Прясно преведеният фундаментален учебник на С. Хайкин (преведено е второто американско издание от 1999 г.) с пълна сила претендира да бъде събитието на 2006 г. в руската литература по невроинформатика. Но трябва да се отбележи, че въпреки че преводът е извършен без очевидни грешки, бележките под линия и коментарите от преводачите няма да навредят на изясняването на терминологията (тъй като едно и също нещо може да се нарече в невроинформатиката, статистиката и идентификацията на системата с различни думи, това е необходимо или да се намалят термините до една област, или да се дадат списъци със синоними - не всички читатели ще имат широка перспектива). Коментарите могат също така да отразяват напредъка в областта на изкуствените невронни мрежи, настъпил след публикуването на англоезичния оригинал. Надявам се, че книгата ще бъде търсена и че ще бъдат направени промени, когато изданието бъде препечатано. Освен това има значителен брой правописни грешки в математическите формули. Тази страница е посветена основно на коригиране на правописни грешки. Но трябва да се отбележи, че не гарантирам пълнотата на списъка с неточности, даден тук - прочетох книгата „по диагонал“, на пристъпи различни степенивнимание, така че може да съм пропуснал нещо (или сам да съм сгрешил).
Глава 1
- P.32 втори параграф. Само тук думата „производителност“ може да се разбира като скорост на работа, мощност на компютъра. По-нататък в книгата „производителност“ ще означава точност, качеството на работата на невронната мрежа (например на стр. 73 във втория параграф отдолу).
- стр.35 стр.7. „VLSI Implementability“ е по-добре да се преведе не като „скалируемост“, а като „ефективна приложимост на VLSI - много големи интегрални схеми“.
- стр.39 стр.7. Думата "шип" - "емисия, импулс" в рускоезичната неврология доста често и обичайно се транслитерира просто като "шип".
- P.49 заглавие на параграф. Може би по-добрият термин би бил "насочена графика" вместо "насочена графика".
- P.76 трети параграф. Вместо връзка, вероятно трябва да има връзка към книгата на Ашби.
- P.99 заключение 1. Необходимо е също така да се добави случай на едновременно изпълнение на същите тези условия и със знака "
- P.105 параграф 2. Трябва да вмъкнете думата „видим“ преди (видим).
Глава 2
- P.94 бележка под линия 2. Позоваването на най-вероятно е неправилно, защото Това не е книга и заглавието не й подхожда.
- P.122 последен параграф. Засмях се на фразата „деформация на структурата на невроните“: докато външното събитие на сътресение не бъде удовлетворено, човек няма да си спомни това събитие. Най-вероятно се твърди, че паметта се реализира само чрез прекъсване на синаптичните входове (терминали) от пипалата на дендритите или превключване от едно пипало към друго (термини от фиг. 1.2 на стр. 40, тъй като тази фигура е много подходяща за илюстрация) . Тези. Нашите мозъци са живи и се движат.
- P.129 формула (2.39). Вместо хтрябва да има х.
- P.129 формули (2.40), (2.41), (2.44). Горният индекс трябва да бъде рвместо м.
- P.137 първи параграф и формула (2.61). E трябва да е в курсив. И във формули (2.64), (2.65), (2.67), (2.68) на стр. 138 също.
- P.142 формула (142). Добавете 0 след първата стрелка.
- P.142 последен параграф. Преди последната думавмъкнете "минус".
- P.147 първи параграф. | Л|=л. Тези. променлива лот дясната страна на израза трябва да бъде даден в курсив (тъй като версията в книгата го бърка с един).
- P.151 формула (2.90). Вмъкнете в горния ред след фигурната скоба Е.
- C.151 формула (2.91). Поставете "при" преди н.
- C.160 последния параграф в бележка под линия. „за малки количества“ следва да се замени с „за големи количества“.
Глава 3
- P.173 Фиг.3.1. Променливите трябва да бъдат дадени в курсив в съответствие с нотацията, използвана в книгата, т.к тези променливи са скаларни.
- P.176 формули (3.5), (3.7). Трябва да е w* вместо w* .
- C.176 последен ред. Най-вероятно трябва да се обърнете към, въпреки че този проблем може да бъде разгледан и в посочения.
