S. Khaikinin juuri käännetty perusoppikirja (toinen amerikkalainen painos 1999 käännettiin) väittää olevansa vuoden 2006 tapahtuma venäläisessä neuroinformatiikan kirjallisuudessa. Mutta on huomattava, että vaikka käännös tehtiin ilman ilmeisiä virheitä, kääntäjien alaviitteet-kommentit eivät haittaisi terminologian selventämistä (koska samaa asiaa voidaan kutsua neuroinformatiikassa, tilastoissa ja järjestelmätunnistuksessa eri sanoilla, tarpeen joko supistaa termit yhteen alueeseen tai antaa luetteloita synonyymeistä - kaikilla lukijoilla ei ole laajaa näkemystä). Kommentit voisivat myös kuvastaa keinotekoisten hermoverkkojen alalla tapahtunutta edistystä englanninkielisen alkuperäisen julkaisun jälkeen. Toivon, että kirjalle tulee kysyntää ja siihen tulee muutoksia, kun painos uusitaan. Lisäksi matemaattisissa kaavoissa on huomattava määrä kirjoitusvirheitä. Tämä sivu on omistettu pääasiassa kirjoitusvirheiden korjaamiseen. Mutta on syytä huomata, että en takaa tässä annetun epätarkkuuksien luettelon täydellisyyttä - luin kirjan "vinosti", kohdistetusti. vaihtelevassa määrin tarkkaavaisuus, jotta voisin unohtaa jotain (tai tehdä itse virheen).
Luku 1
- s.32 toinen kappale. Vain tässä sana "suorituskyky" voidaan ymmärtää työn nopeudeksi, laskimen tehoksi. Edelleen kirjassa "suorituskyky" tarkoittaa tarkkuutta, hermoverkon laatua (esim. s. 73 toisessa kappaleessa alhaalta).
- S.35 s.7. "VLSI Implementability" on parempi käännetty ei "skaalautuvuus", vaan "tehokas toteutettavuus VLSI - erittäin suuret integroidut piirit".
- s.39 s.7. Sana "piikki" - "poisto, impulssi" venäläisessä neurotieteessä transliteroidaan usein ja tavallisesti yksinkertaisesti "piikki".
- P.49 kappaleen otsikko. Ehkä parempi termi olisi "suunnattu graafi" "suunnatun graafin" sijaan.
- C.76 kolmas kappale. Linkin sijasta pitäisi luultavasti olla linkki Ashbyn kirjaan.
- P.99 johtopäätös 1. On myös tarpeen lisätä tapaus, jossa samat ehdot täyttyvät samanaikaisesti ja merkillä "
- C.105 kohta 2. Lisää sana "näkyvä" ennen (näkyvä).
kappale 2
- P.94 alaviite 2. Viittaus on todennäköisesti virheellinen, koska Se ei ole kirja, eikä nimikään oikein sovi.
- P.122 viimeinen kappale. Hän nauroi lauseelle "hermosolujen rakenteen muodonmuutos": ennen kuin ulkoinen aivotärähdyksen tapahtuma sopii henkilölle, tätä tapahtumaa ei muisteta. Todennäköisimmin väitettiin, että muisti toteutuu vain katkaisemalla synaptiset tulot (päätteet) dendriittien lonkeroista tai vaihtamalla lonkerosta toiseen (termit kuvasta 1.2 - s. 40, koska tämä kuvio sopii hyvin havainnollistamiseen ). Nuo. aivomme ovat elossa ja liikkuvat.
- C.129 kaava (2.39). Sijasta X pitäisi olla X.
- C.129 kaavat (2.40), (2.41), (2.44). Yläindeksin on oltava q sijasta m.
- C.137 ensimmäinen kappale ja kaava (2.61). E pitäisi olla kursiivilla. Ja myös kaavoissa (2.64), (2.65), (2.67), (2.68) sivulla 138.
- P.142 kaava (142). Lisää 0 ensimmäisen nuolen jälkeen.
- C.142 viimeinen kappale. Ennen viimeinen sana lisää miinus.
- C.147 ensimmäinen kappale. | L|=l. Nuo. muuttuja l oikealla puolella oleva lauseke on annettava kursiivilla (koska kirjan muunnelma sekoittaa sen yksikköön).
- P.151 kaava (2.90). Lisää yläriville, kiharan aaltosulkeen jälkeen F.
- C.151 kaava (2.91). Lisää "at" ennen N.
- C.160 alaviitteen viimeinen kappale. "pienellä määrällä" korvataan sanalla "suurella määrällä".
Luku 3
- P.173 Kuva 3.1. Muuttujat tulee antaa kursiivilla kirjassa käytetyn merkintätavan mukaisesti, koska nämä muuttujat ovat skalaarisia.
- P.176 kaavat (3.5), (3.7). Täytyy olla w* sen sijaan w* .
- C.176 viimeinen rivi. Todennäköisimmin sinun on viitattava, vaikka tämä ongelma voidaan myös ottaa huomioon määritetyssä.
- P.179 alaviite. Pitäisi olla "johdannainen f(w):stä w:n suhteen"
- P.180 viimeinen rivi ennen alaviitettä. Sen sijaan se voi olla parempi ottaa, ja linkki voi olla virheellinen.
- C.184 välilauseke kaavan (3.30) ylärivillä. Sijasta x(n) pitäisi olla x(i)
- C.200 kappale kaavan (3.59) jälkeen. Nauroi "Gucci-Schwartzin epätasa-arvolle". Tornin yliopistokurssilta pitäisi olla tunnettu Cauchyn epätasa-arvo.
