Sveže preveden temeljni učbenik S. Khaikina (prevedena je bila druga ameriška izdaja iz leta 1999) v celoti trdi, da je dogodek leta 2006 v ruski literaturi o nevroinformatiki. Vendar je treba opozoriti, da čeprav je bil prevod narejen brez očitnih napak, opombe-komentarji prevajalcev ne bi škodili razjasnitvi terminologije (ker lahko isto stvar v nevroinformatiki, statistiki in identifikaciji sistemov imenujemo z različnimi besedami, je potrebno bodisi skrčiti izraze na eno področje ali podati seznam sinonimov - vsi bralci ne bodo imeli širokega pogleda). Komentarji bi lahko odražali tudi napredek na področju umetnih nevronskih mrež, do katerega je prišlo od objave angleškega izvirnika. Upam, da bo po knjigi povpraševanje in da bodo spremembe ob ponatisu. Poleg tega je v matematičnih formulah veliko tipkarskih napak. Ta stran je namenjena predvsem popravkom tipkarskih napak. Vendar je treba opozoriti, da ne jamčim za popolnost tukaj navedenega seznama netočnosti - knjigo sem prebral "diagonalno", v napadih različne stopnje pozornosti, da bi lahko kaj spregledal (ali se sam zmotil).
Poglavje 1
- str.32 drugi odstavek. Samo tukaj lahko besedo "zmogljivost" razumemo kot hitrost dela, moč kalkulatorja. Nadalje v knjigi bo "zmogljivost" pomenila natančnost, kakovost nevronske mreže (na primer na str. 73 v drugem odstavku od spodaj).
- S.35 str.7. "VLSI Implementability" je bolje prevesti ne kot "razširljivost", temveč kot "učinkovita implementabilnost na VLSI - zelo velikih integriranih vezjih".
- str.39 str.7. Beseda "spike" - "izmet, impulz" se v ruski nevroznanosti pogosto in običajno preprosto prečrkuje kot "spike".
- Str.49 naslov odstavka. Morda bi bil boljši izraz "usmerjeni graf" namesto "usmerjeni graf".
- C.76 tretji odstavek. Namesto povezave bi verjetno morala biti povezava do Ashbyjeve knjige.
- Str.99 sklep 1. Dodati je treba tudi primer hkratnega izpolnjevanja istih pogojev in z znakom "
- C.105 odstavek 2. Vstavite besedo "viden" pred (viden).
2. poglavje
- P.94 opomba 2. Sklicevanje na je najverjetneje napačno, ker To ni knjiga in tudi naslov ne ustreza.
- Str.122 zadnji odstavek. Nasmejal se je izrazu "deformacija strukture nevronov": dokler zunanji dogodek pretresa možganov ne ustreza osebi, se tega dogodka ne bo spomnil. Najverjetneje so trdili, da se spomin realizira samo z odklopom sinaptičnih vhodov (končev) iz lovk dendritov ali preklapljanjem z ene lovke na drugo (izrazi od slike 1.2 do str. 40, saj je ta slika zelo primerna za ponazoritev). ). Tisti. naši možgani so živi in se premikajo.
- C.129 formula (2.39). Namesto X moral bi biti X.
- C.129 formule (2.40), (2.41), (2.44). Nadnapis mora biti q namesto m.
- C.137 prvi odstavek in formula (2.61). E mora biti v poševnem tisku. In tudi v formulah (2.64), (2.65), (2.67), (2.68) na str.138.
- P.142 formula (142). Dodajte 0 za prvo puščico.
- C.142 zadnji odstavek. prej zadnja beseda vstavi minus.
- C.147 prvi odstavek. | L|=l. Tisti. spremenljivka l na desni strani izraza naj bo v poševnem tisku (ker ga različica v knjigi zamenjuje z enoto).
- P.151 formula (2.90). V zgornji vrstici za zavitim oklepajem vstavite F.
- C.151 formula (2.91). Pred vstavi "pri". n.
- C.160 zadnji odstavek v opombi. "z majhno količino" se nadomesti z "z veliko količino".
3. poglavje
- Str.173 Sl.3.1. Spremenljivke naj bodo podane v poševnem tisku v skladu z oznako, sprejeto v knjigi, ker te spremenljivke so skalarne.
- P.176 formule (3.5), (3.7). Mora biti w* namesto w* .
- C.176 zadnja vrstica. Najverjetneje se morate sklicevati, čeprav je to vprašanje mogoče obravnavati tudi v navedenem.
- Str. 179 opomba. Moral bi biti "izpeljanka f(w) glede na w"
- Str.180 zadnja vrstica pred opombo. Namesto tega je morda bolje vzeti in povezava je morda napačna.
- C.184 vmesni izraz v zgornji vrstici formule (3.30). Namesto x(n) moral bi biti x(jaz)
- C.200 odstavek za formulo (3.59). Smejal se je "neenakosti Gucci-Schwartz". Morala bi obstajati dobro znana Cauchyjeva neenakost iz univerzitetnega tečaja stolpa.