- P.179 бележка под линия. Трябва да бъде "производна на f(w) по отношение на w"
- P.180 последен ред преди бележката под линия. Може би е по-добре да вземете вместо това, но връзката може да е неправилна.
- P.184 междинен израз в горния ред на формула (3.30). Вместо х(н) би трябвало х(аз)
- P.200 параграф след формула (3.59). Смях се на "неравенството Гучи-Шварц". Трябва да има неравенството на Коши-Шварц, което е известно на всички от университетския курс.
- P.204, първият параграф на раздел 3.10 е за превръщането на байесов класификатор в линеен разделител в среда на Гаус. Това се отнася до условието ковариационните матрици на двата класа да са идентични (ще бъде въведено в раздела на стр. 207), но когато чуя фразата „Гаусова среда“, обикновено си спомням обобщената ситуация на две нормални разпределения с произволна ковариация матрици, когато Бейс може да не се изроди в линеен разделител, но да даде квадратна разделителна повърхност.
- P.206 формула (3.77). След това, вместо λ, посочено във формулата, Λ ще бъде отпечатано няколко пъти в текста и на фиг. 3.10.
- С.216 задача 3.11. Това, което е дадено в горната граница на сумата, трябва да се премести под знака за сумата (като минусът може да се постави пред сумата). Също така в параграфа след тази формула, вместо w T хтрябва да има w T х
Глава 4
Моят коментар за главата: кошмар, начинаещ в невронните мрежи и методите за оптимизация, дори след прочитане на главата няколко пъти и многократни опити (или целенасочено, или на случаен принцип), е малко вероятно да програмира правилно обучението на невронна мрежа, използвайки обратно разпространение метод. от поне, когато разглеждам само студенти от провинциални технически университети, съм готов да споря за това с доста високи залози. Презентацията смеси както необходими, така и ненужни неща на купчина, без да поставя акценти и да усложнява презентацията (приемайки подход „всичко или нищо“ вместо добавяне стъпка по стъпка на процедури). Плюс много емпирии. Защо просто не очертаете методологията за изчисляване на градиента на сложна функция (невронна мрежа плюс целева функция върху нейния изход и, ако е необходимо, върху свойствата на невронната мрежа), след което, както в Глава 6, насочете читателите към градиента методи за оптимизация без ограничения (в глава 6 препратката отива към методите за квадратично програмиране) и очертайте няколко исторически примера за правилни и неправилни подходи за използване на мрежово изчислени градиенти от гледна точка на теорията за градиентна оптимизация и максимизиране на скоростта на конвергенция (степен на учене).
Какви допълнителни неща бихте искали да видите в главата (или книгата). Първо, обективни функции, различни от най-малките квадрати, особено за обучение на мрежа от класификатори (например крос-ентропийна функция). Второ, по-ясно подчертаване на възможността за наличие на целева функция, състояща се от няколко термина: използване на примера за регулация според Тихонов чрез изрично минимизиране, в допълнение към самата стойност на грешката, също и на градиента на скаларния квадрат на мрежовите изходни сигнали чрез синапсни тегла (съвместна работа на LeCun и Drucker 1991-92), или използвайки примера на метода за търсене на Flat minina на Hochreiter и Schmidhuber, или примера на метода CLearning за почистване на мрежови входни сигнали от Andreas Weigend et al. Трето, по-подробно описание на възможността за изчисляване на втори производни в мрежата (посочени произведения на LeCun и Drucker, методи, изброени в рецензията). Четвърто, по-подробно описание на методите за изчисляване на полезността на информационното съдържание на различни елементи и сигнали в мрежата (т.е. определяне на информационното съдържание на входовете, възможността за намаляване не само на синапсите с помощта на методите, описани в книгата, но и намаляване на цели неврони, а също така има много опции за намаляване на синапсите други методи). Пето, има изрична индикация (читателите няма да го разберат сами) за способността да се изчисли градиентът, използвайки входните сигнали на мрежата (за решаване на обратни задачивърху невронни мрежи, обучени да решават директен проблем, за да представят метода CLearning). Плюс това, за тази и други глави, където възниква задачата за контролирано обучение, опишете по-подробно идеята за кривите на обучение за невронни мрежи.
