problému, na prezentáciu metódy CLearning). Navyše, pre túto a ďalšie kapitoly, kde vyvstáva úloha učiť sa s učiteľom, podrobnejšie opíšte myšlienku kriviek učenia pre neurónové siete.
Kapitola 5
- P.357 podľa vzorca (5.23). Ďalej na niekoľkých stranách E môžu byť uvedené kurzívou alebo tučným písmom a zmena formy zápisu je dosť nesystematická. Správnejšie, kurzívou, pre E(F), E s (F), E c (F), E(F,h).
- Vzorec C.361 (5,31). Namiesto dolného indexu H by mala byť H .
- S.363 posledný odsek. „...lineárna kombinácia...“ namiesto „...lineárna superpozícia...“.
- Vzorec C.364 (5,43). Odstráňte 1/λ.
- Vzorec P.367 (5,59). σ namiesto δ.
- P.369 podľa vzorca (5.65). Malo by byť znova lineárna kombinácia“ namiesto „lineárnej superpozície“.
- P.373 tretí riadok vzorca (5.74). Pred druhý vložte otváraciu konzolu t i .
- Vzorec C.382 (5,112). V dolnej hranici sumy pridajte „nerovná sa k".
- C.390 názov oddielu 5.12. V rusky hovoriacej vede sa namiesto „regresie jadra“ zvyčajne používajú výrazy „neparametrická regresia“ (tak sa táto metóda štatistiky nazýva v ruštine) alebo „nukleárna regresia“ (ak sa prekladá „do čela“).
- Vzorec S.393 (5,135). Vložte „…pre všetkých…“ ako v (5.139) na nasledujúcej strane.
- S.399 "stredný" odsek. "...algoritmus pre zhlukovanie podľa k-stredná…“, potom sa slovo „priemer“ už nebude preskakovať.
- C.403 neusporiadaný zoznam. Príliš globálne a jednoznačné závery vyvodzujú autori z jedného experimentu, aj keď v mnohom súhlasím.
- S.404 prvá položka v zozname. Nerozumel, hlavne čo sa týka "vplyvu na vstupné parametre". Radšej než väčšiu hodnotuλ, tým menší je vplyv údajov vo všeobecnosti na konečné vlastnosti modelu.
- S.408 prvý odsek. Pochybný odkaz na , možno vhodný .
- С.408 riadok 6 odseku 2. „základná funkcia“ namiesto „základná funkcia“.
Kapitola 6
- S.431 posledná veta pred oddielom 6.4. Nerozumel som „lepšiemu“ z navrhovanej voľby prostredníctvom priemeru vzorky (a zdá sa, že som zároveň dostal tú správnu b 0 nebude možné).
- Vzorec S.434 (6,35). Index i to druhé X nemalo by byt.
- P.435 nečíslované vzorce v Mercerovej vete. Namiesto ψ by malo byť φ.
- S.444 poznámka pod čiarou. Priezvisko Huber sa do ruštiny zvykne prekladať ako Huber, nie Gaber (napr. preklad jeho knihy počas sovietskej éry: Huber, „Robustness in Statistics“).
Kapitola 7 (nedokončená)
- S.459 tretí riadok zhora. Výklad pojmu "slabý algoritmus učenia" je uvedený na str. 467 v druhom odseku zhora.
- C.459 nečíslované pododseky v odseku 2. Výraz „sieť brány“ ako preklad výrazu „bránová sieť“ je príliš neohrabaný, no iná (a zároveň dobrá) možnosť v ruštine neexistuje. Asi by bolo vhodnejšie použiť pojem "vážiaca sieť", ktorý je univerzálny ako pre prípad tvrdého spínania (násobiče 0 alebo 1 pre riadený signál), tak aj pre mäkké riadenie koeficientu útlmu (násobiče z rozsahu ).
- S.463 str.2. Z tejto vety odstraňujeme časticu „nie“ – rozptyl ansámblu je menší ako rozptyl jednotlivých funkcií.