- C.204 osan 3.10 ensimmäinen kappale käsittelee Bayes-luokittimen muuntamista lineaariseksi erottimeksi Gaussin ympäristössä. Tämä viittaa ehtoon, että molempien luokkien kovarianssimatriisit ovat samat (esitetään osiossa s. 207), mutta kun sanon "Gaussin ympäristö", muistan yleensä kahden normaalijakauman yleisen tilanteen mielivaltaisilla kovarianssimatriiseilla. , kun Bayes ei välttämättä rappeudu lineaariseksi erottimeksi, vaan antaa neliöllisen erotuspinnan.
- C.206 kaava (3.77). Lisäksi kaavassa ilmoitetun λ:n sijaan Λ tulostetaan useita kertoja tekstissä ja kuvassa 3.10.
- P.216 tehtävä 3.11. Summan ylärajassa annettu on siirrettävä summan merkin alle (ja miinus voidaan ottaa pois ennen summaa). Myös tämän kaavan jälkeisessä kappaleessa sen sijaan w T x pitäisi olla w T x
Luku 4
Kommenttini luvusta: painajainen, hermoverkkojen ja optimointimenetelmien aloittelija, tuskin pystyisi ohjelmoimaan neuroverkkokoulutusta oikein edes luvun toistuvan lukemisen ja toistuvien kokeilujen jälkeen (tarkoituksellisesti tai tönäisemällä). Tekijä: vähintään, kun ajatellaan vain maakuntien teknisten korkeakoulujen opiskelijat ovat valmiita väittelemään siitä melko korkeilla panoksilla. Esityksessä sekoitettiin kasaan tarpeellisia ja merkityksettömiä asioita korostamatta ja monimutkaistamatta esitystä (menemällä "kaikki tai ei mitään" -lähestymistapalla toimenpiteiden vaiheittaisen lisäämisen sijaan). Lisäksi paljon empiriaa. Mikset yksinkertaisesti hahmottaisi tekniikkaa monimutkaisen funktion gradientin laskentaan (hermoverkko plus objektiivifunktio sen lähdön ja tarvittaessa hermoverkon ominaisuuksien yli), ja sitten, kuten luvussa 6, ohjaa lukijat gradienttiin optimointimenetelmiä ilman rajoituksia (luvussa 6 viitataan kvadraattisen ohjelmoinnin menetelmiin), ja esittää historiallisia esimerkkejä oikeista ja vääristä lähestymistavoista verkon laskeman gradientin käyttöön gradientin optimointiteorian näkökulmasta ja nopeuden maksimoimiseksi. lähentymisestä (oppimisaste).
Mitä haluaisit nähdä luvussa (tai kirjassa) lisäksi. Ensinnäkin muita tavoitefunktioita kuin pienimmän neliösumman menetelmää, erityisesti luokitinverkon opetukseen (esimerkiksi ristientropiafunktio). Toiseksi, selvempi valinta mahdollisuudesta saada useista termeistä koostuva tavoitefunktio: esimerkissä Tihonovin mukaisesta regularisoinnista eksplisiittisen minimoinnin kautta, itse virhearvon lisäksi myös verkon lähtösignaalien gradientin skalaarineliö. synapsipainoilla (LeCunin ja Druckerin yhteinen työ 1991-92), joko Hochreiterin ja Schmidhuberin Flat minina -hakumenetelmän esimerkissä tai Andreas Weigend et:n CLearning-menetelmän esimerkissä verkon tulosignaalien puhdistamiseksi. al. Kolmanneksi, yksityiskohtaisempi kuvaus mahdollisuudesta laskea toiset johdannaiset verkossa (ilmoitetut LeCunin ja Druckerin teokset, katsauksessa luetellut menetelmät). Neljänneksi yksityiskohtaisempi kuvaus menetelmistä verkon eri elementtien ja signaalien tietosisältöhyödyllisyyden laskemiseksi (ts. tulojen tietosisällön määrittäminen, mahdollisuus vähentää synapsien lisäksi kirjassa kuvatuilla menetelmillä, mutta myös kokonaisten hermosolujen pelkistys, ja on myös monia muita menetelmiä). Viidenneksi, eksplisiittinen osoitus (lukijat eivät kuitenkaan ymmärrä sitä itse) kyvystä laskea gradientti verkon tulosignaalien avulla (ratkaista käänteisiä ongelmia neuroverkoissa, jotka on koulutettu ratkaisemaan suoraa ongelmaa, esittämään CLearning-menetelmä). Lisäksi tässä ja muissa luvuissa, joissa herää opettajan kanssa oppimisen tehtävä, kuvaile tarkemmin ajatusta neuroverkkojen oppimiskäyristä.
Luku 5
- P.357 kaavan (5.23) jälkeen. Jatkossa muutamalla sivulla E voidaan antaa kursiivilla tai lihavoituna, ja merkintämuodon muutos on melko epäsysteeminen. Oikeammin kursiivilla for E(F), E s (F), E c (F), E(F,h).
- C.361 kaava (5.31). Alaindeksin sijaan H pitäisi olla H .
- P.363 viimeinen kappale. "...lineaarinen yhdistelmä..." "...lineaarinen superpositio..." sijaan.
- C.364 kaava (5.43). Poista 1/λ.
- P.367 kaava (5.59). σ δ:n sijaan.
- P.369 kaavan (5.65) jälkeen. Pitäisi olla taas lineaarinen yhdistelmä""lineaarisen superposition" sijaan.
- P.373 kaavan (5.74) kolmas rivi. Aseta avaustuki ennen toista t i .
- C.382 kaava (5.112). Lisää summan alarajaan "ei yhtä suuri k".
- C.390 Osion 5.12 otsikko. Venäjänkielisessä tieteessä käytetään "ydinregression" sijaan yleensä termejä "ei-parametrinen regressio" (tätä tilastomenetelmää kutsutaan venäjäksi) tai "ydinregressio" (jos käännetään "otsassa").