- C.204 prvi odstavek razdelka 3.10 govori o preoblikovanju Bayesovega klasifikatorja v linearni separator v Gaussovem okolju. To se nanaša na pogoj, da sta kovariančni matriki obeh razredov enaki (bo predstavljeno v razdelku na str. 207), toda ko rečem "Gaussovo okolje", se običajno spomnim na posplošeno situacijo dveh normalnih porazdelitev s poljubnimi kovariančnimi matrikami , ko se Bayes morda ne degenerira v linearni separator, ampak daje kvadratno ločilno površino.
- C.206 formula (3.77). Nadalje bo namesto λ, navedenega v formuli, v besedilu in na sliki 3.10 večkrat natisnjen Λ.
- Str.216 naloga 3.11. Kar je podano v zgornji meji vsote, moramo premakniti pod znak vsote (minus pa lahko izločimo pred vsoto). Tudi v odstavku za to formulo, namesto w T x moral bi biti w T x
4. poglavje
Moj komentar o poglavju: nočna mora, začetnik v nevronskih mrežah in optimizacijskih metodah, tudi po večkratnem branju poglavja in ponavljajočih se poskusih (namerno ali z zbadanjem), verjetno ne bo znal pravilno programirati usposabljanja nevronskih mrež z uporabo širjenja nazaj. Avtor: vsaj, če upošteva le študente provincialnih tehničnih univerz, je o tem pripravljen polemizirati z dokaj visokimi vložki. Predstavitev je na kup pomešala tako potrebne kot nepomembne stvari, brez poudarjanja in prekompliciranja predstavitve (po pristopu "vse ali nič" namesto postopnega dodajanja postopkov). Plus veliko empirizma. Zakaj ne bi preprosto opisali tehnike za izračun gradienta kompleksne funkcije (nevronske mreže in ciljne funkcije nad njenim izhodom in, če je potrebno, nad lastnostmi nevronske mreže), nato pa, kot v 6. poglavju, napotite bralce na gradient optimizacijske metode brez omejitev (v 6. poglavju se sklicuje na metode kvadratnega programiranja) in predstavi nekaj zgodovinskih primerov pravilnih in napačnih pristopov k uporabi gradienta, ki ga izračuna omrežje, z vidika teorije gradientne optimizacije in maksimiranja stopnje konvergence (stopnja učenja).
Kaj bi še želeli videti v poglavju (ali knjigi). Prvič, ciljne funkcije, razen metode najmanjših kvadratov, zlasti za usposabljanje mreže klasifikatorjev (na primer navzkrižna entropijska funkcija). Drugič, jasnejša izbira možnosti, da imamo objektivno funkcijo, sestavljeno iz več členov: na primeru regularizacije po Tihonovu z eksplicitno minimizacijo, poleg same vrednosti napake, tudi skalarni kvadrat gradienta izhodnih signalov omrežja. z utežmi sinaps (skupno delo LeCuna in Druckerja 1991-92), bodisi na primeru metode iskanja Flat minina Hochreiterja in Schmidhuberja ali na primeru metode CLearning za čiščenje vhodnih signalov omrežja Andreasa Weigenda et. al. Tretjič, podrobnejši opis možnosti izračunavanja sekundnih odvodov v omrežju (navedena dela LeCuna in Druckerja, metode navedene v pregledu). Četrtič, podrobnejši opis metod za izračun informacijske vsebine-uporabnosti različnih elementov in signalov v omrežju (tj. določanje informacijske vsebine vhodov, možnost zmanjšanja ne le sinaps z metodami, opisanimi v knjigi, ampak tudi zmanjšanje celih nevronov, obstaja pa tudi veliko drugih metod). Petič, izrecna navedba (navsezadnje tega bralci ne bodo ugotovili sami) o sposobnosti izračuna gradienta z uporabo vhodnih signalov omrežja (za rešitev inverzni problemi na nevronskih mrežah, usposobljenih za reševanje neposrednega problema, predstaviti metodo CLearning). Poleg tega za to in druga poglavja, kjer se pojavi naloga učenja z učiteljem, podrobneje opišite idejo krivulj učenja za nevronske mreže.
5. poglavje
- Str.357 za formulo (5.23). Naprej na nekaj straneh E je lahko podan v ležečem ali krepkem tisku, sprememba oblike zapisa pa je precej nesistematična. Pravilneje, v ležečem tisku, za E(F), E s (F), E c (F), E(F,h).
- formula C.361 (5.31). Namesto indeksa H moral bi biti H .
- P.363 zadnji odstavek. "...linearna kombinacija..." namesto "...linearna superpozicija...".
- formula C.364 (5.43). Odstranite 1/λ.
- P.367 formula (5.59). σ namesto δ.
- Str.369 za formulo (5.65). Spet bi moralo biti linearna kombinacija" namesto "linearne superpozicije".
- P.373 tretja vrstica formule (5.74). Pred drugim vstavite začetni oklepaj t jaz .
- formula C.382 (5.112). V spodnji meji zneska dodajte "ni enako k".
