Viisaat matemaatikot ja tilastotieteilijät keksivät luotettavamman indikaattorin, vaikkakin hieman eri tarkoitukseen - keskimääräinen lineaarinen poikkeama. Tämä indikaattori kuvaa tietojoukon arvojen leviämisen mittaa niiden keskiarvon ympärillä.
Tietojen leviämisen mittarin näyttämiseksi sinun on ensin määritettävä, mihin tämä juuri leviäminen katsotaan suhteessa - yleensä tämä on keskiarvo. Seuraavaksi sinun on laskettava, kuinka kaukana analysoidun tietojoukon arvot ovat kaukana keskiarvosta. On selvää, että jokainen arvo vastaa tiettyä poikkeamaa, mutta olemme myös kiinnostuneita yleisestä arviosta, joka kattaa koko populaation. Siksi keskimääräinen poikkeama lasketaan tavallisen aritmeettisen keskiarvon kaavalla. Mutta! Mutta poikkeamien keskiarvon laskemiseksi ne on ensin lisättävä. Ja jos lisäämme positiiviset ja negatiiviset luvut, ne kumoavat toisensa ja niiden summa on yleensä nolla. Tämän välttämiseksi kaikki poikkeamat otetaan modulo, eli kaikista negatiivisista luvuista tulee positiivisia. Nyt keskipoikkeama näyttää yleisen arvojen hajoamisen mittaa. Tämän seurauksena keskimääräinen lineaarinen poikkeama lasketaan kaavalla:
a on keskimääräinen lineaarinen poikkeama,
x- analysoitu indikaattori, jonka päällä on viiva - indikaattorin keskiarvo,
n on arvojen lukumäärä analysoidussa tietojoukossa,
summausoperaattori, toivottavasti, ei pelota ketään.
Määritetyn kaavan avulla laskettu keskimääräinen lineaarinen poikkeama kuvastaa keskimääräistä absoluuttista poikkeamaa tämän populaation keskiarvosta.

Kuvan punainen viiva on keskiarvo. Jokaisen havainnon poikkeamat keskiarvosta on merkitty pienillä nuolilla. Ne otetaan modulo ja summataan. Sitten kaikki jaetaan arvojen lukumäärällä.
Kuvan täydentämiseksi on annettava vielä yksi esimerkki. Oletetaan, että on yritys, joka valmistaa pistokkaita lapioihin. Jokaisen hakkeen tulee olla 1,5 metriä pitkä, mutta mikä tärkeintä, kaikkien on oltava samanlaisia tai vähintään, plus tai miinus 5 cm. Kuitenkin huolimattomat työntekijät sahaavat joko 1,2 m tai 1,8 m. Kesäasukkaat ovat tyytymättömiä. Yrityksen johtaja päätti tehdä tilastollisen analyysin hakkuiden pituudesta. Valitsin 10 kappaletta ja mittasin niiden pituuden, löysin keskiarvon ja lasken keskimääräisen lineaaripoikkeaman. Keskiarvo osoittautui juuri oikeaksi - 1,5 m. Mutta keskimääräinen lineaarinen poikkeama osoittautui 0,16 m. Joten käy ilmi, että jokainen leikkaus on pidempi tai lyhyempi kuin tarvitaan keskimäärin 16 cm. On puhuttavaa työntekijöiden kanssa. Itse asiassa en ole nähnyt tämän indikaattorin todellista käyttöä, joten keksin esimerkin itse. Tilastoissa on kuitenkin sellainen indikaattori.
Dispersio
Kuten keskimääräinen lineaarinen poikkeama, varianssi heijastaa myös sitä, missä määrin data jakautuu keskiarvon ympärille.
Varianssin laskentakaava näyttää tältä:
 (muunnelmasarjalle (painotettu varianssi))
(muunnelmasarjalle (painotettu varianssi))
 (ryhmittämättömille tiedoille (yksinkertainen varianssi))
(ryhmittämättömille tiedoille (yksinkertainen varianssi))
Missä: σ 2 - dispersio, Xi– analysoimme neliö-indikaattorin (ominaisuusarvo), – indikaattorin keskiarvon, f i – arvojen lukumäärän analysoitavassa tietojoukossa.
Varianssi on poikkeamien keskineliö.
Ensin lasketaan keskiarvo, sitten kunkin perusviivan ja keskiarvon välinen ero otetaan, neliötetään, kerrotaan vastaavan ominaisarvon taajuudella, lisätään ja jaetaan sitten perusjoukon arvojen lukumäärällä.
Kuitenkin sisään puhdas muoto, kuten aritmeettinen keskiarvo tai indeksi, varianssia ei käytetä. Se on pikemminkin apu- ja väliindikaattori, jota käytetään muuntyyppisiin tilastollisiin analyyseihin.
Yksinkertaistettu tapa laskea varianssi
![]()
keskihajonta
Varianssin käyttämiseksi data-analyysissä siitä otetaan neliöjuuri. Kävi ilmi ns keskihajonta.