- S.393 kaava (5.135). Lisää "…for all…" kuten (5.139) seuraavalla sivulla.
- P.399 "keskikohta". "...algoritmi klusterointiin k-keskikokoinen…", sanaa "keskiarvo" ei enää ohiteta.
- C.403 järjestämätön lista. Kirjoittajat tekevät yhdestä kokeesta liian globaaleja ja yksiselitteisiä johtopäätöksiä, vaikka olen monessa suhteessa samaa mieltä.
- P.404 luettelon ensimmäinen kohta. En ymmärtänyt, varsinkin mitä tulee "vaikutukseen syöttöparametreihin". Mielummin kuin enemmän arvoaλ, sitä vähemmän datalla yleensä on vaikutusta mallin lopullisiin ominaisuuksiin.
- P.408 ensimmäinen kappale. Epäilyttävä viittaus , ehkä sopiva .
- С.408 kohdan 2 rivi 6. "perustoiminto" "perustoiminto" sijaan.
Kappale 6
- P.431 viimeinen virke ennen kohtaa 6.4. En ymmärtänyt ehdotetun valinnan "parempaa" otoksen keskiarvon perusteella (ja näyttää siltä, että saan samalla oikean valinnan b 0 ei ole mahdollista).
- S.434 kaava (6.35). Indeksi i jälkimmäinen x ei pitäisi olla.
- P.435 numeroimattomat kaavat Mercerin lauseessa. ψ:n sijaan pitäisi olla φ.
- P.444 alaviite. Sukunimi Huber käännettiin venäjäksi Huberiksi, ei Gaberiksi (esimerkiksi hänen kirjansa käännös Neuvostoliiton aikana: Huber, "Tilaston vankkaus").
Luku 7 (ei täydellinen)
- P.459 kolmas rivi ylhäältä. Termin "heikko oppimisalgoritmi" tulkinta on annettu sivulla 467 toisessa kappaleessa ylhäältä.
- C.459 2 kohdan numeroimattomat alakohdat. Termi "yhdyskäytäväverkko" käännöksenä termistä "avainnointiverkko" on liian kömpelö, mutta muuta (ja samalla hyvää) vaihtoehtoa ei ole venäjäksi. Olisi luultavasti parempi käyttää termiä "painotusverkko", joka on universaali sekä kovassa kytkennässä (0- tai 1-kertoimet ohjatussa signaalissa) että vaimennuskertoimen pehmeässä säädössä (kertoimet alueelta ).
- S.463 p.2. Poistamme tästä lauseesta partikkelin "ei" - ryhmän varianssi on pienempi kuin yksittäisten funktioiden varianssi.
- P.471 ensimmäiset rivit. Alkuperäisen vahvistusmenetelmän "suorituskyky" (muistutamme, että "suorituskykyä" tässä ei ymmärretä nopeuden, vaan ratkaisun ja yleistyksen tarkkuuden merkityksessä - katso kommenttimme s. 32) riippuu myös sen toiminnan aikana muodostuneista jakaumista toiselle ja seuraaville asiantuntijoille.
- C.472 taulukon 7.2 viimeinen rivi. Täytyy olla F fin( x)=…
Bibliografia
- Sanat sovellus, approksimaatio, lähestymistapa, sovellettu, tuki, kartoitus, soveltuvuus, ylempi kirjoitetaan monta kertaa yhdestä s.
- . Oikea kirjoitus yhden kirjoittajan nimet ovat nähtävissä .
- . Mullerin oikea sukunimi on kuin hänen kaimansa.
- . Ensimmäinen kirjoittaja - B u tine.
- . Julkaistu samassa NIPS:ssä kuin .
- . Viimeinen kirjoittajista on nimetty oikein vuonna .
- . Tarvitsemme heikkoja viikon sijaan.
- . Viimeinen kirjoittaja on nimetty oikein .
- . Ensimmäinen - Landa u.
- . Tämä on luku kirjassa.
- . Sch ö lkopf.
- . Otsikossa - "... bia s termi". Kaksoiskappaleessa se kirjoitetaan oikein.
- . Otsikossa - "…gamm päällä".
- . Toistaa.

Olemme kuvanneet eniten yksinkertaiset ominaisuudet muodolliset neuronit. Puhuimme siitä, että kynnyssummain toistaa tarkemmin yhden piikin luonteen, ja lineaarisen summaimen avulla voit simuloida neuronin vastetta, joka koostuu sarjasta impulsseja. Osoitettiin, että lineaarisen summaimen lähdössä olevaa arvoa voidaan verrata todellisen neuronin indusoituneiden piikkien taajuuteen. Nyt tarkastelemme tärkeimpiä ominaisuuksia, jotka sellaisilla muodollisilla neuroneilla on.
Hebb-suodatin
Seuraavassa viitataan usein hermoverkkomalleihin. Periaatteessa lähes kaikki hermoverkkoteorian peruskäsitteet liittyvät suoraan aivojen rakenteeseen. Tiettyjen tehtävien edessä henkilö keksi monia mielenkiintoisia hermoverkkosuunnitelmia. Evoluutio lajitteli kaikkia mahdollisia hermomekanismeja, valitsi kaiken, mikä osoittautui sille hyödylliseksi. Ei pitäisi olla yllättävää, että niin monille ihmisen keksimille malleille voidaan löytää selkeitä biologisia prototyyppejä. Koska kertomuksemme ei tähtää mihinkään hermoverkkoteorian yksityiskohtaiseen esittelyyn, käsittelemme vain kaikkein yhteisiä hetkiä tarvitaan pääideoiden kuvaamiseen. Syvemmän ymmärryksen saamiseksi suosittelen tutustumista erikoiskirjallisuuteen. Minulle paras hermoverkkojen opetusohjelma on Simon Haykin "Neural Networks. Koko kurssi” (Khaikin, 2006).Monet hermoverkkomallit perustuvat tunnettuun hebbian oppimissääntöön. Sen ehdotti fysiologi Donald Hebb vuonna 1949 (Hebb, 1949). Hieman väljässä tulkinnassa sillä on hyvin yksinkertainen merkitys: yhdessä laukevien hermosolujen yhteyksiä tulee vahvistaa, itsenäisesti syttyvien hermosolujen yhteyksiä heikentää.