- S.471 prvé riadky. „Výkon“ (pripomíname, že „výkon-výkon“ sa tu chápe nie v zmysle rýchlosti, ale v zmysle presnosti riešenia a zovšeobecnenia – pozri náš komentár na str. 32) pôvodnej metódy zosilnenia. závisí aj od rozvodov vytvorených počas jeho prevádzky pre druhých a ďalších odborníkov.
- C.472 tabuľka 7.2 posledný riadok. Musí byť F plutva ( X)=…
Bibliografia
- Veľakrát sú slová aplikácia, priblíženie, priblíženie, aplikované, podpora, mapovanie, použiteľnosť, horné napísané od jedného p.
- . Správne písanie mená jedného z autorov možno vidieť v .
- . Správne priezvisko Muller je ako jeho menovca.
- . Prvý autor - B u ntine.
- . Vydané v rovnakom NIPS ako .
- . Posledný z autorov je správne menovaný v .
- . Potrebujeme slabosť namiesto týždňa.
- . Posledný autor je správne uvedený v .
- . Prvý - Landa u.
- . Toto je kapitola v knihe.
- . Sch ö lkopf.
- . V názve – „... zaujatosť s termín". V dvojke je napísané správne.
- . V názve – „...gamm na".
- . Opakujte.

V sme popísali najviac jednoduché vlastnosti formálne neuróny. Hovorili sme o tom, že prahová sčítačka presnejšie reprodukuje povahu jedného hrotu a lineárna sčítačka vám umožňuje simulovať odozvu neurónu pozostávajúcu zo série impulzov. Ukázalo sa, že hodnotu na výstupe lineárnej sčítačky možno porovnať s frekvenciou indukovaných špičiek skutočného neurónu. Teraz sa pozrieme na hlavné vlastnosti, ktoré takéto formálne neuróny majú.
Hebbov filter
V nasledujúcom texte sa budeme často odvolávať na modely neurónových sietí. V zásade takmer všetky základné pojmy z teórie neurónových sietí priamo súvisia so štruktúrou skutočného mozgu. Osoba, ktorá čelila určitým úlohám, prišla s mnohými zaujímavými návrhmi neurónových sietí. Evolúcia, triediaca všetky možné nervové mechanizmy, vybrala všetko, čo sa jej ukázalo ako užitočné. Nemalo by byť prekvapujúce, že pre toľko modelov vynájdených človekom možno nájsť jasné biologické prototypy. Keďže naše rozprávanie si nekladie za cieľ žiadne detailné predstavenie teórie neurónových sietí, dotkneme sa len toho najviac spoločné chvíle potrebné opísať hlavné myšlienky. Pre hlbšie pochopenie vrelo odporúčam nahliadnuť do odbornej literatúry. Pre mňa je najlepším tutoriálom o neurónových sieťach Simon Haykin „Neural Networks. Celý kurz“ (Khaikin, 2006).Mnohé modely neurónových sietí sú založené na známom Hebbovom pravidle učenia. Navrhol to fyziológ Donald Hebb v roku 1949 (Hebb, 1949). V trochu voľnej interpretácii to má veľmi jednoduchý význam: spojenia neurónov, ktoré spolu pália, by sa mali posilniť, spojenia neurónov, ktoré pália nezávisle, by sa mali oslabiť.
Výstupný stav lineárnej sčítačky možno zapísať:
Ak inicializujeme počiatočné hodnoty váh s malými hodnotami a dodáme rôzne obrázky ako vstup, nič nám nebráni pokúsiť sa tento neurón trénovať podľa Hebbovho pravidla:
Kde n je diskrétny časový krok, je parameter rýchlosti učenia.
Týmto postupom zvyšujeme váhy tých vstupov, na ktoré je signál aplikovaný, ale robíme to tým silnejšie, čím aktívnejšia je reakcia samotného trénovaného neurónu. Ak nie je žiadna reakcia, potom nie je žiadne učenie.
Je pravda, že takéto váhy budú rásť donekonečna, takže na stabilizáciu možno použiť normalizáciu. Napríklad vydeľte dĺžkou vektora získaného z „nových“ synaptických váh.