- C.390 naslov razdelka 5.12. V rusko govoreči znanosti se namesto "jedrne regresije" običajno uporabljajo izrazi "neparametrična regresija" (tako se ta metoda statistike imenuje v ruščini) ali "jedrska regresija" (če jo prevedemo "v čelo").
- Formula S.393 (5.135). Vstavite "...za vse..." kot v (5.139) na naslednji strani.
- P.399 "srednji" odstavek. "...algoritem za združevanje v gruče po k-srednje…", potem beseda "povprečno" ne bo več preskočena.
- C.403 neurejen seznam. Avtorji iz enega eksperimenta delajo preveč globalne in nedvoumne zaključke, čeprav se v mnogih pogledih strinjam.
- P.404 prva točka na seznamu. Nisem razumel, zlasti glede "vpliva na vhodne parametre". Raje kot večjo vrednostλ, manjši je vpliv podatkov na splošno na končne lastnosti modela.
- P.408 prvi odstavek. Dvomljivo sklicevanje na , morda primerno .
- С.408, vrstica 6 odstavka 2. "osnovna funkcija" namesto "temeljna funkcija".
Poglavje 6
- P.431 zadnji stavek pred razdelkom 6.4. Nisem razumel "boljšega" predlagane izbire glede na povprečje vzorca (in zdi se, da sem hkrati dobil pravega b 0 ne bo mogoče).
- Formula S.434 (6.35). Kazalo jaz slednje x ne bi smelo biti.
- P.435 neoštevilčene formule v Mercerjevem izreku. Namesto ψ bi moral biti φ.
- P.444 opomba. Priimek Huber se je v ruščino prevajal kot Huber, ne Gaber (na primer prevod njegove knjige v času Sovjetske zveze: Huber, "Robustness in Statistics").
7. poglavje (ni dokončano)
- P.459 tretja vrstica od zgoraj. Razlaga izraza "šibek učni algoritem" je podana na str.467 v drugem odstavku od zgoraj.
- C.459 neoštevilčeni pododstavki v odstavku 2. Izraz "gateway network" kot prevod izraza "gateway network" je preveč neroden, vendar v ruščini ni druge (in hkrati dobre) možnosti. Verjetno bi bilo bolje uporabiti izraz »utežno omrežje«, ki je univerzalen tako za primer trdega preklopa (množitelji 0 ali 1 za kontrolirani signal) kot za mehko krmiljenje koeficienta slabljenja (množitelji iz območja ).
- S.463 str.2. Iz tega stavka odstranimo delček "ne" - varianca ansambla je manjša od variance posameznih funkcij.
- P.471 prve vrstice. »Zmogljivost« (spomnimo vas, da »zmogljivost-zmogljivost« tukaj ni razumljena v smislu hitrosti, temveč v smislu natančnosti rešitve in posploševanja – glej naš komentar na str. 32) izvirne metode ojačanja odvisno tudi od porazdelitev, ki se oblikujejo med njegovim delovanjem za drugega in naslednje strokovnjake.
- Zadnja vrstica tabele 7.2 C.472. Mora biti F plavut( x)=…
Bibliografija
- Večkrat so besede aplikacija, približek, pristop, uporabljen, podpora, preslikava, uporabnost, zgornji napisane iz enega. str.
- . Pravilno pisanje imena enega od avtorjev si lahko ogledate v .
- . Pravilen priimek Muller je kot priimek njegovega soimenjaka.
- . Prvi avtor - B u ntine.
- . Izdano v istem NIPS kot .
- . Zadnji od avtorjev je pravilno imenovan v .
- . Namesto tedna potrebujemo šibko.
- . Zadnji avtor je pravilno naveden v .
- . Najprej - Landa u.
- . To je poglavje v knjigi.
- . Sch ö lkopf.
- . V naslovu - "... bia s izraz". V dvojini je zapisano pravilno.
- . V naslovu - "...gamm na".
- . ponovi

V smo opisali največ enostavne lastnosti formalni nevroni. Govorili smo o dejstvu, da pragovni seštevalnik natančneje reproducira naravo ene same konice, linearni seštevalnik pa omogoča simulacijo odziva nevrona, sestavljenega iz niza impulzov. Pokazalo se je, da lahko vrednost na izhodu linearnega seštevalnika primerjamo s frekvenco induciranih konic realnega nevrona. Zdaj si bomo ogledali glavne lastnosti, ki jih imajo takšni formalni nevroni.
Hebbov filter
V nadaljevanju se bomo pogosto sklicevali na modele nevronske mreže. Načeloma so skoraj vsi osnovni koncepti iz teorije nevronskih mrež neposredno povezani s strukturo resničnih možganov. Človek, ki se je soočil z določenimi nalogami, je prišel do številnih zanimivih zasnov nevronske mreže. Evolucija je prebirala vse možne živčne mehanizme in izbrala vse, kar se ji je izkazalo za koristno. Ne bi smelo biti presenetljivo, da je za toliko modelov, ki jih je izumil človek, mogoče najti jasne biološke prototipe. Ker naša pripoved ne cilja na podrobnejšo predstavitev teorije nevronskih mrež, se bomo dotaknili le najbolj skupni trenutki potrebno za opis glavnih idej. Za globlje razumevanje toplo priporočam, da se obrnete na specializirano literaturo. Zame je najboljša vadnica o nevronskih mrežah Simon Haykin "Nevronske mreže. Celoten tečaj" (Khaikin, 2006).Številni modeli nevronskih mrež temeljijo na dobro znanem Hebbovem pravilu učenja. Predlagal jo je fiziolog Donald Hebb leta 1949 (Hebb, 1949). V nekoliko ohlapni razlagi ima zelo preprost pomen: povezave nevronov, ki se sprožijo skupaj, naj se okrepijo, povezave nevronov, ki se sprožijo neodvisno, pa oslabijo.