Lineaarisen summaimen lähtötila voidaan kirjoittaa:
Jos alustamme painojen alkuarvot pienillä arvoilla ja syötämme erilaisia kuvia, mikään ei estä meitä yrittämästä kouluttaa tätä neuronia Hebb-säännön mukaisesti:
Missä n on diskreetti aika-askel, on oppimisnopeuden parametri.
Tällä toimenpiteellä lisäämme niiden sisääntulojen painoja, joihin signaali kohdistetaan, mutta teemme tämän mitä voimakkaammin, sitä aktiivisemmin itse koulutettu neuroni reagoi. Jos ei reagoida, ei ole oppimista.
Totta, tällaiset painot kasvavat loputtomasti, joten normalisointia voidaan soveltaa stabilointiin. Jaa esimerkiksi "uusista" synaptisista painoista saadun vektorin pituudella.
Tällaisella oppimisella painot jaetaan uudelleen synapsien kesken. Uudelleenjaon olemus on helpompi ymmärtää, jos seuraa painojen muutosta kahdessa vaiheessa. Ensinnäkin, kun neuroni on aktiivinen, ne synapsit, jotka vastaanottavat signaalin, saavat lisäaineen. Ilman signaalia olevien synapsien painot pysyvät ennallaan. Sitten yleinen normalisointi vähentää kaikkien synapsien painoja. Mutta samaan aikaan synapsit ilman signaaleja menettävät verrattuna aiempaan arvoonsa, ja synapsit, joissa on signaaleja, jakavat nämä häviöt uudelleen keskenään.
Hebbin sääntö ei ole muuta kuin gradienttilaskeutumismenetelmän toteutus virhepinnalla. Itse asiassa pakotamme hermosolun sopeutumaan annettuihin signaaleihin siirtäen joka kerta painojaan virhettä vastakkaiseen suuntaan, eli antigradientin suuntaan. Jotta kaltevuuslasku johtaisi meidät paikalliseen ääripisteeseen ylittämättä sitä, laskeutumisnopeuden on oltava riittävän pieni. Mitä hebbian-oppimisessa huomioidaan parametrin pienuudessa.
Oppimisnopeusparametrin pienuuden ansiosta voimme kirjoittaa edellisen kaavan uudelleen sarjaksi:
Jos hylkäämme toisen asteen ja sitä korkeammat ehdot, saamme Ojan oppimissäännön (Oja, 1982):
Positiivinen lisäys vastaa hebbian oppimisesta ja negatiivinen yleisestä vakaudesta. Tallennus tässä muodossa antaa sinun tuntea, kuinka tällainen koulutus voidaan toteuttaa analogisessa ympäristössä ilman laskelmia, toimien vain positiivisilla ja negatiivisilla yhteyksillä.
Joten tällaisella erittäin yksinkertaisella koulutuksella on yllättävä ominaisuus. Jos vähennämme oppimisnopeutta vähitellen, niin harjoitetun hermosolun synapsien painot konvergoivat sellaisiin arvoihin, että sen ulostulo alkaa vastata ensimmäistä pääkomponenttia, joka saataisiin, jos sovellettaisiin sopivia pääkomponenttianalyysimenetelmiä. syöttötietoihin. Tätä mallia kutsutaan Hebb-suodattimeksi.
Sovelletaan esimerkiksi pikselikuvaa neuronin tuloon, eli verrataan yhtä kuvapistettä kuhunkin hermosolun synapsiin. Syötämme neuronin sisääntuloon vain kaksi kuvaa - kuvia pysty- ja vaakasuorista viivoista, jotka kulkevat keskustan läpi. Yksi oppimisvaihe - yksi kuva, yksi viiva, joko vaaka- tai pystysuora. Jos näistä kuvista lasketaan keskiarvo, saat ristin. Mutta harjoittelutulos ei ole samanlainen kuin keskiarvo. Tämä on yksi riveistä. Se, joka on yleisempi lähetetyissä kuvissa. Neuroni ei korosta keskiarvoa tai leikkauskohtaa, vaan niitä pisteitä, jotka esiintyvät useimmiten yhdessä. Jos kuvat ovat monimutkaisempia, tulos ei välttämättä ole yhtä selkeä. Mutta se tulee aina olemaan pääkomponentti.
Neuronin kouluttaminen johtaa siihen, että tietty kuva korostetaan (suodatetaan) sen asteikolla. Kun uusi signaali annetaan, mitä tarkempi vastaavuus signaalin ja painoasetusten välillä on, sitä suurempi on hermosolun vaste. Koulutettua neuronia voidaan kutsua ilmaisinhermosoluksi. Tässä tapauksessa kuvaa, jota kuvataan sen painoilla, kutsutaan yleensä tunnusomaiseksi ärsykkeeksi.