Pri takomto učení sa váhy prerozdeľujú medzi synapsie. Podstatu prerozdeľovania ľahšie pochopíte, ak budete zmenu váh sledovať v dvoch krokoch. Po prvé, keď je neurón aktívny, tie synapsie, ktoré prijímajú signál, dostávajú aditívum. Váhy synapsií bez signálu zostávajú nezmenené. Potom všeobecná normalizácia znižuje váhy všetkých synapsií. Ale zároveň synapsie bez signálov strácajú v porovnaní so svojou predchádzajúcou hodnotou a synapsie so signálmi si tieto straty medzi sebou prerozdeľujú.
Hebbovo pravidlo nie je nič iné ako implementácia metódy gradientového zostupu na chybovom povrchu. V skutočnosti nútime neurón, aby sa prispôsobil daným signálom, pričom zakaždým posúvame jeho váhy v smere opačnom k chybe, teda v smere k antigradientu. Aby nás gradientové klesanie priviedlo k lokálnemu extrému bez toho, aby sme ho prestrelili, musí byť rýchlosť klesania dostatočne malá. Čo sa pri učení hebbovského jazyka berie do úvahy maličkosťou parametra .
Malý parameter rýchlosti učenia nám umožňuje prepísať predchádzajúci vzorec ako sériu v:
Ak zahodíme členy druhého rádu a vyššie, dostaneme pravidlo učenia Oja (Oja, 1982):
Pozitívny prídavok je zodpovedný za učenie sa hebbčiny a negatívny za všeobecnú stabilitu. Nahrávanie v tejto forme vám umožní pocítiť, ako je možné takéto školenie realizovať v analógovom prostredí bez použitia výpočtov, fungujúcich len s kladnými a zápornými spojeniami.
Takže takýto extrémne jednoduchý tréning má prekvapivú vlastnosť. Ak postupne znížime rýchlosť učenia, potom váhy synapsií trénovaného neurónu budú konvergovať k takým hodnotám, že jeho výstup začne zodpovedať prvému hlavnému komponentu, ktorý by sme získali, keby sme použili vhodné postupy analýzy hlavných komponentov. na vstupné údaje. Tento dizajn sa nazýva Hebbov filter.
Napríklad, aplikujme pixelový obraz na vstup neurónu, to znamená, porovnajme jeden obrazový bod s každou neurónovou synapsiou. Na vstup neurónu privedieme len dva obrázky – obrázky vertikálnych a horizontálnych čiar prechádzajúcich stredom. Jeden krok učenia – jeden obrázok, jeden riadok, horizontálny alebo vertikálny. Ak sú tieto obrázky spriemerované, dostanete krížik. Ale výsledok tréningu nebude podobný priemerovaniu. Toto bude jeden z riadkov. Ten, ktorý bude na zaslaných obrázkoch bežnejší. Neurón zvýrazní nie spriemerovanie alebo priesečník, ale tie body, ktoré sa najčastejšie vyskytujú spoločne. Ak sú obrázky zložitejšie, výsledok nemusí byť taký jasný. Ale vždy bude hlavnou zložkou.
Tréning neurónu vedie k tomu, že sa na jeho stupniciach zvýrazní (odfiltruje) určitý obrázok. Keď je daný nový signál, čím presnejšia je zhoda medzi signálom a nastavením hmotnosti, tým vyššia je odozva neurónu. Trénovaný neurón možno nazvať detektorovým neurónom. V tomto prípade sa obraz, ktorý je opísaný svojimi váhami, zvyčajne nazýva charakteristický stimul.
Hlavné komponenty
Samotná myšlienka analýzy hlavných komponentov je jednoduchá a dômyselná. Predpokladajme, že máme sled udalostí. Každý z nich popisujeme prostredníctvom jeho vplyvu na senzory, ktorými vnímame svet. Povedzme, že máme senzory, ktoré popisujú funkcie. Všetky udalosti sú pre nás opísané vektormi dimenzie. Každá zložka takéhoto vektora ukazuje na hodnotu zodpovedajúceho i-tého znaku. Spolu tvoria náhodnú premennú X . Tieto udalosti môžeme zobraziť ako body v -rozmernom priestore, kde znaky, ktoré pozorujeme, budú pôsobiť ako osi.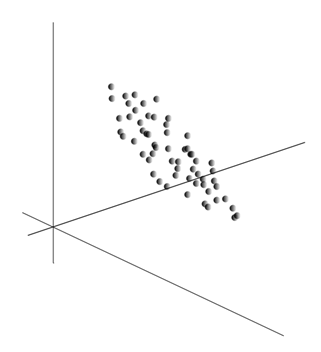
Spriemerovanie hodnôt dáva matematické očakávanie náhodnej premennej X, označené ako E( X). Ak údaje vycentrujeme tak, aby E( X)=0, potom sa mračno bodov sústredí okolo počiatku.