Izhodno stanje linearnega seštevalnika lahko zapišemo:
Če inicializiramo začetne vrednosti uteži z majhnimi vrednostmi in posredujemo različne slike kot vhod, potem nam nič ne preprečuje, da bi poskusili usposobiti ta nevron v skladu s Hebbovim pravilom:
Kje n je diskretni časovni korak, je parameter stopnje učenja.
S tem postopkom povečamo uteži tistih vhodov, na katere se nanaša signal, vendar to storimo toliko močneje, kolikor aktivnejša je reakcija samega treniranega nevrona. Če ni reakcije, potem ni učenja.
Res je, da bodo takšne uteži rasle za nedoločen čas, zato se lahko za stabilizacijo uporabi normalizacija. Na primer, delite z dolžino vektorja, pridobljenega iz "novih" sinaptičnih uteži.
S takim učenjem se uteži prerazporedijo med sinapsami. Bistvo redistribucije lažje razumemo, če spremljamo spremembo uteži v dveh korakih. Prvič, ko je nevron aktiven, tiste sinapse, ki prejmejo signal, prejmejo dodatek. Uteži sinaps brez signala ostanejo nespremenjene. Nato splošna normalizacija zmanjša uteži vseh sinaps. Toda hkrati sinapse brez signalov izgubijo v primerjavi s svojo prejšnjo vrednostjo, sinapse s signali pa te izgube prerazporedijo med seboj.
Hebbovo pravilo ni nič drugega kot implementacija metode gradientnega spuščanja na površino napak. Pravzaprav prisilimo nevron, da se prilagodi danim signalom, pri čemer vsakič premakne svoje uteži v nasprotno smer od napake, torej v smeri antigradienta. Da nas gradientni spust pripelje do lokalnega ekstrema, ne da bi ga presegli, mora biti hitrost spuščanja dovolj majhna. Kaj se pri Hebbovem učenju upošteva z majhnostjo parametra .
Majhnost parametra stopnje učenja nam omogoča, da prejšnjo formulo prepišemo kot niz v:
Če zavržemo člene drugega reda in višje, dobimo pravilo učenja Oja (Oja, 1982):
Pozitiven dodatek je odgovoren za Hebbovo učenje, negativni pa za splošno stabilnost. Snemanje v tej obliki vam omogoča, da občutite, kako je takšno usposabljanje mogoče izvesti v analognem okolju brez uporabe izračunov, ki delujejo samo s pozitivnimi in negativnimi povezavami.
Tako izjemno preprosto usposabljanje ima torej presenetljivo lastnost. Če postopoma zmanjšujemo stopnjo učenja, potem se bodo uteži sinaps treniranega nevrona zbližale do takih vrednosti, da bo njegov izhod začel ustrezati prvi glavni komponenti, ki bi jo dobili, če bi uporabili ustrezne postopke analize glavnih komponent na vhodne podatke. Ta oblika se imenuje Hebbov filter.
Na primer, uporabimo sliko slikovnih pik na vhodu nevrona, kar pomeni, da primerjamo eno točko slike z vsako nevronsko sinapso. Na vhod nevrona bomo podali samo dve sliki - sliki navpičnih in vodoravnih črt, ki potekajo skozi sredino. En učni korak - ena slika, ena črta, vodoravno ali navpično. Če te slike povprečimo, dobimo križec. Toda rezultat treninga ne bo podoben povprečju. To bo ena od vrstic. Tisti, ki bo pogostejši na poslanih slikah. Nevron ne bo poudaril povprečja ali presečišča, temveč tiste točke, ki se najpogosteje pojavljajo skupaj. Če so slike bolj zapletene, rezultat morda ne bo tako jasen. Ampak vedno bo glavna komponenta.
Usposabljanje nevrona vodi do dejstva, da je določena slika poudarjena (filtrirana) na njegovih lestvicah. Ko je dan nov signal, bolj kot je natančno ujemanje med signalom in nastavitvami teže, večji je odziv nevrona. Šolani nevron lahko imenujemo detektorski nevron. V tem primeru sliko, ki jo opisujejo njene uteži, običajno imenujemo značilni dražljaj.