Pääkomponentit
Ajatus pääkomponenttianalyysistä on yksinkertainen ja nerokas. Oletetaan, että meillä on tapahtumasarja. Kuvaamme jokaista niistä sen vaikutuksen kautta antureihin, joilla havaitsemme maailman. Oletetaan, että meillä on antureita, jotka kuvaavat ominaisuuksia . Kaikki tapahtumat meille kuvataan ulottuvuusvektorien avulla. Jokainen tällaisen vektorin komponentti osoittaa vastaavan i:nnen piirteen arvoon. Yhdessä ne muodostavat satunnaismuuttujan X . Voimme kuvata nämä tapahtumat pisteinä -ulotteisessa avaruudessa, jossa havaitsemamme merkit toimivat akseleina.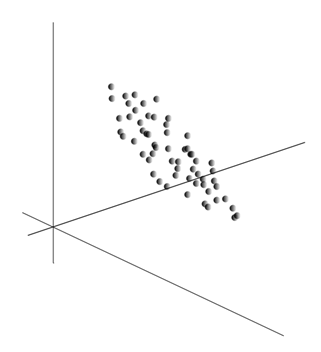
Arvojen keskiarvo antaa satunnaismuuttujan matemaattisen odotuksen X, merkitty E( X). Jos keskitämme tiedot niin että E( X)=0, silloin pistepilvi keskittyy origon ympärille.
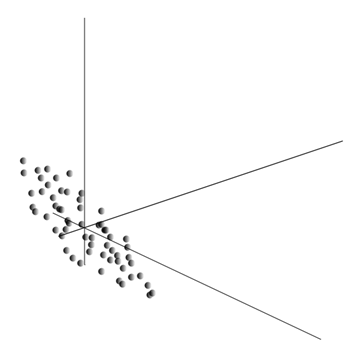
Tämä pilvi voi venyä mihin tahansa suuntaan. Kaikkea kokeiltuaan mahdollisia ohjeita, voimme löytää sellaisen, jota pitkin datan varianssi on suurin.
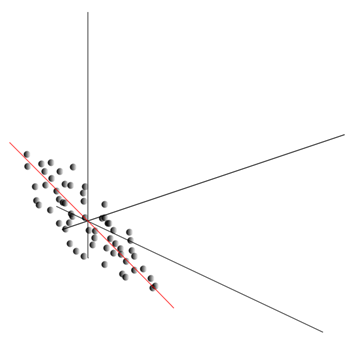
Joten tämä suunta vastaa ensimmäistä pääkomponenttia. Itse pääkomponentti määritellään yksikkövektorilla, joka tulee ulos origosta ja osuu yhteen tämän suunnan kanssa.
Seuraavaksi voidaan löytää toinen suunta, joka on kohtisuoraan ensimmäiseen komponenttiin nähden siten, että sitä pitkin dispersio on myös suurin kaikkien kohtisuorien suuntien joukossa. Kun se löydetään, saamme toisen komponentin. Sitten voimme jatkaa hakua sillä ehdolla, että joudumme etsimään jo löydettyihin komponentteihin nähden kohtisuorassa olevien suuntien joukosta. Jos alkuperäiset koordinaatit olisivat lineaarisesti riippumattomia, voimme tehdä tämän kerran, kunnes avaruusulottuvuus päättyy. Siten saamme keskenään ortogonaaliset komponentit, jotka on järjestetty sen mukaan, kuinka monta prosenttia datavarianssista ne selittävät.
Luonnollisesti tuloksena saadut pääkomponentit heijastavat tietojemme sisäisiä säännönmukaisuuksia. Mutta on yksinkertaisempia ominaisuuksia, jotka kuvaavat myös olemassa olevien mallien olemusta.
Oletetaan, että meillä on yhteensä n tapahtumaa. Jokainen tapahtuma kuvataan vektorilla. Tämän vektorin komponentit ovat:
Voit kirjoittaa jokaiselle merkille, kuinka se ilmeni kussakin tapahtumassa:
Kaikille kahdelle piirteelle, joihin kuvaus perustuu, voidaan laskea arvo, joka osoittaa niiden yhteisen ilmenemisasteen. Tätä arvoa kutsutaan kovarianssiksi: 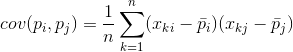
Se osoittaa, kuinka poikkeamat yhden merkin keskiarvosta osuvat ilmentyessään yhteen toisen merkin samankaltaisten poikkeamien kanssa. Jos ominaisuuksien keskiarvot ovat nolla, kovarianssi on muotoa: 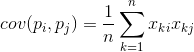
Jos korjaamme ominaisuuksiin sisältyvien keskihajontojen kovarianssin, saadaan lineaarinen korrelaatiokerroin, jota kutsutaan myös Pearson-korrelaatiokertoimeksi: ![]()
Korrelaatiokertoimella on merkittävä ominaisuus. Se ottaa arvot välillä -1 arvoon 1. Lisäksi 1 tarkoittaa kahden arvon suoraa suhteellisuutta ja -1 osoittaa niiden käänteisen lineaarisen suhteen.
Kaikista ominaisuuksien parittaisista kovariansseista voit tehdä kovarianssimatriisin, joka, kuten voit helposti nähdä, on tuotteen matemaattinen odotus: ![]()
Joten käy ilmi, että pääkomponenttien osalta se on totta:
Eli pääkomponentit tai, kuten niitä myös kutsutaan, tekijät ovat korrelaatiomatriisin ominaisvektorit. Ne vastaavat omia numeroitaan. Samalla sitä enemmän oma numero, mitä suurempi varianssiprosentti selittää tämän tekijän.
Kaikkien pääkomponenttien tunteminen kullekin tapahtumalle, joka on toteutus X
, voimme kirjoittaa sen ennusteet pääkomponenteille:
Siten on mahdollista esittää kaikki alkutapahtumat uusissa koordinaateissa, pääkomponenttien koordinaateissa: 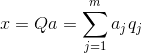
Yleisesti erotetaan pääkomponenttien etsintämenettely ja tekijöiden perustan löytämismenettely ja sen myöhempi kierto, mikä helpottaa tekijöiden tulkintaa, mutta koska nämä menettelyt ovat ideologisesti läheisiä ja antavat samanlaisen tuloksen, niin tekijöiden tulkintaa helpottaa. kutsumme molempia tekijäanalyysiksi.