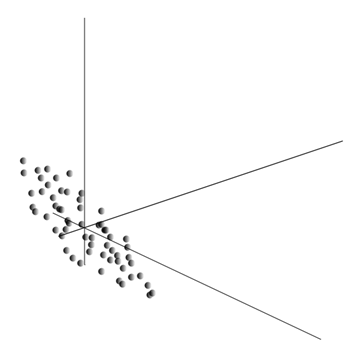
Tento oblak môže byť natiahnutý akýmkoľvek smerom. Po vyskúšaní všetkého možné smery, môžeme nájsť taký, pozdĺž ktorého bude rozptyl údajov maximálny.
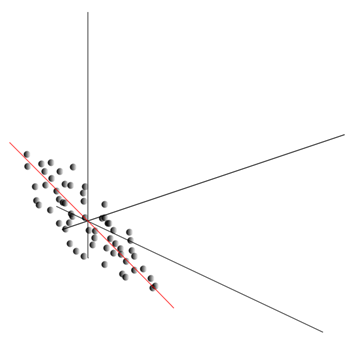
Tento smer teda zodpovedá prvej hlavnej zložke. Samotný hlavný komponent je definovaný jednotkovým vektorom vychádzajúcim z počiatku a zhodujúcim sa s týmto smerom.
Ďalej môžeme nájsť ďalší smer kolmý na prvý komponent tak, že pozdĺž neho je rozptyl tiež maximálny medzi všetkými kolmými smermi. Keď ho nájdeme, dostaneme druhú zložku. Potom môžeme pokračovať v hľadaní za predpokladu, že potrebujeme hľadať medzi smermi kolmými na už nájdené komponenty. Ak boli pôvodné súradnice lineárne nezávislé, potom to môžeme urobiť raz, kým sa neskončí priestorová dimenzia. Dostaneme teda vzájomne ortogonálne komponenty zoradené podľa toho, aké percento rozptylu údajov vysvetľujú.
Prirodzene, výsledné hlavné komponenty odrážajú vnútorné zákonitosti našich údajov. Existujú však jednoduchšie charakteristiky, ktoré tiež popisujú podstatu existujúcich vzorov.
Predpokladajme, že máme celkovo n udalostí. Každá udalosť je opísaná vektorom. Komponenty tohto vektora sú:
Ku každému znameniu si môžete zapísať, ako sa pri jednotlivých udalostiach prejavilo:
Pre akékoľvek dva znaky, na ktorých je popis založený, je možné vypočítať hodnotu ukazujúcu stupeň ich spoločného prejavu. Táto hodnota sa nazýva kovariancia: 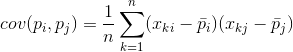
Ukazuje, ako sa odchýlky od priemernej hodnoty jedného zo znakov prejavujú s podobnými odchýlkami druhého znaku. Ak sa stredné hodnoty vlastností rovnajú nule, potom má kovariancia formu: 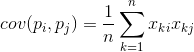
Ak opravíme kovarianciu pre štandardné odchýlky obsiahnuté vo znakoch, dostaneme lineárny korelačný koeficient, nazývaný aj Pearsonov korelačný koeficient: ![]()
Korelačný koeficient má pozoruhodnú vlastnosť. Nadobúda hodnoty od -1 do 1. Okrem toho 1 znamená priamu úmernosť týchto dvoch hodnôt a -1 označuje ich inverzný lineárny vzťah.