Glavne komponente
Sama ideja analize glavnih komponent je preprosta in genialna. Recimo, da imamo zaporedje dogodkov. Vsako od njih opisujemo skozi njen vpliv na senzorje, s katerimi zaznavamo svet. Recimo, da imamo senzorje, ki opisujejo funkcije. Vse dogodke za nas opisujejo vektorji razsežnosti. Vsaka komponenta takega vektorja kaže na vrednost ustrezne i-te lastnosti. Skupaj tvorijo naključno spremenljivko X . Te dogodke lahko prikažemo kot točke v -dimenzionalnem prostoru, kjer bodo znaki, ki jih opazujemo, delovali kot osi.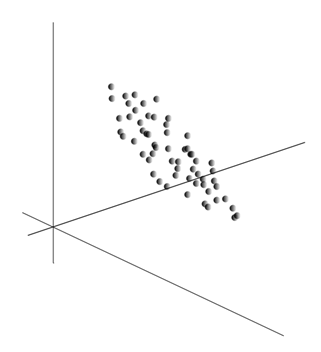
Povprečenje vrednosti daje matematično pričakovanje naključne spremenljivke X, označeno kot E( X). Če podatke centriramo tako, da je E( X)=0, bo oblak točk skoncentriran okoli izhodišča.
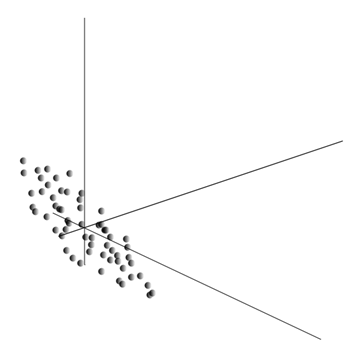
Ta oblak se lahko raztegne v katero koli smer. Poskusil vse možne smeri, lahko najdemo tisto, ob kateri bo varianca podatkov največja.
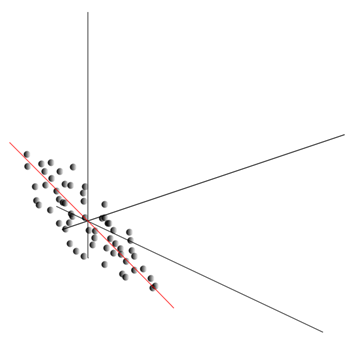
Torej ta smer ustreza prvi glavni komponenti. Sama glavna komponenta je definirana z enotskim vektorjem, ki izhaja iz izvora in sovpada s to smerjo.
Nato lahko najdemo drugo smer, pravokotno na prvo komponento, tako da je vzdolž nje disperzija največja med vsemi pravokotnimi smermi. Ko ga najdemo, dobimo drugo komponento. Nato lahko nadaljujemo z iskanjem ob pogoju, da moramo iskati med smermi pravokotno na že najdene komponente. Če so bile prvotne koordinate linearno neodvisne, potem lahko to naredimo enkrat, dokler se dimenzija prostora ne konča. Tako dobimo medsebojno pravokotne komponente, razvrščene glede na to, kolikšen odstotek variance podatkov pojasnjujejo.
Seveda nastale glavne komponente odražajo notranje zakonitosti naših podatkov. Toda obstajajo enostavnejše značilnosti, ki opisujejo tudi bistvo obstoječih vzorcev.
Recimo, da imamo skupaj n dogodkov. Vsak dogodek je opisan z vektorjem. Komponente tega vektorja so:
Za vsako znamenje lahko zapišete, kako se je pokazalo v vsakem od dogodkov:
Za kateri koli dve značilnosti, na katerih temelji opis, je mogoče izračunati vrednost, ki kaže stopnjo njune skupne manifestacije. Ta vrednost se imenuje kovarianca: 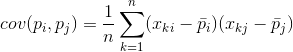
Prikazuje, kako odstopanja od povprečne vrednosti enega od znakov sovpadajo v manifestaciji s podobnimi odstopanji drugega znaka. Če so srednje vrednosti lastnosti enake nič, potem ima kovarianca obliko: 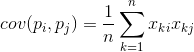
Če popravimo kovarianco za standardne odklone, ki so del funkcij, potem dobimo linearni korelacijski koeficient, imenovan tudi Pearsonov korelacijski koeficient: ![]()
Korelacijski koeficient ima izjemno lastnost. Zajema vrednosti od -1 do 1. Poleg tega 1 pomeni neposredno sorazmernost obeh vrednosti, -1 pa označuje njuno obratno linearno razmerje.
Iz vseh parnih kovarianc lastnosti lahko sestavite kovariančno matriko, ki je, kot zlahka vidite, matematično pričakovanje produkta: ![]()
Tako se izkaže, da za glavne komponente velja:
To pomeni, da so glavne komponente ali, kot jih imenujejo tudi faktorji, lastni vektorji korelacijske matrike. Ustrezajo svojim številkam. Hkrati pa več lastno številko, večji odstotek variance pojasnjuje ta faktor.
Poznavanje vseh glavnih komponent za vsak dogodek, ki je izvedba X
, lahko zapišemo njegove projekcije na glavne komponente:
Tako je mogoče vse začetne dogodke predstaviti v novih koordinatah, koordinatah glavnih komponent: 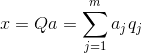
Na splošno se razlikuje med postopkom iskanja glavnih komponent in postopkom iskanja baze faktorjev ter njegovega kasnejšega vrtenja, kar olajša interpretacijo faktorjev, a ker sta si ta postopka ideološko blizu in dajeta podoben rezultat, oboje bomo imenovali faktorska analiza.