Melko yksinkertaisen tekijäanalyysin takana on hyvin syvä merkitys. Tosiasia on, että jos alkuominaisuuksien avaruus on havaittu avaruus, niin tekijät ovat ominaisuuksia, jotka vaikka kuvaavatkin ympäröivän maailman ominaisuuksia, mutta yleisessä tapauksessa (jos ne eivät täsmää havaittujen ominaisuuksien kanssa) ovat piilossa. kokonaisuuksia. Toisin sanoen faktorianalyysin muodollinen menettely antaa meille mahdollisuuden siirtyä havaittavista ilmiöistä ilmiöiden havaitsemiseen, vaikka ne ovatkin suoraan näkymättömiä, mutta kuitenkin olemassa ympäröivässä maailmassa.
Voidaan olettaa, että aivomme käyttävät aktiivisesti tekijöiden valintaa yhtenä menettelynä ympärillämme olevasta maailmasta. Eristämällä tekijät saamme mahdollisuuden rakentaa uusia kuvauksia siitä, mitä meille tapahtuu. Näiden uusien kuvausten perustana on valittuja tekijöitä vastaavien ilmiöiden ilmentyminen tapahtumissa.
Selitän hieman kotitaloustason tekijöiden olemusta. Oletetaan, että olet henkilöstöjohtaja. Monet ihmiset tulevat luoksesi ja jokaiselle täytät tietyn lomakkeen, johon kirjoitat erilaisia havaittavia tietoja vierailijasta. Kun olet tarkistanut muistiinpanosi, saatat huomata, että joillakin kaavioilla on tietty suhde. Esimerkiksi miesten hiustenleikkaukset ovat keskimäärin lyhyempiä kuin naisten. Todennäköisesti tapaat kaljuja vain miesten keskuudessa, ja vain naiset maalaavat huulensa. Jos sitä sovelletaan henkilötietoihin tekijäanalyysi, silloin sukupuoli on yksi niistä tekijöistä, jotka selittävät useita kuvioita kerralla. Mutta tekijäanalyysin avulla voit löytää kaikki tekijät, jotka selittävät tietojoukon korrelaatiot. Tämä tarkoittaa, että havaitsemamme sukupuolitekijän lisäksi muut erottuvat joukosta, mukaan lukien implisiittiset, havaitsemattomat tekijät. Ja jos sukupuoli esiintyy nimenomaisesti kyselyssä, niin toinen tärkeä tekijä pysy rivien välissä. Arvioimalla ihmisten kykyä ilmaista ajatuksiaan, arvioimalla heidän uransa menestystä, analysoimalla heidän arvosanojaan tutkintotodistuksessa ja vastaavia merkkejä, tulet siihen johtopäätökseen, että on olemassa yleinen arvio ihmisen älykkyydestä, jota ei ole nimenomaisesti kirjattu kyselyyn. , mutta se selittää monet sen kohdat. Älykkyyden arviointi on piilotettu tekijä, pääkomponentti, jolla on suuri selittävä vaikutus. Ilmeisesti emme tarkkaile tätä komponenttia, mutta korjaamme sen kanssa korreloivat merkit. Elämänkokemuksella voimme alitajuisesti muodostaa käsityksen keskustelukumppanin älystä tiettyjen merkkien perusteella. Menettely, jota aivomme käyttää tässä tapauksessa, on itse asiassa tekijäanalyysi. Tarkkailemalla, kuinka tietyt ilmiöt ilmenevät yhdessä, aivot muodollista menettelyä käyttäen tunnistavat tekijät ympärillämme olevaan maailmaan luontaisten vakaiden tilastollisten mallien heijastuksena.
Tekijäjoukon valinta
Olemme osoittaneet, kuinka Hebb-suodatin erottaa ensimmäisen pääkomponentin. Osoittautuu, että hermoverkkojen avulla voit helposti saada paitsi ensimmäisen, myös kaikki muut komponentit. Tämä voidaan tehdä esimerkiksi seuraavalla tavalla. Oletetaan, että meillä on syöttöominaisuuksia. Otetaan lineaariset neuronit, joissa .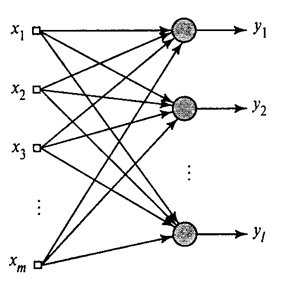
Yleistetty Hebb-algoritmi(Haikin, 2006)
Koulutamme ensimmäisen neuronin Hebb-suodattimeksi, jotta se erottaa ensimmäisen pääkomponentin. Mutta me harjoitamme jokaista seuraavaa neuronia signaalilla, josta suljemme pois kaikkien aiempien komponenttien vaikutuksen.
Hermoston aktiivisuus vaiheessa n määritelty 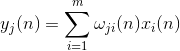
Ja synoptisten painojen korjaus as
missä 1 - , ja 1 - .
Kaikille neuroneille tämä näyttää oppimiselta, samanlaiselta kuin Hebb-suodatin. Ainoa ero on, että jokainen seuraava hermosolu ei näe koko signaalia, vaan vain sen, mitä aiemmat neuronit "eivät nähneet". Tätä periaatetta kutsutaan uudelleenarviointiksi. Itse asiassa palautamme alkuperäisen signaalin käyttämällä rajoitettua komponenttijoukkoa ja pakotamme seuraavan neuronin näkemään vain loppuosan, alkuperäisen signaalin ja palautetun signaalin välisen eron. Tätä algoritmia kutsutaan yleistetyksi Hebb-algoritmiksi.