Zo všetkých párových kovariancií funkcií môžete vytvoriť kovariančnú maticu, ktorá, ako môžete ľahko vidieť, je matematickým očakávaním produktu: ![]()
Ukazuje sa teda, že pre hlavné komponenty platí:
To znamená, že hlavné zložky alebo, ako sa tiež nazývajú, faktory sú vlastné vektory korelačnej matice. Zodpovedajú svojim vlastným číslam. Zároveň tým viac vlastné číslo, čím väčšie percento rozptylu vysvetľuje tento faktor.
Poznanie všetkých hlavných komponentov pre každú udalosť, ktorá je realizáciou X
, môžeme zapísať jeho projekcie na hlavné komponenty:
Takto je možné reprezentovať všetky počiatočné udalosti v nových súradniciach, súradniciach hlavných komponentov: 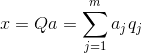
Vo všeobecnosti sa rozlišuje medzi postupom hľadania hlavných komponentov a postupom hľadania základu faktorov a ich následnou rotáciou, čo uľahčuje interpretáciu faktorov, ale keďže tieto postupy sú si ideologicky blízke a dávajú podobný výsledok, obe budeme nazývať faktorová analýza.
Za pomerne jednoduchým postupom faktorovej analýzy sa skrýva veľmi hlboký zmysel. Faktom je, že ak priestorom počiatočných znakov je pozorovaný priestor, potom faktory sú znaky, ktoré síce popisujú vlastnosti okolitého sveta, ale vo všeobecnosti (ak sa nezhodujú s pozorovanými znakmi) sú skryté. subjektov. To znamená, že formálny postup faktorovej analýzy nám umožňuje prejsť od pozorovateľných javov k detekcii javov, ktoré sú síce priamo neviditeľné, no napriek tomu existujú v okolitom svete.
Dá sa predpokladať, že náš mozog aktívne využíva výber faktorov ako jeden z postupov pri poznávaní sveta okolo nás. Izoláciou faktorov získame príležitosť vybudovať nové popisy toho, čo sa s nami deje. Základom týchto nových opisov je prejav v dianí tých javov, ktoré zodpovedajú vybraným faktorom.
Dovoľte mi trochu vysvetliť podstatu faktorov na úrovni domácností. Povedzme, že ste HR manažér. Chodí k vám veľa ľudí a ku každému vyplníte určitý formulár, kde si zapíšete rôzne pozorovateľné údaje o návštevníkovi. Po prečítaní poznámok možno zistíte, že niektoré grafy majú určitý vzťah. Napríklad strihy mužov budú v priemere kratšie ako dámske. Holohlavých stretnete s najväčšou pravdepodobnosťou len medzi mužmi a pery si budú maľovať len ženy. Ak sa vzťahuje na osobné údaje faktorová analýza, potom sa práve pohlavie ukáže ako jeden z faktorov vysvetľujúcich viacero vzorcov naraz. Faktorová analýza vám však umožňuje nájsť všetky faktory, ktoré vysvetľujú korelácie v súbore údajov. To znamená, že popri sexuálnom faktore, ktorý môžeme pozorovať, vyniknú ďalšie, vrátane implicitných, nepozorovateľných faktorov. A ak sa v dotazníku vyslovene objaví pohlavie, tak to druhé dôležitým faktorom zostať medzi riadkami. Posúdením schopnosti ľudí vyjadriť svoje myšlienky, hodnotením ich kariérneho úspechu, analýzou ich známok v diplome a podobnými znakmi dospejete k záveru, že existuje všeobecné hodnotenie inteligencie osoby, ktorá nie je v dotazníku výslovne zaznamenaná. , čo však vysvetľuje mnohé z jeho bodov. Hodnotenie inteligencie je skrytý faktor, hlavná zložka s vysokým vysvetľovacím účinkom. Je zrejmé, že tento komponent nepozorujeme, ale opravujeme funkcie, ktoré s ním súvisia. Po životnej skúsenosti si môžeme podvedome vytvoriť predstavu o intelektu partnera na základe určitých znakov. Postup, ktorý náš mozog v tomto prípade používa, je v skutočnosti faktorová analýza. Pri pozorovaní toho, ako sa určité javy prejavujú spoločne, mozog pomocou formálneho postupu zvýrazňuje faktory ako odraz stabilných štatistických vzorcov, ktoré sú súčasťou sveta okolo nás.