Za dokaj preprostim postopkom faktorske analize se skriva zelo globok pomen. Dejstvo je, da če je prostor začetnih značilnosti opazovani prostor, potem so dejavniki značilnosti, ki sicer opisujejo lastnosti okoliškega sveta, vendar so v splošnem primeru (če ne sovpadajo z opazovanimi značilnostmi) skrite. entitete. To pomeni, da nam formalni postopek faktorske analize omogoča prehod od opazovanih pojavov k odkrivanju pojavov, čeprav neposredno nevidnih, vendar kljub temu obstajajo v okoliškem svetu.
Lahko domnevamo, da naši možgani aktivno uporabljajo izbor dejavnikov kot enega od postopkov za spoznavanje sveta okoli nas. Z izolacijo dejavnikov dobimo priložnost zgraditi nove opise tega, kar se nam dogaja. Osnova teh novih opisov je manifestacija v dogajanju tistih pojavov, ki ustrezajo izbranim dejavnikom.
Naj malo razložim bistvo dejavnikov na ravni gospodinjstva. Recimo, da ste kadrovik. K vam pride veliko ljudi in za vsakega izpolnite določen obrazec, kamor zapišete različne opazne podatke o obiskovalcu. Po pregledu vaših zapiskov boste morda ugotovili, da imajo nekateri grafi določeno razmerje. Na primer, moški odbitki bodo v povprečju krajši od ženskih. Najverjetneje boste plešaste ljudi srečali le med moškimi, ustnice si bodo barvale le ženske. Če se uporablja za osebne podatke faktorska analiza, potem se bo prav spol izkazal kot eden od dejavnikov, ki pojasnjuje več vzorcev hkrati. Toda faktorska analiza vam omogoča, da najdete vse dejavnike, ki pojasnjujejo korelacije v nizu podatkov. To pomeni, da bodo poleg spolnega dejavnika, ki ga lahko opazimo, izstopali še drugi, vključno z implicitnimi, neopazljivimi dejavniki. In če se v vprašalniku izrecno pojavi spol, potem drugo pomemben dejavnik ostati med vrsticami. Z ocenjevanjem sposobnosti izražanja misli ljudi, ocenjevanjem njihove karierne uspešnosti, analiziranjem ocen pri diplomi in podobnimi znaki boste prišli do zaključka, da obstaja splošna ocena človekove inteligence, ki ni izrecno zapisana v vprašalniku. , ki pa pojasnjuje veliko njenih točk. Ocena inteligence je skriti dejavnik, glavna sestavina z visokim pojasnjevalnim učinkom. Očitno te komponente ne opazujemo, ampak popravimo lastnosti, ki so z njo povezane. Z življenjskimi izkušnjami lahko podzavestno oblikujemo predstavo o intelektu sogovornika na podlagi določenih znakov. Postopek, ki ga v tem primeru uporabljajo naši možgani, je pravzaprav faktorska analiza. Ko opazujejo, kako se določeni pojavi manifestirajo skupaj, možgani s formalnim postopkom identificirajo dejavnike kot odraz stabilnih statističnih vzorcev, ki so lastni svetu okoli nas.
Izbira nabora faktorjev
Pokazali smo, kako Hebbov filter izloči prvo glavno komponento. Izkazalo se je, da lahko s pomočjo nevronskih mrež zlahka dobite ne le prvo, ampak tudi vse druge komponente. To je mogoče storiti na primer na naslednji način. Recimo, da imamo vhodne funkcije. Vzemimo linearne nevrone, kjer je .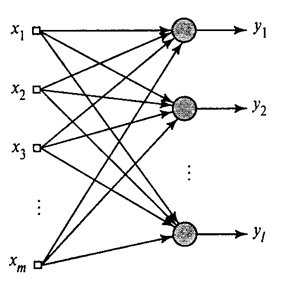
Generalizirani Hebbov algoritem(Haikin, 2006)
Prvi nevron bomo usposobili za Hebbov filter, tako da bo izločil prvo glavno komponento. Toda vsak naslednji nevron bomo trenirali na signalu, iz katerega izključujemo vpliv vseh prejšnjih komponent.
Nevronska aktivnost v koraku n definirano kot 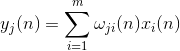
In popravek sinoptičnih uteži kot
kjer je od 1 do in od 1 do .
Za vse nevrone je to videti kot učenje, podobno kot Hebbov filter. Edina razlika je v tem, da vsak naslednji nevron ne vidi celotnega signala, ampak le tisto, česar prejšnji nevroni »niso videli«. To načelo se imenuje ponovno ocenjevanje. Pravzaprav obnovimo prvotni signal z uporabo omejenega nabora komponent in prisilimo naslednji nevron, da vidi le preostanek, razliko med prvotnim signalom in obnovljenim. Ta algoritem se imenuje generalizirani Hebbov algoritem.