Yleistetyssä Hebb-algoritmissa ei ole aivan hyvää, että se on luonteeltaan liian "laskennallinen". Neuronit on tilattava ja niiden aktiivisuuden laskeminen on suoritettava tiukasti peräkkäin. Tämä ei ole kovin yhteensopiva aivokuoren periaatteiden kanssa, jossa jokainen neuroni toimii itsenäisesti, vaikka onkin vuorovaikutuksessa muiden kanssa, ja jossa ei ole selkeää "keskusprosessoria", joka määrittäisi tapahtumien yleisen järjestyksen. Näistä syistä dekorrelaatioalgoritmeiksi kutsutut algoritmit näyttävät hieman houkuttelevammilta.
Kuvittele, että meillä on kaksi kerrosta hermosoluja Z1 ja Z2. Ensimmäisen kerroksen neuronien aktiivisuus muodostaa tietyn kuvan, joka projisoidaan aksoneja pitkin seuraavaan kerrokseen.
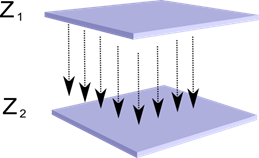
Yhden kerroksen projisointi toiseen
Kuvittele nyt, että jokaisella toisen kerroksen neuronilla on synaptiset yhteydet kaikkien ensimmäisestä kerroksesta tulevien aksonien kanssa, jos ne ovat tämän neuronin tietyn naapuruston rajoissa (kuva alla). Tällaiselle alueelle tulevat aksonit muodostavat hermosolun vastaanottavan kentän. Neuronin vastaanottava kenttä on se yleisen toiminnan fragmentti, joka on sen käytettävissä havainnointia varten. Kaikkea muuta tälle neuronille ei yksinkertaisesti ole olemassa.
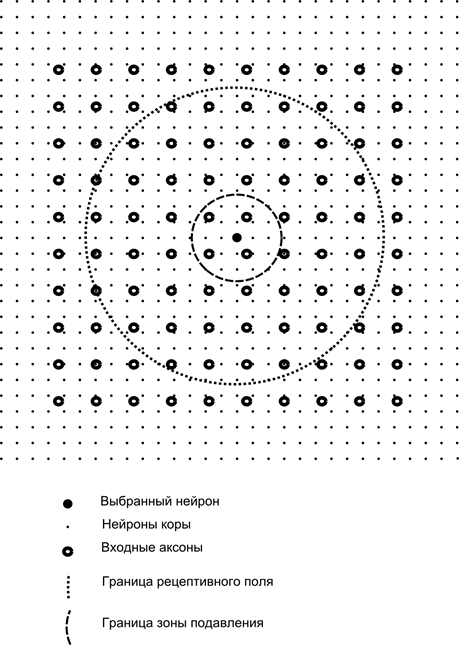
Neuronin reseptiivisen kentän lisäksi esittelemme hieman pienemmän alueen, jota kutsumme suppressiivyöhykkeeksi. Yhdistetään jokainen neuroni naapureihinsa, jotka kuuluvat tälle vyöhykkeelle. Tällaisia yhteyksiä kutsutaan lateraaliseksi tai biologiassa hyväksytyn terminologian mukaan lateraaliseksi. Tehdään lateraalisista yhteyksistä inhiboiva, eli alentava neuronien aktiivisuutta. Heidän työnsä logiikka on, että aktiivinen neuroni estää kaikkien niiden neuronien toimintaa, jotka kuuluvat sen estoalueelle.
Kiihottavat ja estävät yhteydet voidaan jakaa tiukasti kaikkien aksonien tai neuronien kanssa vastaavien alueiden rajojen sisällä, tai ne voidaan asettaa satunnaisesti, esimerkiksi tietyn keskuksen tiheällä täytöllä ja yhteyksien tiheyden eksponentiaalisella laskulla. siirtyä pois siitä. Kiinteä täyttö on helpompi mallintaa, satunnainen jakautuminen on anatomisempaa todellisen aivokuoren yhteyksien organisoinnin kannalta.
Hermosolujen aktiivisuusfunktio voidaan kirjoittaa seuraavasti:
missä on lopullinen aktiivisuus, on joukko aksoneja, jotka putoavat valitun hermosolun reseptiiviselle alueelle, on joukko neuroneja, joiden suppressiivyöhykkeelle valittu hermosolu putoaa, on vastaavan lateraalisen eston voimakkuus, joka saa negatiivisen arvot.
Tällainen aktiivisuusfunktio on rekursiivinen, koska hermosolujen aktiivisuus osoittautuu riippuvaiseksi toisistaan. Tämä johtaa siihen, että käytännön laskenta suoritetaan iteratiivisesti.
Synaptisten painojen harjoittelu tapahtuu samalla tavalla kuin Hebb-suodatin:
Sivupainoja harjoitetaan anti-Hebbian säännön mukaisesti, mikä lisää "samankaltaisten" neuronien välistä estoa:
Tämän suunnittelun ydin on, että hebbian-oppimisen pitäisi johtaa arvojen allokointiin hermosolujen asteikoilla, jotka vastaavat toimitetun datan ensimmäistä päätekijää. Mutta neuroni pystyy oppimaan minkä tahansa tekijän suuntaan vain, jos se on aktiivinen. Kun hermosolu alkaa vapauttaa tekijää ja vastaavasti reagoida siihen, se alkaa estää sen suppressiivyöhykkeelle kuuluvien hermosolujen toiminnan. Jos useat neuronit väittävät olevansa aktivoituneita, keskinäinen kilpailu johtaa siihen, että vahvin hermosolu voittaa, samalla kun se sortaa kaikkia muita. Muilla hermosoluilla ei ole muuta vaihtoehtoa kuin oppia niinä hetkinä, kun lähistöllä ei ole naapureita korkea aktiivisuus. Siten tapahtuu dekorrelaatiota, eli jokainen alueen hermosolu, jonka koko määräytyy suppressiivyöhykkeen koon mukaan, alkaa allokoida omaa tekijäänsä, joka on ortogonaalinen kaikille muille. Tätä algoritmia kutsutaan Adaptive Principal Component Extraction (APEX) -algoritmiksi (Kung S., Diamantaras K.I., 1990).