Výber súboru faktorov
Ukázali sme, ako Hebbov filter extrahuje prvú hlavnú zložku. Ukazuje sa, že pomocou neurónových sietí ľahko získate nielen prvé, ale aj všetky ostatné komponenty. Dá sa to urobiť napríklad nasledujúcim spôsobom. Predpokladajme, že máme vstupné funkcie. Zoberme si lineárne neuróny, kde .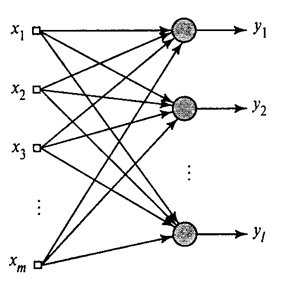
Generalizovaný Hebbov algoritmus(Haikin, 2006)
Prvý neurón natrénujeme ako Hebbov filter, aby extrahoval prvú hlavnú zložku. Ale každý nasledujúci neurón budeme trénovať na signál, z ktorého vylúčime vplyv všetkých predchádzajúcich komponentov.
Neurónová aktivita v kroku n definovaný ako 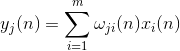
A korekcia na synoptické váhy ako
kde od 1 do a od 1 do .
Pre všetky neuróny to vyzerá ako učenie, podobne ako Hebbov filter. Jediný rozdiel je v tom, že každý nasledujúci neurón nevidí celý signál, ale iba to, čo predchádzajúce neuróny „nevidia“. Tento princíp sa nazýva prehodnotenie. V skutočnosti obnovujeme pôvodný signál pomocou obmedzeného súboru komponentov a nútime nasledujúci neurón, aby videl iba zvyšok, rozdiel medzi pôvodným signálom a obnoveným signálom. Tento algoritmus sa nazýva zovšeobecnený Hebbov algoritmus.
Čo nie je úplne dobré na zovšeobecnenom Hebbovom algoritme, je to, že je príliš „výpočtový“. Neuróny musia byť objednané a výpočet ich aktivity sa musí vykonávať striktne postupne. To nie je veľmi kompatibilné s princípmi mozgovej kôry, kde každý neurón, hoci interaguje s ostatnými, funguje autonómne a kde neexistuje výrazný „centrálny procesor“, ktorý by určoval celkový sled udalostí. Z týchto dôvodov vyzerajú algoritmy nazývané dekorelačné algoritmy o niečo atraktívnejšie.
Predstavte si, že máme dve vrstvy neurónov Z 1 a Z 2 . Aktivita neurónov prvej vrstvy vytvára určitý obraz, ktorý sa premieta pozdĺž axónov do ďalšej vrstvy.
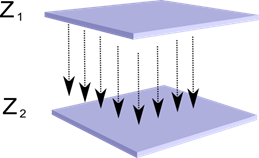
Premietanie jednej vrstvy na druhú
Teraz si predstavte, že každý neurón druhej vrstvy má synaptické spojenie so všetkými axónmi pochádzajúcimi z prvej vrstvy, ak spadajú do hraníc určitého susedstva tohto neurónu (obrázok nižšie). Axóny vstupujúce do takejto oblasti tvoria receptívne pole neurónu. Recepčné pole neurónu je ten fragment všeobecnej aktivity, ktorý má k dispozícii na pozorovanie. Všetko ostatné pre tento neurón jednoducho neexistuje.