Kar ni povsem dobro pri posplošenem Hebbovem algoritmu, je, da je po naravi preveč "računalniški". Nevroni morajo biti urejeni, izračun njihove aktivnosti pa mora potekati strogo zaporedno. To ni preveč združljivo z načeli možganske skorje, kjer vsak nevron, čeprav je v interakciji z drugimi, deluje avtonomno in kjer ni izrazitega »centralnega procesorja«, ki bi določal celotno zaporedje dogodkov. Zaradi teh razlogov so algoritmi, imenovani dekorelacijski algoritmi, videti nekoliko privlačnejši.
Predstavljajte si, da imamo dve plasti nevronov Z 1 in Z 2 . Aktivnost nevronov prve plasti tvori določeno sliko, ki se projicira vzdolž aksonov v naslednjo plast.
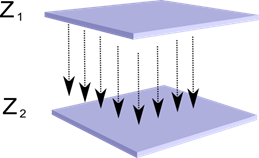
Projekcija ene plasti na drugo
Zdaj si predstavljajte, da ima vsak nevron druge plasti sinaptične povezave z vsemi aksoni, ki prihajajo iz prve plasti, če spadajo v meje določene soseske tega nevrona (slika spodaj). Aksoni, ki vstopajo v tako območje, tvorijo receptivno polje nevrona. Receptivno polje nevrona je tisti delček splošne dejavnosti, ki mu je na voljo za opazovanje. Vse ostalo za ta nevron preprosto ne obstaja.
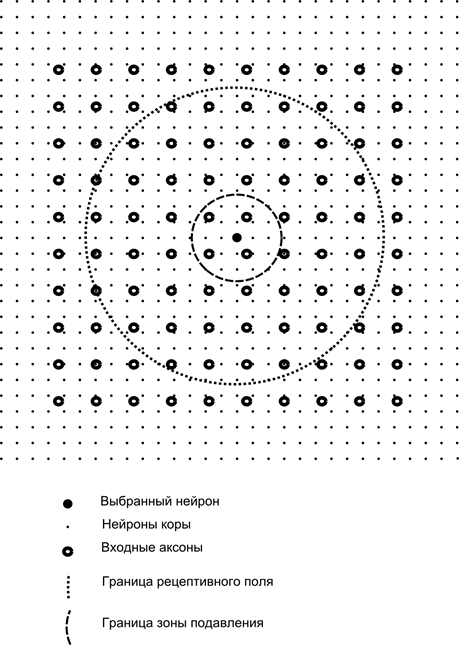
Poleg receptivnega polja nevrona uvedemo območje nekoliko manjše velikosti, ki ga bomo imenovali cona potlačitve. Povežimo vsak nevron z njegovimi sosedi, ki spadajo v to cono. Takšne povezave imenujemo lateralne ali, po terminologiji, sprejeti v biologiji, lateralne. Naredimo stranske povezave zaviralne, to je znižanje aktivnosti nevronov. Logika njihovega dela je, da aktivni nevron zavira delovanje vseh tistih nevronov, ki padejo v njegovo cono inhibicije.
Ekscitatorne in inhibitorne povezave se lahko porazdelijo strogo z vsemi aksoni ali nevroni znotraj meja ustreznih območij ali pa se nastavijo naključno, na primer z gosto zapolnitvijo določenega središča in eksponentnim zmanjšanjem gostote povezav, ko oddaljiti se od tega. Trdno polnilo je lažje modelirati, naključna porazdelitev je bolj anatomska v smislu organizacije povezav v realnem korteksu.
Funkcijo nevronske aktivnosti lahko zapišemo kot:
kjer je končna aktivnost, je nabor aksonov, ki padejo v receptivno območje izbranega nevrona, je nabor nevronov, v katerih cono zatiranja pade izbrani nevron, je moč ustrezne lateralne inhibicije, ki ima negativno vrednote.
Takšna funkcija aktivnosti je rekurzivna, saj se aktivnost nevronov izkaže za odvisno drug od drugega. To vodi k dejstvu, da se praktični izračun izvaja iterativno.
Usposabljanje sinaptičnih uteži poteka podobno kot Hebbov filter:
Stranske uteži se trenirajo v skladu z anti-Hebbovim pravilom, kar povečuje inhibicijo med "podobnimi" nevroni:
Bistvo te zasnove je, da bi moralo Hebbovo učenje voditi do dodelitve vrednosti na nevronskih lestvicah, ki ustrezajo prvemu glavnemu dejavniku, značilnemu za posredovane podatke. Toda nevron se lahko uči v smeri katerega koli dejavnika le, če je aktiven. Ko nevron začne sproščati dejavnik in se ustrezno odziva nanj, začne blokirati aktivnost nevronov, ki spadajo v njegovo območje zatiranja. Če več nevronov trdi, da so aktivirani, potem medsebojna konkurenca vodi do dejstva, da zmaga najmočnejši nevron, medtem ko zatira vse ostale. Drugi nevroni nimajo druge izbire, kot da se učijo v tistih trenutkih, ko v bližini ni sosedov visoka aktivnost. Tako pride do dekorelacije, to je, da vsak nevron znotraj regije, katere velikost je določena z velikostjo cone zatiranja, začne dodeljevati svoj faktor, pravokoten vsem ostalim. Ta algoritem se imenuje algoritem Adaptive Principal Component Extraction (APEX) (Kung S., Diamantaras K.I., 1990).