Muuten, keskihajontaa kutsutaan myös sigmaksi - kreikkalaisesta kirjaimesta, joka tarkoittaa sitä.
Keskihajonta luonnehtii luonnollisesti myös datan hajonnan mittaa, mutta nyt (toisin kuin hajonta) sitä voidaan verrata alkuperäiseen dataan. Tilastojen keskineliöindikaattorit antavat yleensä tarkempia tuloksia kuin lineaariset. Keskimääräinen siis keskihajonta on tarkempi tiedon sirontamitta kuin keskimääräinen lineaarinen poikkeama.
$X$. Aluksi muistetaan seuraava määritelmä:
Määritelmä 1
Väestö- joukko tietyn tyyppisiä satunnaisesti valittuja objekteja, joille suoritetaan havaintoja satunnaismuuttujan tiettyjen arvojen saamiseksi, jotka suoritetaan muuttumattomissa olosuhteissa tutkittaessa yhtä tietyn tyyppistä satunnaismuuttujaa.
Määritelmä 2
Yleinen varianssi- aritmeettinen keskiarvo yleisen populaation muunnelman arvojen keskiarvosta poikkeamien neliöistä.
Olkoon muunnelman $x_1,\ x_2,\dots ,x_k$ arvoilla vastaavasti taajuudet $n_1,\ n_2,\dots ,n_k$. Sitten yleinen varianssi lasketaan kaavalla:
Harkitse erikoistapaus. Olkoon kaikki muunnelmat $x_1,\ x_2,\dots ,x_k$ erillisiä. Tässä tapauksessa $n_1,\ n_2,\dots ,n_k=1$. Saamme, että tässä tapauksessa yleinen varianssi lasketaan kaavalla:
Tähän käsitteeseen liittyy myös yleisen keskihajonnan käsite.
Määritelmä 3
Yleinen keskihajonta
\[(\sigma )_r=\sqrt(D_r)\]
Otosvarianssi
Annetaan esimerkkijoukko satunnaismuuttujan $X$ suhteen. Aluksi muistetaan seuraava määritelmä:
Määritelmä 4
Otospopulaatio-- osa valituista objekteista yleisestä populaatiosta.
Määritelmä 5
Otosvarianssi- näytepopulaation muunnelman arvojen aritmeettinen keskiarvo.
Olkoon muunnelman $x_1,\ x_2,\dots ,x_k$ arvoilla vastaavasti taajuudet $n_1,\ n_2,\dots ,n_k$. Sitten otosvarianssi lasketaan kaavalla:
Tarkastellaanpa erikoistapausta. Olkoon kaikki muunnelmat $x_1,\ x_2,\dots ,x_k$ erillisiä. Tässä tapauksessa $n_1,\ n_2,\dots ,n_k=1$. Saamme, että tässä tapauksessa otosvarianssi lasketaan kaavalla:
Tähän käsitteeseen liittyy myös näytteen keskihajonnan käsite.
Määritelmä 6
Esimerkki keskihajonnasta-- yleisen varianssin neliöjuuri:
\[(\sigma )_v=\sqrt(D_v)\]
Korjattu varianssi
Korjatun varianssin $S^2$ löytämiseksi on tarpeen kertoa otosvarianssi murtoluvulla $\frac(n)(n-1)$, ts.
Tämä käsite liittyy myös korjatun keskihajonnan käsitteeseen, joka löytyy kaavasta:
Siinä tapauksessa, että muunnelman arvo ei ole diskreetti, vaan ovat intervalleja, niin yleisten tai otosvarianssien laskentakaavoissa $x_i$:n arvoksi otetaan sen välin keskiarvon arvo, johon $ x_i.$ kuuluu
Esimerkki ongelmasta varianssin ja keskihajonnan löytämiseksi
Esimerkki 1
Otospopulaatio saadaan seuraavasta jakautumistaulukosta:
Kuva 1.
Etsi sille otosvarianssi, otoksen keskihajonna, korjattu varianssi ja korjattu keskihajonta.
Tämän ongelman ratkaisemiseksi teemme ensin laskentataulukon:
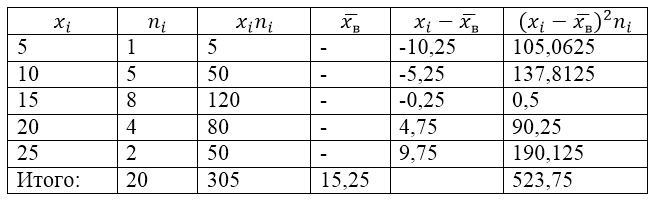
Kuva 2.
$\overline(x_v)$ (näytteen keskiarvo) arvo taulukossa saadaan kaavalla:
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15,25\]
Etsi otosvarianssi kaavalla:
Esimerkki keskihajonnasta:
\[(\sigma )_v=\sqrt(D_v)\noin 5,12\]
Korjattu varianssi:
\[(S^2=\frac(n)(n-1)D)_v=\frac(20)(19)\cdot 26.1875\noin 27.57\]
Korjattu keskihajonta.
keskihajonta(synonyymit: keskihajonta, keskihajonta, keskihajonta; liittyvät termit: keskihajonta, standardi leviäminen) - todennäköisyysteoriassa ja tilastoissa yleisin indikaattori satunnaismuuttujan arvojen hajoamisesta suhteessa sen matemaattiseen odotukseen. Rajoitetuissa arvonäytteiden matriisissa käytetään matemaattisen odotuksen sijasta näytejoukon aritmeettista keskiarvoa.
Tietosanakirja YouTube
-
1 / 5
Keskihajonta mitataan itse satunnaismuuttujan mittayksiköissä ja sitä käytetään aritmeettisen keskiarvon keskivirheen laskennassa, luottamusvälien muodostamisessa, hypoteesien tilastollisessa todentamisessa, satunnaismuuttujien välisen lineaarisen suhteen mittaamisessa. Se määritellään satunnaismuuttujan varianssin neliöjuureksi.
Vakiopoikkeama:
s = n n − 1 σ 2 = 1 n − 1 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s=(\sqrt ((\frac (n)(n-1))\sigma ^(2)))=(\sqrt ((\frac (1)(n-1))\sum _( i=1)^(n)\vasen(x_(i)-(\bar (x))\oikea)^(2)));)- Huomautus: RMS:n (Standard Deviation) ja SRT:n (Standardipoikkeama) nimissä on hyvin usein eroja kaavoineen. Esimerkiksi Python-ohjelmointikielen numPy-moduulissa std()-funktio on kuvattu "standardipoikkeamaksi", kun taas kaava heijastaa keskihajontaa (jakaa näytteen juurella). Excelissä STDEV()-funktio on erilainen (jakamalla n-1:n neliöjuurella).
Standardipoikkeama(satunnaismuuttujan keskihajonnan arvio x suhteessa sen matemaattiseen odotukseen, joka perustuu sen varianssin puolueettomaan arvioon) s (\displaystyle s):
σ = 1 n ∑ i = 1 n (x i − x ¯) 2 . (\displaystyle \sigma =(\sqrt ((\frac (1)(n))\sum _(i=1)^(n)\left(x_(i)-(\bar (x))\oikea) ^(2))).)Missä σ 2 (\displaystyle \sigma ^(2))- dispersio; x i (\displaystyle x_(i)) - i-th näyteelementti; n (\displaystyle n)- otoskoko; - otoksen aritmeettinen keskiarvo:
x ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + … + x n). (\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\lpisteet +x_(n)).)On huomattava, että molemmat arviot ovat puolueellisia. Yleisessä tapauksessa on mahdotonta muodostaa puolueetonta arviota. Kuitenkin puolueettomaan varianssiarvioon perustuva arvio on johdonmukainen.
Standardin GOST R 8.736-2011 mukaisesti standardipoikkeama lasketaan tämän osan toisen kaavan mukaan. Tarkista tulokset.
kolmen sigman sääntö
kolmen sigman sääntö (3 σ (\displaystyle 3\sigma)) - lähes kaikki normaalijakauman satunnaismuuttujan arvot ovat välissä (x ¯ − 3 σ ; x ¯ + 3 σ) (\displaystyle \left((\bar (x))-3\sigma ;(\bar (x))+3\sigma \oikea)). Tarkemmin sanottuna - suunnilleen todennäköisyydellä 0,9973, normaalijakauman satunnaismuuttujan arvo on määritetyllä välillä (edellyttäen, että arvo x ¯ (\displaystyle (\bar (x))) totta, eikä saatu näytteen käsittelyn tuloksena).
Jos todellinen arvo x ¯ (\displaystyle (\bar (x))) tuntematon, sinun tulee käyttää σ (\displaystyle \sigma ), A s. Siten kolmen sigman sääntö muuttuu kolmen sigman säännöksi s .
Keskihajonnan arvon tulkinta
Suurempi keskihajonnan arvo tarkoittaa suurempaa arvojen leviämistä esitetyssä joukossa joukon keskiarvon kanssa; pienempi arvo, vastaavasti, osoittaa, että joukon arvot on ryhmitelty keskiarvon ympärille.
Meillä on esimerkiksi kolme numerojoukkoa: (0, 0, 14, 14), (0, 6, 8, 14) ja (6, 6, 8, 8). Kaikkien kolmen joukon keskiarvot ovat 7 ja standardipoikkeamat 7, 5 ja 1. Viimeisellä joukolla on pieni keskihajonta, koska joukon arvot ovat ryhmitelty keskiarvon ympärille; ensimmäisessä sarjassa on eniten hyvin tärkeä keskihajonta - joukon arvot poikkeavat voimakkaasti keskiarvosta.
Yleisesti ottaen standardipoikkeamaa voidaan pitää epävarmuuden mittana. Esimerkiksi fysiikassa keskihajontaa käytetään jonkin suuren peräkkäisten mittausten sarjan virheen määrittämiseen. Tämä arvo on erittäin tärkeä määritettäessä tutkittavan ilmiön uskottavuutta verrattuna teorian ennustamaan arvoon: jos mittausten keskiarvo poikkeaa suuresti teorian ennustamista arvoista (suuri keskihajonta), niin saadut arvot tai niiden saamismenetelmä on tarkistettava uudelleen. on tunnistettu portfolioriskillä.
Ilmasto
Oletetaan, että kahdessa kaupungissa on sama keskimääräinen vuorokauden enimmäislämpötila, mutta toinen sijaitsee rannikolla ja toinen tasangolla. Rannikkokaupungeissa tiedetään olevan monia erilaisia päivittäisiä maksimilämpötiloja pienempiä kuin sisämaakaupungeissa. Siksi rannikkokaupungin vuorokausilämpötilojen keskihajonta on pienempi kuin toisen kaupungin, huolimatta siitä, että niillä on sama tämän arvon keskiarvo, mikä käytännössä tarkoittaa, että todennäköisyys, että Maksimilämpötila kunkin päivän ilma eroaa enemmän keskiarvosta, korkeampi mantereen sisällä sijaitsevassa kaupungissa.
Urheilu
Oletetaan, että on useita jalkapallojoukkueita, jotka on luokiteltu joidenkin parametrien mukaan, esimerkiksi tehtyjen ja päästettyjen maalien lukumäärän, maalintekomahdollisuuksien jne. mukaan. On todennäköistä, että tämän ryhmän paras joukkue saa parhaat arvot saadaksesi lisää vaihtoehtoja. Mitä pienempi joukkueen keskihajonta kullekin esitetylle parametrille on, sitä ennakoitavampi joukkueen tulos on, sellaiset joukkueet ovat tasapainoisia. Toisaalta joukkueen kanssa suuri arvo keskihajonta on vaikea ennustaa tulosta, mikä puolestaan syynä epätasapainossa mm. vahva puolustus, mutta heikko hyökkäys.
Joukkueen parametrien keskihajonnan avulla voidaan jossain määrin ennustaa kahden joukkueen välisen ottelun tulosta, arvioiden vahvuuksia ja heikkoja puolia komennot ja siten valitut taistelutavat.
Se määritellään aggregaatissa olevan piirteen vaihtelun koon yleistäväksi ominaispiirteeksi. Se on yhtä suuri kuin ominaisuuden yksittäisten arvojen aritmeettisesta keskiarvosta poikkeamien keskineliön neliöjuuri, ts. ja juuri löytyy näin:
1. Ensisijainen rivi:
2. Muunnelmasarja:

Keskihajonnan kaavan muunnos johtaa käytännön laskelmiin kätevämpään muotoon:
Keskiverto keskihajonta määrittää, kuinka paljon tietyt optiot keskimäärin poikkeavat keskiarvostaan, ja lisäksi se on ominaisuuden vaihtelun absoluuttinen mitta ja ilmaistaan samoissa yksiköissä kuin optiot, ja siksi se on hyvin tulkittu.
Esimerkkejä keskihajonnan löytämisestä: ,
Vaihtoehtoisten ominaisuuksien keskihajonnan kaava näyttää tältä:

missä p on niiden yksiköiden osuus perusjoukossa, joilla on tietty attribuutti;
q - niiden yksiköiden osuus, joilla ei ole tätä ominaisuutta.
Keskimääräisen lineaarisen poikkeaman käsite
Keskimääräinen lineaarinen poikkeama määritellään aritmeettiseksi keskiarvoksi absoluuttiset arvot yksittäisten vaihtoehtojen poikkeamat .
1. Ensisijainen rivi:

2. Muunnelmasarja:

missä n:n summa on variaatiosarjan taajuuksien summa.
Esimerkki keskimääräisen lineaarisen poikkeaman löytämisestä:
Keskimääräisen absoluuttisen poikkeaman etu dispersion mittana vaihteluvälillä on ilmeinen, koska tämä mitta perustuu siihen, että kaikki mahdollisia poikkeamia. Mutta tällä indikaattorilla on merkittäviä haittoja. Poikkeamien algebrallisten merkkien mielivaltainen hylkääminen voi johtaa siihen, että tämän indikaattorin matemaattiset ominaisuudet eivät ole kaukana alkeista. Tämä vaikeuttaa suuresti keskimääräisen absoluuttisen poikkeaman käyttöä todennäköisyyslaskentaan liittyvien ongelmien ratkaisemisessa.
Siksi keskimääräistä lineaarista poikkeamaa ominaisuuden vaihtelun mittana käytetään harvoin tilastokäytännössä, nimittäin silloin, kun indikaattoreiden summaus ilman etumerkkejä on taloudellisesti järkevää. Sen avulla analysoidaan esimerkiksi ulkomaankaupan liikevaihtoa, henkilöstön kokoonpanoa, tuotannon rytmiä jne.
juuri tarkoittaa neliötä
RMS käytössä laskea esimerkiksi n neliömäisen osan sivujen keskikokoa, runkojen, putkien jne. keskimääräisiä halkaisijoita. Se on jaettu kahteen tyyppiin.
Neliön keskiarvo on yksinkertainen. Jos, kun ominaisuuden yksittäiset arvot korvataan arvolla keskiarvo on tarpeen pitää alkuperäisten arvojen neliöiden summa vakiona, niin keskiarvo on neliöllinen keskiarvo.
Se on neliöjuuri yksittäisten piirteiden arvojen neliösumman osamäärästä jaettuna niiden lukumäärällä:
Keskimääräinen painotettu neliö lasketaan kaavalla:

jossa f on painon merkki.
Keskimääräinen kuutio
Keskimääräinen kuutio käytetty, esimerkiksi määritettäessä keskimääräistä sivun pituutta ja kuutioita. Se on jaettu kahteen tyyppiin.
Keskimääräinen kuutio yksinkertainen:

Välijakaumasarjan keskiarvoja ja varianssia laskettaessa attribuutin todelliset arvot korvataan välien keskiarvoilla, jotka poikkeavat keskiarvosta. aritmeettiset arvot sisältyy väliin. Tämä johtaa systemaattiseen virheeseen varianssin laskennassa. V.F. Sheppard päätti sen virhe varianssilaskelmassa ryhmitellyn datan soveltamisen aiheuttama 1/12 intervalliarvon neliöstä, sekä ylöspäin että alaspäin varianssin suuruudessa.
Sheppardin muutos tulee käyttää, jos jakauma on lähellä normaalia, viittaa ominaisuuteen, jolla on jatkuva vaihtelu, joka perustuu merkittävään määrään lähtötietoja (n> 500). Kuitenkin sen tosiasian perusteella, että useissa tapauksissa molemmat eri suuntiin vaikuttavat virheet kompensoivat toisiaan, on joskus mahdollista kieltäytyä muutosten tekemisestä.
Mitä pienempi varianssi ja keskihajonta, sitä homogeenisempi populaatio ja sitä tyypillisempi keskiarvo on.
Tilastokäytännössä on usein tarpeen vertailla muunnelmia erilaisia merkkejä. Esimerkiksi työntekijöiden iän ja pätevyyden, palvelusajan ja koon vaihteluiden vertailu on erittäin kiinnostavaa palkat, kustannukset ja tuotto, palvelusaika ja työn tuottavuus jne. Tällaisiin vertailuihin ominaisuuksien absoluuttisen vaihtelun indikaattorit eivät sovellu: työkokemuksen vaihtelua vuosina ilmaistuna on mahdotonta verrata ruplissa ilmaistuun palkkojen vaihteluun.Suorittaaksemme tällaisia vertailuja sekä saman attribuutin vaihtelun vertailuja useissa populaatioissa, joilla on eri aritmeettinen keskiarvo, käytämme suhteellinen indikaattori variaatio - variaatiokerroin.
Rakenteelliset keskiarvot
Tilastollisten jakaumien keskeisen trendin karakterisoimiseksi on usein järkevää käyttää aritmeettisen keskiarvon kanssa attribuutin X tiettyä arvoa, joka tiettyjen jakautumasarjassa sijaitsevien ominaisuuksiensa vuoksi voi luonnehtia sen tasoa.
Tämä on erityisen tärkeää, kun ominaisuuden ääriarvoilla jakelusarjassa on sumeat rajat. Tästä johtuen tarkka määritelmä aritmeettinen keskiarvo on yleensä mahdoton tai erittäin vaikea. Niissä tapauksissa keskitaso voidaan määrittää ottamalla esimerkiksi sellaisen ominaisuuden arvo, joka sijaitsee taajuussarjan keskellä tai joka esiintyy useimmin nykyisessä sarjassa.
Tällaiset arvot riippuvat vain taajuuksien luonteesta, eli jakauman rakenteesta. Ne ovat tyypillisiä sijainniltaan taajuussarjoissa, joten tällaisia arvoja pidetään jakelukeskuksen ominaisuuksina ja siksi ne on määritelty rakenteellisiksi keskiarvoiksi. Niitä käytetään opiskelemaan sisäinen rakenne ja attribuuttiarvojen jakelusarjan rakenne. Näitä indikaattoreita ovat mm.
Täydellisin vaihtelun ominaisuus on standardipoikkeama, jota kutsutaan standardiksi (tai standardipoikkeamaksi). Standardipoikkeama() on yhtä suuri kuin yksittäisten piirrearvojen aritmeettisesta keskiarvosta poikkeamien keskineliön neliöjuuri:
Keskihajonta on yksinkertainen:


Painotettua keskihajontaa sovelletaan ryhmiteltyihin tietoihin:

Keskineliön ja keskimääräisen lineaarisen poikkeaman välillä normaalijakauman olosuhteissa tapahtuu seuraava suhde: ~ 1.25.
Keskihajontaa, joka on tärkein absoluuttinen variaation mitta, käytetään normaalijakaumakäyrän ordinaattien arvojen määrittämisessä, näytteen havainnoinnin järjestämiseen ja näytteen ominaisuuksien tarkkuuden määrittämiseen liittyvissä laskelmissa sekä arvioida ominaisuuden vaihtelun rajoja homogeenisessa populaatiossa.
Dispersio, sen tyypit, keskihajonta.
Satunnaismuuttujan varianssi- tietyn satunnaismuuttujan hajoamisen mitta, eli sen poikkeama matemaattisesta odotuksesta. Tilastoissa käytetään usein nimitystä tai. Neliöjuuri varianssia kutsutaan keskihajonnaksi, keskihajonnaksi tai standardihajotukseksi.
Kokonaisvarianssi (σ2) mittaa piirteen vaihtelua koko populaatiossa kaikkien tämän vaihtelun aiheuttaneiden tekijöiden vaikutuksesta. Samalla ryhmittelymenetelmän ansiosta on mahdollista eristää ja mitata ryhmittelyominaisuudesta johtuvaa vaihtelua sekä huomioimattomien tekijöiden vaikutuksesta tapahtuvaa vaihtelua.
Ryhmien välinen varianssi (σ 2 m.gr) luonnehtii systemaattista vaihtelua, eli ryhmittelyn taustalla olevan ominaisuuden vaikutuksesta syntyviä eroja tutkitun ominaisuuden suuruudessa.
keskihajonta(synonyymit: keskihajonta, keskihajonta, keskihajonta; samanlaiset termit: keskihajonta, standardihajotus) - todennäköisyysteoriassa ja tilastoissa yleisin indikaattori satunnaismuuttujan arvojen hajoamisesta suhteessa sen matemaattiseen odotukseen. Rajoitetuissa arvonäytteiden matriisissa käytetään matemaattisen odotuksen sijasta näytejoukon aritmeettista keskiarvoa.
Keskihajonta mitataan itse satunnaismuuttujan yksiköissä ja sitä käytetään aritmeettisen keskiarvon keskivirheen laskennassa, luottamusvälien muodostamisessa, hypoteesien tilastollisessa testauksessa sekä satunnaismuuttujien välisen lineaarisen suhteen mittaamisessa. Se määritellään satunnaismuuttujan varianssin neliöjuureksi.
Vakiopoikkeama:

Standardipoikkeama(satunnaismuuttujan keskihajonnan arvio x suhteessa sen matemaattiseen odotukseen, joka perustuu sen varianssin puolueettomaan arvioon):

missä on dispersio; — i-th näyteelementti; - otoskoko; - otoksen aritmeettinen keskiarvo:

On huomattava, että molemmat arviot ovat puolueellisia. Yleisessä tapauksessa on mahdotonta muodostaa puolueetonta arviota. Kuitenkin puolueettomaan varianssiarvioon perustuva arvio on johdonmukainen.
Moodin ja mediaanin olemus, laajuus ja menetelmä.
Tilastojen potenssilain keskiarvojen lisäksi vaihtelevan piirteen suuruuden ja jakaumasarjojen sisäisen rakenteen suhteelliselle ominaisuudelle käytetään rakenteellisia keskiarvoja, joita edustavat pääasiassa tila ja mediaani.
Muoti- Tämä on sarjan yleisin variantti. Muotia käytetään esimerkiksi ostajien keskuudessa eniten kysyttyjen vaatteiden, kenkien koon määrittämisessä. Diskreetin sarjan tila on vaihtoehto, jolla on korkein taajuus. Kun lasket moodia intervallivaihtelusarjalle, sinun on ensin määritettävä modaaliväli (by maksimitaajuus), ja sitten - attribuutin modaaliarvon arvo kaavan mukaan:

- - muotiarvo
- - modaalivälin alaraja
- - intervalliarvo
- - modaalinen intervallitaajuus
- - modaalia edeltävän intervallin taajuus
- - modaalia seuraavan intervallin taajuus
Mediaani - tämä on järjestyssarjan taustalla olevan ominaisuuden arvo ja joka jakaa sarjan kahteen yhtä suureen osaan.
Jos haluat määrittää mediaanin diskreetissä sarjassa taajuuksien läsnä ollessa, laske ensin taajuuksien puolisumma ja määritä sitten, mikä muunnelman arvo osuu siihen. (Jos lajiteltu rivi sisältää parittoman määrän ominaisuuksia, mediaaniluku lasketaan kaavalla:
M e \u003d (n (ominaisuuksien määrä koosteessa) + 1) / 2,
jos piirteitä on parillinen, mediaani on yhtä suuri kuin rivin keskellä olevien kahden ominaisuuden keskiarvo).
Laskettaessa mediaanit intervallivaihtelusarjaa varten määritä ensin mediaaniväli, jonka sisällä mediaani sijaitsee, ja sitten mediaanin arvo kaavan mukaan:

- on haluttu mediaani
- on mediaanin sisältävän välin alaraja
- - intervalliarvo
- - sarjan taajuuksien summa tai jäsenten lukumäärä
Mediaania edeltävien intervallien kumuloituneiden taajuuksien summa
- on mediaanivälin taajuus
Esimerkki. Etsi tila ja mediaani.
Ratkaisu:
Tässä esimerkissä modaaliväli on ikäryhmässä 25-30 vuotta, koska tämä intervalli on suurin esiintymistiheys (1054).Lasketaan tilan arvo:
Tämä tarkoittaa, että opiskelijoiden modaalinen ikä on 27 vuotta.
Laske mediaani. Mediaaniväli on klo ikäryhmä 25-30 vuotta, koska tällä aikavälillä on variantti, joka jakaa populaation kahteen yhtä suureen osaan (Σf i /2 = 3462/2 = 1731). Seuraavaksi korvaamme tarvittavat numeeriset tiedot kaavaan ja saamme mediaanin arvon:

Tämä tarkoittaa, että puolet opiskelijoista on alle 27,4-vuotiaita ja toinen puolet yli 27,4-vuotiaita.
Moodin ja mediaanin lisäksi voidaan käyttää indikaattoreita, kuten kvartiileja, jotka jakavat paremmuusjärjestyksen 4 yhtä suureen osaan, desiilejä- 10 osaa ja prosenttipisteitä - 100 osaa kohti.
Valikoivan havainnoinnin käsite ja sen laajuus.
Valikoiva havainto pätee käytettäessä jatkuvaa tarkkailua fyysisesti mahdotonta suuren tietomäärän vuoksi tai taloudellisesti epäkäytännöllistä. Fyysinen mahdottomuus ilmenee esimerkiksi tutkittaessa matkustajavirtoja, markkinahintoja, perheen budjetit. Taloudellista epätarkoituksenmukaisuutta tapahtuu arvioitaessa niiden tuhoamiseen liittyvien tavaroiden laatua, esimerkiksi maistelua, tiilien lujuutta jne.
Havainnointiin valitut tilastoyksiköt muodostavat otoksen tai otoksen ja niiden koko matriisin - yleisen populaation (GS). Tässä tapauksessa näytteen yksiköiden lukumäärä tarkoittaa n, ja koko HS - N. Asenne n/N jota kutsutaan otoksen suhteelliseksi kooksi tai suhteeksi.
Näytteenottotulosten laatu riippuu näytteen edustavuudesta eli kuinka edustava se on HS:ssä. Otoksen edustavuuden varmistamiseksi on huomioitava yksikköjen satunnaisen valinnan periaate, joka olettaa, että HS-yksikön sisällyttämiseen otokseen ei voi vaikuttaa mikään muu tekijä kuin sattuma.
Olemassa 4 tapaa valita satunnainen valinta näyte:
- Itse asiassa satunnaisesti valinta tai "lottomenetelmä", kun tilastot määritetään järjestysnumerot, tuodaan tiettyjen esineiden päälle (esimerkiksi tynnyreihin), jotka sitten sekoitetaan tietyssä astiassa (esimerkiksi pussissa) ja valitaan satunnaisesti. Käytännössä tämä menetelmä suoritetaan käyttämällä satunnaislukugeneraattoria tai matemaattisia satunnaislukutaulukoita.
- Mekaaninen valinta, jonka mukaan jokainen ( N/n)-arvo väestöstä. Jos se sisältää esimerkiksi 100 000 arvoa ja haluat valita 1 000, jokainen 100 000 / 1000 = 100. arvo kuuluu otokseen. Lisäksi, jos niitä ei sijoiteta, ensimmäinen valitaan satunnaisesti ensimmäisestä sadasta, ja muiden numerot ovat sata enemmän. Jos esimerkiksi yksikkö numero 19 oli ensimmäinen, numeron 119 pitäisi olla seuraava, sitten numeron 219, sitten numeron 319 ja niin edelleen. Jos väestöyksiköt asetetaan paremmuusjärjestykseen, valitaan ensin #50, sitten #150, sitten #250 ja niin edelleen.
- Arvojen valinta heterogeenisestä tietojoukosta suoritetaan kerrostunut(kerrostettu) menetelmä, jossa yleinen populaatio on aiemmin jaettu homogeenisiin ryhmiin, joihin sovelletaan satunnaista tai mekaanista valintaa.
- Erityinen näytteenottomenetelmä on sarja valinta, jossa ei valita yksittäisiä suureita satunnaisesti tai mekaanisesti, vaan niiden sarjat (jonot jostakin numerosta johonkin peräkkäiseen), joiden sisällä suoritetaan jatkuvaa havainnointia.
Otoshavaintojen laatu riippuu myös näytteenottotyyppi: toistettu tai ei-toistuva.
klo uudelleenvalinta otokseen päätyneet tilastoarvot tai niiden sarjat palautetaan käytön jälkeen yleiseen populaatioon, jolloin on mahdollisuus päästä uuteen otokseen. Samaan aikaan kaikilla yleisen perusjoukon arvoilla on sama todennäköisyys tulla mukaan otokseen.
Ei-toistuva valinta tarkoittaa, että otokseen sisältyviä tilastoarvoja tai niiden sarjoja ei palauteta yleiseen perusjoukkoon käytön jälkeen, ja siksi todennäköisyys päästä seuraavaan otokseen kasvaa jälkimmäisen jäljellä olevilla arvoilla.
Ei-toistuva näytteenotto antaa tarkempia tuloksia, joten sitä käytetään useammin. Mutta on tilanteita, jolloin sitä ei voida soveltaa (matkustajavirtojen, kulutuskysynnän tutkimus jne.) ja sitten suoritetaan uudelleenvalinta.
Havaintootoksen rajavirhe, otoksen keskimääräinen virhe, niiden laskentajärjestys.
Tarkastellaanpa yksityiskohtaisesti yllä olevia otosjoukon muodostamismenetelmiä ja tässä tapauksessa ilmeneviä virheitä. edustavuus .
Itse asiassa satunnainen otos perustuu yksiköiden valintaan yleisestä perusjoukosta satunnaisesti ilman johdonmukaisuuden elementtejä. Teknisesti oikea satunnaisvalinta tehdään arpomalla (esimerkiksi arpajaiset) tai satunnaislukutaulukon avulla.Itse asiassa satunnaista valintaa "puhtaassa muodossaan" valikoivan havainnoinnin käytännössä käytetään harvoin, mutta se on ensimmäinen muiden valintatyyppien joukossa, se toteuttaa valikoivan havainnoinnin perusperiaatteet. Tarkastellaanpa joitain kysymyksiä otantamenetelmän teoriasta ja yksinkertaisen satunnaisotoksen virhekaavasta.
Näytteenottovirhe- tämä on yleisen perusjoukon parametrin arvon ja sen otoshavaintotuloksista lasketun arvon välinen ero. Keskimääräiselle kvantitatiiviselle ominaisuudelle näytteenottovirheen määrää
Indikaattoria kutsutaan marginaalinäytteenottovirheeksi.
Otoskeskiarvo on satunnaismuuttuja, joka voi kestää erilaisia merkityksiä riippuen siitä, mitkä yksiköt otokseen kuuluivat. Siksi näytteenottovirheet ovat myös satunnaismuuttujia ja voivat saada erilaisia arvoja. Siksi keskiarvo määritetään mahdollisia virheitä - tarkoittaa näytteenottovirhettä, joka riippuu:Näytteen koko: kuin lisää voimaa, mitä pienempi on keskimääräisen virheen arvo;
Tutkitun piirteen muutosaste: mitä pienempi piirteen variaatio ja siten varianssi, sitä pienempi on keskimääräinen otantavirhe.
klo satunnainen uudelleenvalinta keskimääräinen virhe lasketaan:
.
Käytännössä yleisvarianssia ei tarkkaan tunneta, mutta sisään todennäköisyysteoria todisti sen .
.
Koska riittävän suuren n:n arvo on lähellä yhtä, voimme olettaa, että . Sitten keskimääräinen näytteenottovirhe voidaan laskea:
.
Mutta jos kyseessä on pieni näyte (n<30) коэффициент необходимо учитывать, и среднюю ошибку малой выборки рассчитывать по формуле .
.klo satunnainen otanta annetut kaavat korjataan arvolla . Sitten keskimääräinen ei-otantavirhe on:
 Ja
Ja  .
.
Koska on aina pienempi kuin , silloin tekijä () on aina pienempi kuin 1. Tämä tarkoittaa, että keskimääräinen virhe ei-toistuvassa valinnassa on aina pienempi kuin toistuvassa valinnassa.
Mekaaninen näytteenotto käytetään, kun väestö on jollain tavalla järjestetty (esim. äänestäjälistat aakkosjärjestyksessä, puhelinnumerot, talonumerot, asunnot). Yksiköiden valinta suoritetaan tietyllä aikavälillä, joka on yhtä suuri kuin näytteen prosenttiosuuden käänteisluku. Joten 2 %:n otoksella valitaan joka 50 yksikköä = 1 / 0,02 ja 5 %:lla jokainen 1 / 0,05 = 20 yksikköä yleisestä populaatiosta.Origo valitaan eri tavoin: satunnaisesti, intervallin puolivälistä alkaen origon muutoksella. Tärkeintä on välttää systemaattisia virheitä. Esimerkiksi 5 % näytteellä, jos 13. valitaan ensimmäiseksi yksiköksi, sitten seuraavat 33, 53, 73 jne.
Tarkkuuden kannalta mekaaninen valinta on lähellä oikeaa satunnaisotosta. Siksi mekaanisen näytteenoton keskimääräisen virheen määrittämiseksi käytetään oikean satunnaisvalinnan kaavoja.
klo tyypillinen valinta tutkittu väestö on alustavasti jaettu homogeenisiin yksityyppisiin ryhmiin. Esimerkiksi yrityksiä kartoittaessa ne voivat olla toimialoja, alasektoreita, kun taas väestöä tutkitaan - alueita, sosiaalisia tai ikäryhmiä. Sitten jokaisesta ryhmästä tehdään itsenäinen valinta mekaanisella tai oikealla satunnaisella tavalla.
Tyypillinen näytteenotto antaa tarkempia tuloksia kuin muut menetelmät. Yleisen perusjoukon tyypistäminen varmistaa kunkin typologisen ryhmän edustuksen otoksessa, mikä mahdollistaa ryhmien välisen varianssin vaikutuksen poissulkemisen keskimääräiseen otosvirheeseen. Siksi, kun löydetään tyypillisen otoksen virhe varianssien yhteenlaskusäännön () mukaan, on otettava huomioon vain ryhmän varianssien keskiarvo. Sitten keskimääräinen näytteenottovirhe on:
uudelleen valinnassa
,
kertaluonteisella valinnalla ,
,
Missä on ryhmän sisäisten varianssien keskiarvo otoksessa.
on ryhmän sisäisten varianssien keskiarvo otoksessa.Sarja (tai sisäkkäinen) valinta käytetään, kun perusjoukko jaetaan sarjoihin tai ryhmiin ennen otantatutkimuksen alkamista. Nämä sarjat voivat olla valmiiden tuotteiden paketteja, opiskelijaryhmiä, tiimejä. Tutkittavat sarjat valitaan mekaanisesti tai satunnaisesti, ja sarjan sisällä suoritetaan täydellinen yksiköiden kartoitus. Siksi keskimääräinen otantavirhe riippuu vain ryhmien välisestä (sarjojen välisestä) varianssista, joka lasketaan kaavalla:

missä r on valittujen sarjojen lukumäärä;
- i:nnen sarjan keskiarvo.Keskimääräinen sarjanäytteenottovirhe lasketaan:
uudelleen valittuna:
,
kertaluonteisella valinnalla: ,
,
jossa R on sarjan kokonaismäärä.Yhdistetty valinta on yhdistelmä harkittuja valintamenetelmiä.
Minkä tahansa valintamenetelmän keskimääräinen otantavirhe riippuu pääasiassa otoksen absoluuttisesta koosta ja vähäisemmässä määrin otoksen prosenttiosuudesta. Oletetaan, että ensimmäisessä tapauksessa tehdään 225 havaintoa 4 500 yksikön populaatiosta ja toisessa tapauksessa 225 000 yksiköstä. Varianssit molemmissa tapauksissa ovat 25. Sitten ensimmäisessä tapauksessa 5 % valinnalla otantavirhe on:

Toisessa tapauksessa 0,1 % valinnalla se on yhtä suuri:
Täten, kun näyteprosentti pieneni 50 kertaa, otosvirhe kasvoi hieman, koska otoskoko ei muuttunut.
Oletetaan, että otoskoko kasvaa 625 havaintoon. Tässä tapauksessa näytteenottovirhe on:
Otoksen lisäys 2,8-kertaiseksi samalla yleisjoukon koolla pienentää otantavirheen kokoa yli 1,6-kertaiseksi.Otospopulaation muodostamisen menetelmät ja keinot.
Tilastoissa käytetään erilaisia otosjoukkojen muodostamismenetelmiä, mikä määräytyy tutkimuksen tavoitteiden mukaan ja riippuu tutkimuskohteen erityispiirteistä.
Otostutkimuksen suorittamisen pääehtona on estää systemaattisten virheiden syntyminen, jotka aiheutuvat perusjoukon jokaisen yksikön yhtäläisten mahdollisuuksien periaatteen rikkomisesta otokseen pääsyssä. Systemaattisten virheiden ehkäisy saavutetaan käyttämällä tieteellisesti perusteltuja menetelmiä näytepopulaation muodostamiseksi.
Voit valita yksiköt yleisestä populaatiosta seuraavilla tavoilla:
1) yksilöllinen valinta - yksittäiset yksiköt valitaan otoksesta;
2) ryhmävalinta - otokseen kuuluvat laadullisesti homogeeniset tutkittavat ryhmät tai yksiköiden sarjat;
3) yhdistetty valinta on yksilö- ja ryhmävalinnan yhdistelmä.
Valintamenetelmät määräytyvät otantapopulaation muodostamista koskevien sääntöjen mukaan.Näyte voi olla:
- oikea satunnainen koostuu siitä, että otos muodostuu yksittäisten yksiköiden satunnaisen (tahattoman) valinnan tuloksena yleisestä populaatiosta. Tässä tapauksessa otosjoukkoon valittujen yksiköiden lukumäärä määräytyy yleensä otoksen hyväksytyn osuuden perusteella. Otososuus on otospopulaation n yksiköiden lukumäärän suhde yleisen perusjoukon N yksiköiden lukumäärään, ts.
- mekaaninen koostuu siitä, että yksiköiden valinta otokseen tehdään yleisestä perusjoukosta, joka on jaettu yhtä suuriin aikaväleihin (ryhmiin). Tässä tapauksessa välin koko yleisessä populaatiossa on yhtä suuri kuin otoksen osuuden käänteisluku. Joten 2 % näytteellä valitaan joka 50. yksikkö (1:0.02), 5 % näytteellä joka 20. yksikkö (1:0.05) jne. Siten yleispopulaatio on jaettu valinnan hyväksytyn osuuden mukaisesti mekaanisesti yhtäläisiin ryhmiin. Jokaisesta näytteen ryhmästä valitaan vain yksi yksikkö.
- tyypillinen - jossa yleinen väestö jaetaan ensin homogeenisiin tyypillisiin ryhmiin. Sitten kustakin tyypillisestä ryhmästä valitaan yksittäiset yksiköt näytteeseen satunnais- tai mekaanisella näytteellä. Tyypillisen näytteen tärkeä piirre on, että se antaa tarkempia tuloksia verrattuna muihin menetelmiin näytteen yksiköiden valitsemiseksi;
- sarja- jossa yleinen väestö on jaettu samankokoisiin ryhmiin - sarja. Sarjat valitaan näytesarjasta. Sarjan sisällä tehdään jatkuvaa sarjaan joutuneiden yksiköiden havainnointia;
- yhdistetty- Näytteenotto voi olla kaksivaiheinen. Tässä tapauksessa yleinen väestö jaetaan ensin ryhmiin. Sitten valitaan ryhmät ja jälkimmäisen sisällä yksittäiset yksiköt.
Tilastoissa erotetaan seuraavat menetelmät yksiköiden valitsemiseksi otoksesta::
- yksi vaihe näyte - jokainen valittu yksikkö tutkitaan välittömästi tietyllä perusteella (itse asiassa satunnaiset ja sarjanäytteet);
- monivaiheinen näytteenotto - valinta tehdään yksittäisten ryhmien yleisestä populaatiosta ja yksittäiset yksiköt valitaan ryhmistä (tyypillinen näyte mekaanisella yksiköiden valintamenetelmällä otantapopulaatiossa).
Lisäksi siellä on:
- uudelleenvalinta- palautetun pallon kaavion mukaan. Tässä tapauksessa jokainen otokseen päässyt yksikkö tai sarja palautetaan yleiseen perusjoukkoon, ja siksi sillä on mahdollisuus tulla uudelleen otokseen;
- ei-toistuva valinta- palauttamattoman pallon kaavion mukaan. Sillä on tarkemmat tulokset samalle otoskoolle.
Vaaditun otoskoon määrittäminen (Student-taulukon avulla).
Yksi otantateorian tieteellisistä periaatteista on varmistaa, että yksiköitä valitaan riittävä määrä. Teoreettisesti tämän periaatteen noudattamisen tarve esitetään todennäköisyysteorian rajalauseiden todisteissa, joiden avulla voidaan määrittää, kuinka monta yksikköä tulisi valita yleisestä perusjoukosta, jotta se olisi riittävä ja varmistaisi otoksen edustavuuden.
Otoksen keskivirheen pieneneminen ja siten estimaatin tarkkuuden lisääntyminen liittyy aina otoskoon kasvuun, joten jo otoshavainnon järjestämisvaiheessa on päätettävä mikä otoskoon tulisi olla, jotta havainnointitulosten tarkkuus voidaan varmistaa. Tarvittavan otoskoon laskenta rakennetaan marginaalivirheiden (A) kaavoista johdetuilla kaavoilla, jotka vastaavat yhtä tai toista valintatyyppiä ja -tapaa. Joten satunnaiselle toistuvalle otoskoolle (n) meillä on:

Tämän kaavan ydin on, että kun tarvittava määrä valitaan satunnaisesti uudelleen, otoskoko on suoraan verrannollinen luottamuskertoimen neliöön (t2) ja variaatiopiirteen varianssi (A2) ja on kääntäen verrannollinen marginaalinäytteenottovirheen (A2) neliöön. Erityisesti kaksinkertaistamalla rajavirhe voidaan tarvittavaa otoskokoa pienentää kertoimella neljä. Kolmesta parametrista kaksi (t ja?) on tutkijan asettamia.
Samaan aikaan tutkija Otantakyselyä varten on ratkaistava kysymys: missä kvantitatiivisessa yhdistelmässä nämä parametrit on parempi sisällyttää optimaalisen muunnelman saamiseksi? Yhdessä tapauksessa hän voi olla tyytyväisempi saatujen tulosten luotettavuuteen (t) kuin tarkkuusmittaan (?), toisessa - päinvastoin. Otosrajavirheen arvoa koskevaa ongelmaa on vaikeampi ratkaista, koska tutkijalla ei ole tätä indikaattoria näytehavainnon suunnitteluvaiheessa, joten käytännössä on tapana asettaa otosmarginaalivirhe esim. pääsääntöisesti 10 %:n sisällä ominaisuuden odotetusta keskimääräisestä tasosta. Oletetun keskitason määrittämistä voidaan lähestyä eri tavoin: käyttämällä vastaavien aikaisempien tutkimusten tietoja tai käyttämällä otantakehyksen tietoja ja ottamalla pienen pilottinäytteen.
Otoshavaintoa suunniteltaessa vaikeinta määrittää on kaavan (5.2) kolmas parametri - otosjoukon varianssi. Tässä tapauksessa on tarpeen käyttää kaikkia tutkijan käytettävissä olevia tietoja, jotka on saatu aikaisemmista vastaavista ja pilottitutkimuksista.
Määrittelykysymys Vaadittava otoskoko monimutkaistuu, jos otantatutkimuksessa tutkitaan useita otantayksiköiden ominaisuuksia. Tässä tapauksessa kunkin ominaisuuden keskimääräiset tasot ja niiden vaihtelut ovat pääsääntöisesti erilaisia, ja siksi on mahdollista päättää, mikä hajonta mitkä ominaisuudet suosivat vain ottaen huomioon ominaisuuden tarkoitus ja tavoitteet. kysely.
Otoshavaintoa suunniteltaessa oletetaan ennalta määrätty arvo sallitun otantavirheen tietyn tutkimuksen tavoitteiden ja havainnon tulosten perusteella tehtyjen johtopäätösten todennäköisyyden mukaisesti.
Yleisesti ottaen näytteen keskiarvon marginaalivirheen kaavan avulla voit määrittää:
Yleisen perusjoukon indikaattoreiden mahdollisten poikkeamien suuruus otantajoukon indikaattoreista;
Vaadittu näytekoko, joka tarjoaa vaaditun tarkkuuden, jossa mahdollisen virheen rajat eivät ylitä tiettyä määritettyä arvoa;
Todennäköisyys, että näytteen virheellä on tietty raja.
Opiskelijoiden jakelu todennäköisyysteoriassa se on yhden parametrin perhe ehdottoman jatkuvia jakaumia.
Dynamiikkasarja (intervalli, momentti), dynamiikan sarjan sulkeminen.
Sarja dynamiikkaa- nämä ovat tilastollisten indikaattoreiden arvoja, jotka esitetään tietyssä kronologisessa järjestyksessä.
Jokainen aikasarja sisältää kaksi komponenttia:
1) ajanjaksojen indikaattorit (vuodet, neljännekset, kuukaudet, päivät tai päivämäärät);
2) tutkittavaa kohdetta aikajaksoille tai vastaaville päivämäärille kuvaavat indikaattorit, joita kutsutaan sarjan tasoiksi.
Sarjan tasot ilmaistaan sekä absoluuttiset että keskimääräiset tai suhteelliset arvot. Indikaattorien luonteesta riippuen rakennetaan dynaamisia absoluuttisten, suhteellisten ja keskiarvojen sarjoja. Suhteellisten ja keskiarvojen dynaamiset sarjat rakennetaan absoluuttisten arvojen derivaattasarjojen perusteella. Dynamiikassa on intervalli- ja momenttisarjoja.
Dynaaminen intervallisarja sisältää indikaattorien arvot tietyiltä ajanjaksoilta. Intervallisarjassa tasot voidaan laskea yhteen, jolloin saadaan ilmiön volyymi pidemmältä ajalta tai ns. kumuloituneet summat.
Dynaaminen hetki sarja heijastaa indikaattoreiden arvoja tietyllä hetkellä (ajankohdan päivämäärä). Hetkisarjoissa tutkija voi olla kiinnostunut vain ilmiöiden erosta, joka heijastaa sarjan tason muutosta tiettyjen päivämäärien välillä, koska tasojen summalla ei tässä ole todellista sisältöä. Kumulatiivisia kokonaismääriä ei lasketa tässä.
Dynaamisten sarjojen oikean rakentamisen tärkein edellytys on eri jaksoihin liittyvien sarjatasojen vertailukelpoisuus. Tasot tulee esittää homogeenisina määrinä, ilmiön eri osien kattavuuden tulee olla sama.
Jotta Todellisen dynamiikan vääristymisen välttämiseksi tilastotutkimuksessa (aikasarjan sulkeminen) tehdään alustavia laskelmia, jotka edeltävät aikasarjan tilastollista analyysiä. Aikasarjojen sulkemisella tarkoitetaan kahden tai useamman sarjan yhdistämistä yhdeksi sarjaksi, jonka tasot on laskettu eri metodologialla tai jotka eivät vastaa aluerajoja jne. Dynamiikkasarjan sulkeminen voi tarkoittaa myös dynamiikkasarjan absoluuttisten tasojen pienentämistä yhteiselle perustalle, mikä eliminoi dynamiikkasarjan tasojen yhteensopimattomuuden.
Aikasarjojen, kertoimien, kasvun ja kasvuvauhtien vertailukelpoisuuden käsite.
Sarja dynamiikkaa- Nämä ovat tilastollisia indikaattoreita, jotka kuvaavat luonnon- ja yhteiskunnallisten ilmiöiden kehitystä ajassa. Venäjän valtion tilastokomitean julkaisemat tilastokokoelmat sisältävät suuren määrän aikasarjoja taulukkomuodossa. Dynamiikkasarja mahdollistaa tutkittujen ilmiöiden kehitysmallien paljastamisen.
Aikasarjat sisältävät kahdenlaisia indikaattoreita. Aika-indikaattorit(vuodet, neljännekset, kuukaudet jne.) tai ajankohtia (vuoden alussa, kunkin kuukauden alussa jne.). Rivitason ilmaisimet. Aikasarjojen tasojen indikaattorit voidaan ilmaista absoluuttisina arvoina (tuotteen tuotanto tonneina tai ruplina), suhteellisina arvoina (osuus kaupunkiväestöstä %) ja keskiarvoina (teollisuuden työntekijöiden keskipalkat). vuosien mukaan jne.). Taulukkomuodossa aikasarja sisältää kaksi saraketta tai kaksi riviä.
Aikasarjojen oikea rakentaminen edellyttää useiden vaatimusten täyttymistä:
- kaikkien dynamiikkasarjan indikaattoreiden on oltava tieteellisesti perusteltuja ja luotettavia;
- dynamiikkasarjan indikaattoreiden tulee olla ajallisesti vertailukelpoisia, ts. on laskettava samoille ajanjaksoille tai samoille päivämäärille;
- useiden dynamiikojen indikaattoreiden olisi oltava vertailukelpoisia koko alueella;
- dynamiikkasarjan indikaattoreiden tulee olla sisällöltään vertailukelpoisia, ts. lasketaan yhdellä menetelmällä samalla tavalla;
- dynamiikkasarjan indikaattoreiden olisi oltava vertailukelpoisia eri tiloilla. Kaikki dynamiikkasarjan indikaattorit on annettava samoissa mittayksiköissä.
Tilastolliset indikaattorit voi karakterisoida joko tutkittavan prosessin tuloksia tietyn ajanjakson aikana tai tutkittavan ilmiön tilaa tietyllä hetkellä, ts. indikaattorit voivat olla intervalli (jaksollinen) ja välitön. Näin ollen dynamiikkasarja voi aluksi olla joko intervalli tai hetki. Dynaamiikan momenttisarjat voivat puolestaan olla yhtäläisin ja epätasaisin aikavälein.
Alkuperäinen dynamiikkasarja voidaan muuntaa sarjaksi keskiarvoja ja suhteellisia arvoja (ketju ja perusta). Tällaisia aikasarjoja kutsutaan johdetuiksi aikasarjoiksi.
Dynamiikkasarjan keskimääräisen tason laskentamenetelmä on erilainen dynamiikkasarjan tyypistä johtuen. Harkitse esimerkkien avulla aikasarjojen tyyppejä ja kaavoja keskitason laskemiseen.
Absoluuttiset voitot (Δy) osoittavat kuinka monta yksikköä sarjan myöhempi taso on muuttunut verrattuna edelliseen (sarake 3. - ketjun absoluuttiset lisäykset) tai verrattuna alkutasoon (sarake 4. - perusabsoluuttiset lisäykset). Laskentakaavat voidaan kirjoittaa seuraavasti:

Sarjan absoluuttisten arvojen pienentyessä tapahtuu vastaavasti "lasku", "lasku".
Absoluuttisen kasvun indikaattorit osoittavat, että esimerkiksi vuonna 1998 tuotteen "A" tuotanto kasvoi 4 000 tonnia vuoteen 1997 verrattuna ja 34 000 tonnia vuoteen 1994 verrattuna; muiden vuosien osalta katso taulukko. 11,5 gr. 3 ja 4.
Kasvutekijä näyttää kuinka monta kertaa sarjan taso on muuttunut verrattuna edelliseen (sarake 5 - ketjun kasvu- tai laskutekijät) tai verrattuna alkutasoon (sarake 6 - peruskasvu- tai laskutekijät). Laskentakaavat voidaan kirjoittaa seuraavasti:

Kasvunopeudet näyttää kuinka monta prosenttia sarjan seuraava taso on verrattuna edelliseen (sarake 7 - ketjun kasvuluvut) tai verrattuna alkuperäiseen tasoon (sarake 8 - peruskasvuluvut). Laskentakaavat voidaan kirjoittaa seuraavasti:

Joten esimerkiksi vuonna 1997 tuotteen "A" tuotantomäärä vuoteen 1996 verrattuna oli 105,5 % (
Kasvuvauhti osoittavat kuinka monta prosenttia raportointikauden taso nousi verrattuna edelliseen (sarake 9 - ketjun kasvuluvut) tai verrattuna alkutasoon (sarake 10 - peruskasvuluvut). Laskentakaavat voidaan kirjoittaa seuraavasti:
T pr \u003d T p - 100 % tai T pr \u003d absoluuttinen nousu / edellisen jakson taso * 100 %
Joten esimerkiksi vuonna 1996, verrattuna vuoteen 1995, tuotetta "A" tuotettiin 3,8 % (103,8 % - 100 %) tai (8:210) x 100 % enemmän ja vuoteen 1994 verrattuna - 9 % ( 109 % - 100 %).
Jos sarjan absoluuttiset tasot laskevat, nopeus on alle 100% ja vastaavasti laskunopeus (kasvunopeus miinusmerkillä).
Absoluuttinen arvo 1 % nousu(sarake 11) näyttää, kuinka monta yksikköä on tuotettava tietyllä ajanjaksolla, jotta edellisen jakson taso nousisi 1 %. Esimerkissämme vuonna 1995 oli tarpeen tuottaa 2,0 tuhatta tonnia ja vuonna 1998 - 2,3 tuhatta tonnia, ts. paljon suurempi.
On kaksi tapaa määrittää 1 %:n kasvun itseisarvon suuruus:
Jaa edellisen jakson taso 100:lla;
Jaa absoluuttiset ketjun kasvunopeudet vastaavilla ketjun kasvunopeuksilla.
1 %:n lisäyksen absoluuttinen arvo =