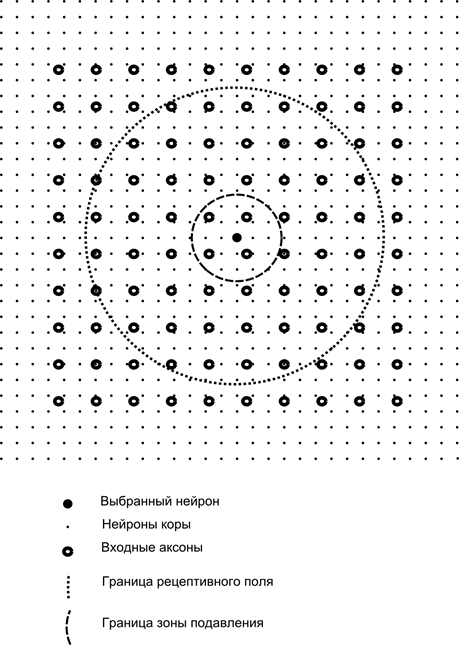
Okrem receptívneho poľa neurónu zavádzame oblasť o niečo menšej veľkosti, ktorú nazývame zóna potlačenia. Prepojme každý neurón s jeho susedmi, ktorí spadajú do tejto zóny. Takéto spojenia sa nazývajú laterálne alebo, podľa terminológie akceptovanej v biológii, laterálne. Urobme bočné spojenia inhibičné, to znamená zníženie aktivity neurónov. Logika ich práce spočíva v tom, že aktívny neurón inhibuje aktivitu všetkých tých neurónov, ktoré spadajú do jeho zóny inhibície.
Excitačné a inhibičné spojenia môžu byť distribuované striktne so všetkými axónmi alebo neurónmi v rámci hraníc zodpovedajúcich oblastí, alebo môžu byť nastavené náhodne, napríklad s hustou náplňou určitého centra a exponenciálnym poklesom hustoty spojení, ako ste vy. vzdialiť sa od toho. Pevná výplň sa ľahšie modeluje, náhodné rozloženie je anatomickejšie z hľadiska organizácie spojení v reálnom kortexe.
Funkciu aktivity neurónov možno zapísať takto:
kde je konečná aktivita, je množina axónov, ktoré spadajú do receptívnej oblasti vybraného neurónu, je množina neurónov, do ktorých zóny supresie vybraný neurón spadá, je sila zodpovedajúcej laterálnej inhibície, ktorá má zápornú hodnotu hodnoty.
Takáto funkcia aktivity je rekurzívna, pretože sa ukazuje, že aktivita neurónov je na sebe závislá. To vedie k tomu, že praktický výpočet sa vykonáva iteračne.
Tréning synaptických váh sa robí podobne ako Hebbov filter:
Bočné závažia sa trénujú podľa anti-Hebbovho pravidla, čím sa zvyšuje inhibícia medzi „podobnými“ neurónmi:
Podstatou tohto návrhu je, že Hebbovské učenie by malo viesť k alokácii hodnôt na stupniciach neurónov zodpovedajúcich prvému hlavnému faktoru charakteristickému pre dodané údaje. Ale neurón je schopný učiť sa v smere akéhokoľvek faktora iba vtedy, ak je aktívny. Keď neurón začne uvoľňovať faktor a podľa toho naň reagovať, začne blokovať aktivitu neurónov, ktoré spadajú do jeho zóny potlačenia. Ak niekoľko neurónov tvrdí, že sú aktivované, potom vzájomná konkurencia vedie k tomu, že najsilnejší neurón vyhráva, pričom utláča všetky ostatné. Ostatné neuróny nemajú inú možnosť, ako sa učiť v tých chvíľach, keď v blízkosti nie sú žiadni susedia vysoká aktivita. Dochádza teda k dekorelácii, to znamená, že každý neurón v rámci oblasti, ktorej veľkosť je určená veľkosťou supresívnej zóny, začína prideľovať svoj vlastný faktor, ortogonálny ku všetkým ostatným. Tento algoritmus sa nazýva algoritmus APEX (Adaptive Principal Component Extraction) (Kung S., Diamantaras K.I., 1990).
Myšlienka laterálnej inhibície je duchom blízka dobre známemu rôzne modely princíp víťaz berie všetko, čo tiež umožňuje dekoreláciu oblasti, v ktorej sa hľadá víťaz. Tento princíp sa používa napríklad vo Fukušimskom neokognitróne, Kohanenových samoorganizujúcich sa mapách a tento princíp sa používa aj pri výučbe známej hierarchickej časovej pamäte Jeffa Hawkinsa.