Zamisel o stranski inhibiciji je po duhu blizu dobro znani različni modeli zmagovalec prevzame vse načelo, ki omogoča tudi dekorelacijo območja, v katerem se išče zmagovalec. Ta princip se uporablja na primer v neokognitronu v Fukušimi, Kohanenovih samoorganizirajočih zemljevidih, ta princip pa se uporablja tudi pri poučevanju dobro znanega hierarhičnega časovnega spomina Jeffa Hawkinsa.
Lahko določite zmagovalca preprosta primerjava aktivnost nevronov. Toda takšno naštevanje, ki ga je enostavno izvesti na računalniku, nekoliko ne ustreza analogiji s pravo skorjo. Če pa si zadamo cilj, da vse naredimo na ravni interakcije nevronov brez vključevanja zunanjih algoritmov, potem lahko dosežemo enak rezultat, če ima nevron poleg lateralne inhibicije sosedov pozitivno povratno informacijo, ki ga dodatno vznemirja. Takšna tehnika iskanja zmagovalca se uporablja na primer v Grossbergovih adaptivnih resonančnih mrežah.
Če ideologija nevronske mreže to omogoča, potem je zelo priročno uporabiti pravilo "zmagovalec prevzame vse", saj je veliko lažje iskati največjo aktivnost kot iterativno izračunati aktivnosti ob upoštevanju medsebojnega zaviranja.
Čas je, da končamo ta del. Izkazalo se je dovolj dolgo, vendar res nisem želel razdeliti pomensko povezane pripovedi. Naj vas KDPV ne preseneti, ta slika je bila zame povezana hkrati z umetno inteligenco in glavnim dejavnikom.
Ta članek vsebuje materiale - večinoma v ruskem jeziku - za osnovno študijo umetnih nevronskih mrež.
Umetna nevronska mreža ali ANN - matematični model, kot tudi njegova programska ali strojna izvedba, zgrajena na principu organizacije in delovanja bioloških nevronskih mrež – mrež živčne celiceživi organizem. Znanost o nevronskih mrežah obstaja že dolgo, vendar je ravno v povezavi z najnovejši dosežki znanstvenega in tehnološkega napredka je to področje začelo pridobivati na priljubljenosti.
knjige
Začnimo z zbirko klasičen načinštudij – s pomočjo knjig. Izbrali smo knjige v ruskem jeziku z velikim številom primerov:
- F. Wasserman, Nevroračunalniški inženiring: teorija in praksa. 1992
Knjiga oriše osnove gradnje nevroračunalnikov v javni obliki. Opisana je struktura nevronskih mrež in različni algoritmi za njihovo uravnavanje. Ločena poglavja so posvečena implementaciji nevronskih mrež. - S. Khaikin, Nevronske mreže: Celoten tečaj. 2006
Tu so obravnavane glavne paradigme umetnih nevronskih mrež. Predstavljeno gradivo vsebuje strogo matematično utemeljitev vseh paradigem nevronske mreže, je ilustrirano s primeri, opisom računalniških poskusov, vsebuje nabor praktične naloge kot tudi obsežno bibliografijo.
D. Forsyth, Računalniški vid. Sodoben pristop. 2004
Računalniški vid je eno najbolj iskanih področij na tej stopnji razvoja globalnih digitalnih računalniških tehnologij. Potreben je v proizvodnji, krmiljenju robotov, avtomatizaciji procesov, medicinskih in vojaških aplikacijah, satelitskem nadzoru in delu z osebnimi računalniki, kot je iskanje digitalnih slik.
Video
Nič ni bolj dostopnega in razumljivega kot vizualno učenje z uporabo videa:
- Če želite razumeti, kaj je strojno učenje na splošno, poglejte tukaj. ti dve predavanji iz ShaD Yandex.
- Uvod osnovnim načelom načrtovanja nevronskih mrež – odlično za nadaljnje raziskovanje nevronskih mrež.
- Tečaj predavanja na temo "Računalniški vid" iz VMK MSU. Računalniški vid je teorija in tehnologija za ustvarjanje umetnih sistemov, ki zaznavajo in razvrščajo predmete v slikah in videih. Ta predavanja lahko pripišemo uvodu v to zanimivo in kompleksno vedo.
Izobraževalni viri in uporabne povezave
- Portal umetne inteligence.
- Laboratorij "Jaz sem intelekt".
- Nevronske mreže v Matlabu.
- Nevronske mreže v Pythonu (angleščina):
- Klasifikacija besedila z ;
- Enostavno.
- Nevronska mreža na.
Serija naših publikacij na to temo
Tečaj smo že objavili #neuralnetwork@tproger z nevronskimi mrežami. Na tem seznamu so za vaše udobje publikacije razvrščene po vrstnem redu študija.