Dynamiikassa, varsinkin pitkällä aikavälillä, on tärkeää analysoida yhdessä kasvuvauhti kunkin prosentuaalisen lisäyksen tai laskun sisällöllä.
Huomaa, että tarkasteltu menetelmä aikasarjojen analysointiin soveltuu sekä aikasarjoille, joiden tasot ilmaistaan absoluuttisina arvoina (t, tuhat ruplaa, työntekijöiden määrä jne.), että aikasarjoille, jotka ilmaistaan suhteellisina indikaattoreina (romun %, hiilen tuhkapitoisuus % jne.) tai keskiarvoina (keskimääräinen sato s/ha, keskipalkka jne.).
Kullekin vuodelle edelliseen tai alkutasoon verrattuna laskettujen tarkasteltujen analyyttisten indikaattoreiden ohella aikasarjoja analysoitaessa on tarpeen laskea ajanjakson keskimääräiset analyyttiset indikaattorit: sarjan keskitaso, keskimääräinen vuotuinen absoluuttinen nousu. (lasku) ja keskimääräinen vuotuinen kasvuvauhti ja kasvuvauhti.
Menetelmiä dynamiikkasarjan keskimääräisen tason laskemiseksi käsiteltiin edellä. Tarkastelemassamme dynamiikan intervallisarjassa sarjan keskimääräinen taso lasketaan yksinkertaisen aritmeettisen keskiarvon kaavalla:
Tuotteen keskimääräinen vuosituotanto vuosina 1994-1998. oli 218,4 tuhatta tonnia.
Keskimääräinen vuotuinen absoluuttinen lisäys lasketaan myös yksinkertaisen aritmeettisen keskiarvon kaavalla:
Vuotuiset absoluuttiset lisäykset vaihtelivat vuosien aikana 4-12 tuhannesta tonnista (ks. gr. 3) ja keskimääräinen vuotuinen tuotannon lisäys kaudelta 1995-1998. oli 8,5 tuhatta tonnia.
Keskimääräisen kasvunopeuden ja keskimääräisen kasvunopeuden laskentamenetelmät vaativat tarkempaa tarkastelua. Tarkastellaan niitä taulukossa annettujen sarjatason vuosiindikaattoreiden esimerkissä.
Dynamiikka-alueen keskitaso.
Dynamiikkasarja (tai aikasarja)- nämä ovat tietyn tilastollisen indikaattorin numeerisia arvoja peräkkäisinä hetkinä tai ajanjaksoina (eli järjestettynä kronologiseen järjestykseen).
Tietyn tilastollisen indikaattorin numeerisia arvoja, jotka muodostavat sarjan dynamiikkaa, kutsutaan numeron tasot ja se on yleensä merkitty kirjaimella y. Sarjan ensimmäinen jäsen v 1 kutsutaan alkutai perusviiva, ja viimeinen y n - lopullinen. Hetket tai ajanjaksot, joihin tasot viittaavat, on merkitty t.
Dynaamiset sarjat esitetään pääsääntöisesti taulukon tai kaavion muodossa ja aika-asteikko rakennetaan x-akselia pitkin t, ja ordinaatta pitkin - sarjan tasojen asteikko y.
Dynamiikkasarjan keskimääräiset indikaattorit
Jokaista dynamiikan sarjaa voidaan pitää tiettynä joukkona n ajallisesti vaihtelevia indikaattoreita, jotka voidaan tiivistää keskiarvoiksi. Tällaiset yleiset (keskimääräiset) indikaattorit ovat erityisen tarpeellisia verrattaessa yhden tai toisen indikaattorin muutoksia eri ajanjaksoina, eri maissa jne.
Dynaamisten sarjan yleistetty ominaisuus voi olla ensinnäkin keskimääräinen rivitaso. Keskitason laskentatapa riippuu siitä, onko kyseessä momenttisarja vai intervallisarja.
Kun intervalli sarja, sen keskimääräinen taso määräytyy sarjan tasojen yksinkertaisen aritmeettisen keskiarvon kaavalla, ts.
=
Jos saatavilla hetki rivi, joka sisältää n tasot ( y1, y2, …, yn) tasaisin väliajoin päivämäärien (ajanpisteiden) välillä, niin tällainen sarja voidaan helposti muuntaa sarjaksi keskiarvoja. Samanaikaisesti kunkin jakson alun tunnusluku (taso) on samanaikaisesti edellisen jakson lopun tunnusluku. Sitten indikaattorin keskiarvo kullekin ajanjaksolle (päivien välinen aika) voidaan laskea arvojen puolena summana klo kauden alussa ja lopussa, ts. Miten . Tällaisten keskiarvojen määrä on . Kuten aiemmin mainittiin, keskiarvosarjojen keskitaso lasketaan aritmeettisesta keskiarvosta.Siksi voimme kirjoittaa:
 .
.
Kun osoittaja on muunnettu, saamme: ,
,Missä Y1 Ja Yn- sarjan ensimmäinen ja viimeinen taso; Yi- keskitasot.
Tämä keskiarvo tunnetaan tilastoissa nimellä keskimääräinen kronologinen hetken sarja. Hän sai tämän nimen sanasta "cronos" (aika, lat.), koska se on laskettu ajan myötä muuttuvista indikaattoreista.
Epätasa-arvon tapauksessa päivämäärien väliset aikavälit, hetkisarjojen kronologinen keskiarvo voidaan laskea kunkin hetkiparin tasojen keskiarvojen aritmeettisena keskiarvona painotettuna päivämäärien välisillä etäisyyksillä (aikaväleillä), ts.
 .
.
Tässä tapauksessa oletetaan, että päivämäärien välissä tasot saivat eri arvoja, ja olemme kahdesta tunnetusta ( yi Ja yi+1) määritämme keskiarvot, joista sitten laskemme kokonaiskeskiarvon koko analysoidulta ajanjaksolta.
Jos oletetaan, että jokainen arvo yi pysyy ennallaan seuraavaan asti (i+ 1)- hetki, ts. tasojen muutoksen tarkka päivämäärä tiedetään, niin laskelma voidaan suorittaa painotetun aritmeettisen keskiarvon kaavalla:
,missä on aika, jonka taso pysyi muuttumattomana.
Dynamiikkasarjan keskitason lisäksi lasketaan myös muita keskimääräisiä indikaattoreita - sarjan tasojen keskimääräinen muutos (perus- ja ketjumenetelmät), keskimääräinen muutosnopeus.
Perustaso tarkoittaa absoluuttista muutosta on viimeisen absoluuttisen perusmuutoksen osamäärä jaettuna muutosten määrällä. Tuo on
Ketju tarkoittaa absoluuttista muutosta sarjan tasot on osamäärä, jossa kaikkien ketjun absoluuttisten muutosten summa jaetaan muutosten määrällä, ts.
Keskimääräisten absoluuttisten muutosten merkillä arvioidaan myös ilmiön muutoksen luonne keskimäärin: kasvu, lasku vai vakaus.
Perus- ja ketjun absoluuttisten muutosten hallintasäännöstä seuraa, että perus- ja ketjukeskiarvomuutosten on oltava yhtä suuret.
Keskimääräisen absoluuttisen muutoksen ohella lasketaan myös keskimääräinen suhteellinen perus- ja ketjumenetelmällä.
Perustason keskimääräinen suhteellinen muutos määräytyy kaavalla:
Ketju tarkoittaa suhteellista muutosta määräytyy kaavalla:
Luonnollisesti perus- ja ketjukeskimääräisten suhteellisten muutosten tulee olla samat, ja vertaamalla niitä kriteerin arvoon 1, tehdään johtopäätös ilmiön muutoksen luonteesta keskimäärin: kasvu, lasku vai vakaus.
Vähentämällä 1 perus- tai ketjukeskimääräisestä suhteellisesta muutoksesta saadaan vastaava keskimääräinen muutosnopeus, jonka merkillä voidaan myös arvioida tutkittavan ilmiön muutoksen luonnetta, jota tämä dynamiikkasarja heijastaa.Kausivaihtelut ja kausivaihteluindeksit.
Kausivaihtelut ovat vakaita vuotuisia vaihteluita.
Maksimivaikutuksen saavuttamisen perusperiaate on tulojen maksimointi ja kustannusten minimointi. Kausivaihteluita tutkimalla ratkaistaan vuoden jokaisen tason maksimiyhtälön ongelma.
Kausivaihteluita tutkittaessa ratkaistaan kaksi toisiinsa liittyvää tehtävää:
1. Ilmiön kehityksen erityispiirteiden tunnistaminen vuoden sisäisessä dynamiikassa;
2. Kausivaihteluiden mittaaminen kausiaaltomallin rakentamisen avulla;
Sesonkikalkkunat lasketaan yleensä kausiluonteisuuden mittaamiseksi. Yleisesti ottaen ne määräytyvät dynamiikkasarjan alkuperäisten yhtälöiden ja vertailun perustana olevien teoreettisten yhtälöiden suhteen perusteella.
Koska satunnaiset poikkeamat asettuvat kausivaihteluille, kausivaihteluiden eliminoimiseksi lasketaan keskiarvo.
Tässä tapauksessa jokaiselle vuosisyklin jaksolle määritetään yleiset indikaattorit keskimääräisten kausi-indeksien muodossa:
Kausivaihteluiden keskimääräiset indeksit ovat vapaita pääkehitystrendin satunnaisten poikkeamien vaikutuksesta.
Trendin luonteesta riippuen keskimääräisen kausivaihteluindeksin kaava voi olla seuraavanlainen:
1.Vuosittaisten dynamiikojen sarjalle, jolla on selvä pääkehitystrendi:
2. Vuosittaisen dynamiikan sarjalle, jossa ei ole nousevaa tai laskevaa trendiä tai se on merkityksetön:
Missä on yleinen keskiarvo?
Päätrendin analysointimenetelmät.
Ilmiöiden kehittymiseen ajan mittaan vaikuttavat erilaiset tekijät, jotka ovat luonteeltaan ja voimakkuudeltaan erilaisia. Jotkut niistä ovat luonteeltaan satunnaisia, toisilla on lähes jatkuva vaikutus ja ne muodostavat tietyn kehityssuunnan dynamiikan sarjassa.
Tilastojen tärkeä tehtävä on tunnistaa trendi dynamiikan sarjassa, joka on vapautettu erilaisten satunnaisten tekijöiden vaikutuksesta. Tätä tarkoitusta varten aikasarjoja käsitellään intervallin suurennusmenetelmillä, liukuvalla keskiarvolla ja analyyttisellä kohdistuksella jne.
Intervallikarkeusmenetelmä perustuu aikajaksojen laajentamiseen, jotka sisältävät sarjan dynamiikkatasoja, ts. on pieniin ajanjaksoihin liittyvien tietojen korvaaminen suurempien ajanjaksojen tiedoilla. Se on erityisen tehokas, kun sarjan alkutasot ovat lyhytaikaisia. Esimerkiksi päivittäisiin tapahtumiin liittyvät indikaattorisarjat korvataan viikoittain, kuukausittain jne. liittyvillä sarjoilla. Tämä näkyy selvemmin "Ilmiön kehitysakseli". Laajennettujen intervallien perusteella laskettu keskiarvo mahdollistaa pääkehitystrendin suunnan ja luonteen (kasvun kiihtymisen tai hidastuvuuden) tunnistamisen.
liukuva keskiarvo menetelmä samanlainen kuin edellinen, mutta tässä tapauksessa todelliset tasot korvataan keskimääräisillä tasoilla, jotka on laskettu peräkkäin liikkuville (liukuville) suurennetuille intervalleille, jotka kattavat m rivin tasot.
Esimerkiksi jos hyväksytään m = 3, sitten ensin lasketaan sarjan kolmen ensimmäisen tason keskiarvo, sitten - samasta määrästä tasoja, mutta alkaen peräkkäin toisesta, sitten - alkaen kolmannesta jne. Siten keskiarvo ikään kuin "liukuu" pitkin dynamiikkasarjaa liikkuen yhden jakson ajan. Laskettu m liukuvien keskiarvojen jäsenet viittaavat kunkin intervallin keskikohtaan (keskikohtaan).
Tämä menetelmä eliminoi vain satunnaiset vaihtelut. Jos sarjassa on kausittaista aaltoa, se säilyy liukuvalla keskiarvomenetelmällä tasoituksen jälkeen.
Analyyttinen kohdistus. Satunnaisten vaihteluiden eliminoimiseksi ja trendin tunnistamiseksi sarjan tasot kohdistetaan analyyttisten kaavojen (tai analyyttisen kohdistuksen) mukaisesti. Sen ydin on korvata empiiriset (todelliset) tasot teoreettisilla tasoilla, jotka lasketaan tietyn yhtälön mukaan trendin matemaattisena mallina, jossa teoreettisia tasoja tarkastellaan ajan funktiona: . Tässä tapauksessa kutakin todellista tasoa pidetään kahden komponentin summana: , jossa on systemaattinen komponentti ja ilmaistaan tietyllä yhtälöllä, ja se on satunnaismuuttuja, joka aiheuttaa vaihteluja trendin ympärillä.
Analyyttisen linjauksen tehtävä on seuraava:
1. Määritellään todellisten tietojen perusteella, minkä tyyppinen hypoteettinen funktio voi parhaiten kuvastaa tutkittavan indikaattorin kehityssuuntaa.
2. Määritetyn funktion (yhtälön) parametrien löytäminen empiirisesta tiedosta
3. Laskenta teoreettisten (tasoitettujen) tasojen löydetyn yhtälön mukaan.
Tietyn toiminnon valinta tapahtuu pääsääntöisesti empiirisen tiedon graafisen esityksen perusteella.
Mallit ovat regressioyhtälöitä, joiden parametrit lasketaan pienimmän neliösumman menetelmällä
Alla on yleisimmin käytetyt aikasarjojen tasoitusregressioyhtälöt, jotka osoittavat, mitä kehityssuuntia ne sopivat parhaiten heijastamaan.
Yllä olevien yhtälöiden parametrien löytämiseksi on olemassa erityisiä algoritmeja ja tietokoneohjelmia. Erityisesti suoran yhtälön parametrien löytämiseksi voidaan käyttää seuraavaa algoritmia:

Jos jaksot tai ajanhetket on numeroitu siten, että saadaan St = 0, niin yllä olevat algoritmit yksinkertaistuvat merkittävästi ja muuttuvat

Kaavion tasaiset tasot sijaitsevat yhdellä suoralla, joka kulkee lähimpänä tämän dynaamisen sarjan todellisia tasoja. Poikkeamien neliösumma heijastaa satunnaisten tekijöiden vaikutusta.
Sen avulla laskemme yhtälön keskimääräisen (standardi) virheen:

Tässä n on havaintojen lukumäärä ja m on yhtälön parametrien lukumäärä (meillä on niitä kaksi - b 1 ja b 0).
Päätrendi (trendi) osoittaa, kuinka systemaattiset tekijät vaikuttavat dynamiikkasarjan tasoihin, ja tasojen vaihtelu trendin () ympärillä toimii jäännöstekijöiden vaikutuksen mittana.
Sitä käytetään myös käytetyn aikasarjamallin laadun arvioimiseen Fisherin F-testi. Se on kahden varianssin suhde, nimittäin regression aiheuttaman varianssin suhde, ts. tutkittu tekijä, satunnaisten syiden aiheuttamaan hajaantumiseen, ts. jäännösvarianssi:

Laajennetussa muodossa tämän kriteerin kaava voidaan esittää seuraavasti:

missä n on havaintojen lukumäärä, ts. rivitasojen määrä,
m on yhtälön parametrien lukumäärä, y on sarjan todellinen taso,
Rivin tasattu taso, - rivin keskimääräinen taso.
Muita menestyneempi malli ei välttämättä aina ole riittävän tyydyttävä. Se voidaan tunnistaa sellaiseksi vain, jos sen kriteeri F ylittää tietyn kriittisen rajan. Tämä raja asetetaan F-jakaumataulukoilla.
Indeksien olemus ja luokittelu.
Indeksi tilastoissa ymmärretään suhteelliseksi indikaattoriksi, joka kuvaa ilmiön suuruuden muutosta ajassa, tilassa tai mihin tahansa standardiin verrattuna.
Indeksirelaation pääelementti on indeksoitu arvo. Indeksoidulla arvolla tarkoitetaan tilastollisen perusjoukon merkin arvoa, jonka muutos on tutkimuksen kohteena.
Indekseillä on kolme päätarkoitusta:
1) monimutkaisen ilmiön muutosten arviointi;
2) yksittäisten tekijöiden vaikutuksen määrittäminen monimutkaisen ilmiön muutokseen;
3) jonkin ilmiön suuruuden vertailu menneen ajanjakson suuruuteen, toisen alueen suuruuteen sekä standardeihin, suunnitelmiin, ennusteisiin.
Indeksit luokitellaan kolmen kriteerin mukaan:
2) väestön osien peittoasteen mukaan;
3) yleisindeksien laskentamenetelmillä.
Sisällön mukaan Indeksoiduista arvoista indeksit on jaettu määrällisten (volyymien) indikaattoreiden indekseihin ja laadullisten indikaattoreiden indekseihin. Määrällisten indikaattoreiden indeksit - teollisuustuotannon fyysisen volyymin indeksit, myynnin fyysisen määrän, lukumäärän jne. Laadullisten indikaattoreiden indeksit - hintojen, kustannusten, työn tuottavuuden, keskipalkkojen jne.
Väestön yksiköiden peittoasteen mukaan indeksit jaetaan kahteen luokkaan: yksittäisiin ja yleisiin. Niiden karakterisoimiseksi otamme käyttöön seuraavat käytännöt, jotka on otettu käyttöön indeksimenetelmän soveltamisessa:
q- minkä tahansa luontoismuotoisen tuotteen määrä (tilavuus). ; R- tuotannon yksikköhinta; z- tuotantoyksikkökustannukset; t- tuotantoyksikön tuottamiseen käytetty aika (työvoimaintensiteetti) ; w- tuotantomäärä arvona aikayksikköä kohti; v- tuotos fyysisinä ilmaisina aikayksikköä kohti; T- käytetty aika tai työntekijöiden kokonaismäärä.
Jotta voidaan erottaa, mihin ajanjaksoon tai objektiin indeksoidut arvot kuuluvat, on tapana laittaa alaindeksit vastaavan symbolin jälkeen oikeaan alakulmaan. Joten esimerkiksi dynamiikan indekseissä käytetään pääsääntöisesti verratuille (kulutuksille, raportointi) jaksoille alaindeksiä 1 ja jaksoille, joihin vertailu tehdään,
Yksittäiset indeksit käytetään luonnehtimaan muutosta monimutkaisen ilmiön yksittäisissä elementeissä (esimerkiksi yhden tyyppisen tuotteen tuotannon volyymin muutos). Ne edustavat dynamiikan suhteellisia arvoja, velvoitteiden täyttämistä, indeksoitujen arvojen vertailua.
Fyysisen tuotannon määrän yksilöllinen indeksi määritetään
Analyyttisesti tarkasteltuna annetut yksittäiset dynamiikkaindeksit ovat samankaltaisia kasvun kertoimien (nopeuksien) kanssa ja luonnehtivat indeksoidun arvon muutosta nykyisellä jaksolla perusarvoon verrattuna, eli osoittavat kuinka monta kertaa se on kasvanut (laskettu). ) tai kuinka monta prosenttia se on kasvua (laskua). Indeksiarvot ilmaistaan kertoimina tai prosentteina.
Yleinen (yhdistetty) indeksi heijastaa muutosta monimutkaisen ilmiön kaikissa elementeissä.
Aggregaattiindeksi on indeksin perusmuoto. Sitä kutsutaan aggregaatiksi, koska sen osoittaja ja nimittäjä ovat joukko "aggregaatteja"
Keskimääräiset indeksit, niiden määritelmä.
Aggregaattiindeksien lisäksi tilastoissa käytetään niiden toista muotoa - painotettuja keskiarvoindeksejä. Niiden laskentaan turvaudutaan, kun käytettävissä olevat tiedot eivät mahdollista yleisen aggregaattiindeksin laskemista. Joten jos hinnoista ei ole tietoa, mutta on tietoa tuotteiden kuluvan kauden kustannuksista ja kunkin tuotteen yksittäiset hintaindeksit ovat tiedossa, niin yleistä hintaindeksiä ei voida määrittää aggregaattina, mutta se on mahdollista laskea se yksittäisten keskiarvona. Vastaavasti, jos yksittäisten tuotettujen tuotteiden määriä ei tiedetä, mutta yksittäiset indeksit ja perusjakson tuotantokustannukset ovat tiedossa, voidaan tuotannon fyysisen volyymin kokonaisindeksi määrittää painotettuna keskiarvona.
Keskimääräinen indeksi - Tämä indeksi, joka lasketaan yksittäisten indeksien keskiarvona. Aggregaattiindeksi on yleisindeksin perusmuoto, joten keskimääräisen indeksin on oltava identtinen kokonaisindeksin kanssa. Keskimääräisiä indeksejä laskettaessa käytetään kahta keskiarvojen muotoa: aritmeettista ja harmonista.
Aritmeettinen keskiarvoindeksi on identtinen kokonaisindeksin kanssa, jos yksittäisten indeksien painot ovat kokonaisindeksin nimittäjän termejä. Vain tässä tapauksessa aritmeettisen keskiarvon kaavalla laskettu indeksin arvo on yhtä suuri kuin kokonaisindeksi.