Môžete určiť víťaza jednoduché porovnanie aktivitu neurónov. Ale takýto zoznam, ktorý sa ľahko implementuje na počítači, trochu nezodpovedá analógiám so skutočnou kôrou. Ale ak si stanovíme cieľ urobiť všetko na úrovni interakcie neurónov bez zapojenia externých algoritmov, potom rovnaký výsledok možno dosiahnuť, ak má neurón okrem laterálnej inhibície susedov aj pozitívnu spätnú väzbu, ktorá ho ďalej vzrušuje. Takáto technika na nájdenie víťaza sa používa napríklad v Grossbergových adaptívnych rezonančných sieťach.
Ak to ideológia neurónovej siete umožňuje, potom je veľmi vhodné použiť pravidlo „víťaz berie všetko“, pretože je oveľa jednoduchšie hľadať maximálnu aktivitu ako iteratívne počítať aktivity, berúc do úvahy vzájomnú inhibíciu.
Je čas ukončiť túto časť. Ukázalo sa, že je to dosť dlhé, ale naozaj som nechcel rozdeliť príbeh, ktorý bol spojený významom. Nečudujte sa KDPV, tento obrázok sa mi spájal zároveň s umelou inteligenciou a s hlavným faktorom.
Tento článok obsahuje materiály – väčšinou v ruskom jazyku – pre základnú štúdiu umelých neurónových sietí.
Umelá neurónová sieť alebo ANN - matematický model, ako aj jeho softvérová či hardvérová implementácia, postavená na princípe organizácie a fungovania biologických neurónových sietí – sietí nervové bunkyžijúci organizmus. Veda o neurónových sieťach existuje už dlho, ale je to práve v súvislosti s najnovšie úspechy vedecko-technickým pokrokom si táto oblasť začína získavať na popularite.
knihy
Začnime zberom klasickým spôsobomštúdium - pomocou kníh. Vybrali sme knihy v ruskom jazyku s veľkým počtom príkladov:
- F. Wasserman, Neurocomputer Engineering: Theory and Practice. 1992
Kniha načrtáva základy budovania neuropočítačov verejnou formou. Je popísaná štruktúra neurónových sietí a rôzne algoritmy na ich ladenie. Samostatné kapitoly sú venované implementácii neurónových sietí. - S. Khaikin, Neurónové siete: Kompletný kurz. 2006
Tu sú zvažované hlavné paradigmy umelých neurónových sietí. Predkladaný materiál obsahuje rigorózne matematické zdôvodnenie všetkých paradigiem neurónových sietí, je ilustrovaný príkladmi, popisom počítačových experimentov, obsahuje súbor praktické úlohy ako aj rozsiahlu bibliografiu.
D. Forsyth, Počítačové videnie. Moderný prístup. 2004
Počítačové videnie je jednou z najžiadanejších oblastí v tomto štádiu vývoja globálnych digitálnych počítačových technológií. Vyžaduje sa vo výrobe, riadení robotov, automatizácii procesov, lekárskych a vojenských aplikáciách, satelitnom dohľade a práci s osobným počítačom, ako je vyhľadávanie digitálnych obrázkov.
Video
Nie je nič dostupnejšie a zrozumiteľnejšie ako vizuálne učenie pomocou videa:
- Ak chcete pochopiť, čo je strojové učenie vo všeobecnosti, pozrite sa sem. tieto dve prednášky od ShaD Yandex.
- Úvod k základným princípom návrhu neurónových sietí – skvelé na pokračovanie v skúmaní neurónových sietí.
- Prednáškový kurz na tému „Počítačové videnie“ z VMK MsÚ. Počítačové videnie je teória a technológia na vytváranie umelých systémov, ktoré detekujú a klasifikujú objekty na obrázkoch a videách. Tieto prednášky možno pripísať úvodu do tejto zaujímavej a komplexnej vedy.
Vzdelávacie zdroje a užitočné odkazy
- Portál umelej inteligencie.
- Laboratórium „Ja som intelekt“.
- Neurónové siete v Matlabe.
- Neurónové siete v Pythone (anglicky):
- Klasifikácia textu s ;
- Jednoduché .
- Neurónová sieť je zapnutá.
Séria našich publikácií na túto tému
Kurz sme už zverejnili #[chránený e-mailom] pomocou neurónových sietí. V tomto zozname sú pre vaše pohodlie zoradené publikácie v poradí štúdia.