Ajatus lateraalisesta estämisestä on hengeltään lähellä tunnettua eri malleja voittaja vie kaiken -periaate, joka mahdollistaa myös sen alueen koristelun, josta voittajaa etsitään. Tätä periaatetta käytetään mm. Fukushima neocognitronissa, Kohasen itseorganisoituvissa kartoissa, ja tätä periaatetta käytetään myös Jeff Hawkinsin tunnetun hierarkkisen ajallisen muistin opettamisessa.
Voit määrittää voittajan yksinkertainen vertailu neuronien toimintaa. Mutta tällainen luettelo, joka on helppo toteuttaa tietokoneella, ei vastaa jonkin verran analogioita todellisen aivokuoren kanssa. Mutta jos asetamme itsellemme tavoitteeksi tehdä kaiken neuronien vuorovaikutuksen tasolla ilman ulkoisia algoritmeja, niin sama tulos voidaan saavuttaa, jos naapureiden lateraalisen eston lisäksi neuronilla on positiivinen palaute, joka kiihottaa sitä entisestään. Tällaista voittajan löytämistekniikkaa käytetään esimerkiksi Grossbergin adaptiivisissa resonanssiverkoissa.
Jos hermoverkon ideologia sallii tämän, on erittäin kätevää käyttää "voittaja vie kaiken" -sääntöä, koska maksimiaktiivisuuden etsiminen on paljon helpompaa kuin toimintojen iteratiivinen laskeminen keskinäisen eston huomioon ottaen.
On aika lopettaa tämä osa. Se osoittautui riittävän pitkäksi, mutta en todellakaan halunnut hajottaa merkityksiä yhdistävää kerrontaa. Älä ihmettele KDPV:tä, tämä kuva liittyi minulle samanaikaisesti tekoälyyn ja päätekijään.
Tämä artikkeli sisältää materiaalia - enimmäkseen venäjänkielistä - keinotekoisten hermoverkkojen perustutkimukseen.
Keinotekoinen hermoverkko tai ANN - matemaattinen malli, sekä sen ohjelmisto- tai laitteistototeutus, joka on rakennettu biologisten hermoverkkojen organisoinnin ja toiminnan periaatteelle - verkot hermosolut elävä organismi. Tiede neuroverkoista on ollut olemassa jo kauan, mutta se liittyy juuri siihen uusimmat saavutukset tieteen ja teknologian kehityksen myötä tämä ala on alkanut saada suosiota.
Kirjat
Aloitetaan kokoelmasta klassisella tavalla opiskella - kirjojen avulla. Olemme valinneet venäjänkielisiä kirjoja suurella määrällä esimerkkejä:
- F. Wasserman, Neurocomputer Engineering: Theory and Practice. 1992
Kirjassa hahmotellaan neurotietokoneiden rakentamisen perusteet julkisessa muodossa. Kuvataan hermoverkkojen rakennetta ja erilaisia algoritmeja niiden virittämiseen. Neuroverkkojen toteutukselle on omistettu erilliset luvut. - S. Khaikin, Neuroverkot: Suorita kurssi. 2006
Tässä tarkastellaan keinotekoisten hermoverkkojen pääparadigmoja. Esitetty materiaali sisältää tarkan matemaattisen perustelun kaikille hermoverkkoparadigmille, on havainnollistettu esimerkein, kuvauksen tietokonekokeista, sisältää joukon käytännön tehtäviä sekä laaja bibliografia.
D. Forsyth, Computer Vision. Moderni lähestymistapa. 2004
Tietokonenäkö on yksi kysytyimmistä alueista globaalin digitaalisen tietokoneteknologian kehityksen tässä vaiheessa. Sitä tarvitaan valmistuksessa, robottien ohjauksessa, prosessiautomaatiossa, lääketieteellisissä ja sotilaallisissa sovelluksissa, satelliittivalvonnassa ja tietokoneissa, kuten digitaalisessa kuvahaussa.
Video
Mikään ei ole helpompaa ja ymmärrettävämpää kuin visuaalinen oppiminen videon avulla:
- Katso tästä, mitä koneoppiminen yleensä on. nämä kaksi luentoa Shad Yandexistä.
- Johdanto hermoverkkojen suunnittelun perusperiaatteisiin – erinomainen hermoverkkojen tutkimisen jatkamiseen.
- Luentokurssi aiheesta "Computer Vision" VMK MSU:lta. Tietokonenäkö on teoria ja tekniikka keinotekoisten järjestelmien luomiseksi, jotka havaitsevat ja luokittelevat kohteet kuvissa ja videoissa. Nämä luennot voidaan katsoa johdatukseksi tähän mielenkiintoiseen ja monimutkaiseen tieteeseen.
Koulutusresursseja ja hyödyllisiä linkkejä
- Tekoälyportaali.
- Laboratorio "Minä olen äly".
- Neuroverkot Matlabissa.
- Hermoverkot Pythonissa (englanniksi):
- Tekstin luokittelu ;
- Yksinkertainen.
- Hermoverkko päällä.
Sarja julkaisujamme aiheesta
Olemme jo julkaisseet kurssin #hermoverkko@tproger hermoverkkojen kautta. Tässä luettelossa julkaisut on järjestetty avuksesi opiskelujärjestykseen.