Глава 5
- P.357 след формула (5.23). По-нататък на няколко страници дможе да бъде даден в курсив или удебелен шрифт и промяната на формата на писане е доста случайна. По-правилно - в курсив, за E(F), E s (F), E c (F), E(F,h).
- P.361 формула (5.31). Вместо индекс зтрябва да има з .
- P.363 последен параграф. "...чрез линейна комбинация..." вместо "...чрез линейна суперпозиция...".
- P.364 формула (5.43). Премахнете 1/λ.
- P.367 формула (5.59). σ вместо δ.
- P.369 след формула (5.65). трябва да има отново" линейна комбинация" вместо "линейна суперпозиция".
- P.373 трети ред от формула (5.74). Поставете отваряща скоба преди втората T аз .
- P.382 формула (5.112). В долната граница на сумата добавете „не е равно на к".
- P.390 заглавие на раздел 5.12. В рускоезичната наука вместо „ядрена регресия“ обикновено се използват термините „непараметрична регресия“ (така се нарича този метод на статистика на руски) или „ядрена регресия“ (ако се превежда „челно“).
- P.393 формула (5.135). Вмъкнете „...за всички...“ както в (5.139) на следващата страница.
- P.399 „среден“ параграф. „...алгоритъм за групиране от к-средно аритметично...“, тогава думата „средно“ вече няма да се пропуска.
- P.403 неномериран списък. Авторите правят твърде глобални и недвусмислени заключения от един експеримент, въпреки че до голяма степен са съгласни.
- P.404 е първият елемент в списъка. Не разбирам, особено по отношение на „влиянието върху входните параметри“. Отколкото повече стойностλ, толкова по-малко влияние имат данните като цяло върху крайните свойства на модела.
- P.408 първи параграф. Връзката към е съмнителна, може би ще работи.
- P.408 ред 6 от параграф 2. „основна функция“ вместо „основна функция“.
Глава 6
- P.431 последно изречение преди раздел 6.4. Не разбрах „по-доброто“ на предложения избор чрез средната извадка (и изглежда, че получавам правилното b 0няма да е възможно).
- P.434 формула (6.35). Индекс азпоследният хне трябва да има.
- P.435 неномерирани формули в теоремата на Мърсър. Вместо ψ трябва да има φ.
- P.444 бележка под линия. Фамилното име Huber преди това е преведено на руски като Huber, а не Haber (например преводът на книгата му по време на СССР: Huber, „Устойчивост в статистиката“).
Глава 7 (не напълно)
- P.459 трети ред отгоре. Дефиницията на термина „слаб алгоритъм за обучение” е дадена на стр. 467 във втория параграф отгоре.
- P.459 неномерирани подпараграфи в параграф 2. Терминът „шлюзова мрежа“ като превод на термина „шлюзова мрежа“ е твърде тромав, но все още няма друга (и добра) опция на руски. Вероятно би било по-добре да се използва терминът „претегляща мрежа“, който е универсален както за случая на твърдо превключване (множители от 0 или 1 за контролирания сигнал), така и за меко управление на коефициента на затихване (множители от диапазона).
- P.463 p.2. Премахваме частицата „не“ от това изречение - дисперсията на ансамбъла е по-малка от дисперсията на отделните функции.
- P.471 първи редове. „Ефективност“ (напомняме ви, че „производителност“ тук се разбира не в смисъл на скорост, а в смисъл на точност на решение и обобщение – вижте нашия коментар на стр. 32) на оригиналния метод на усилване също зависи от разпределенията формирана по време на нейното функциониране за втори и следващи експерти.
- P.472 таблица 7.2 последен ред. Трябва да е Еперка ( х)=…
Библиография
- Много пъти думите приложение, приближение, подход, приложен, опора, картографиране, приложимост, горен се пишат с едно стр.
- . Правилно писанеИмената на един от авторите могат да се видят в.
- . Правилното фамилно име на Мюлер е същото като на съименника му.
- . Първи автор - Б u ntine.
- . Издаден в същия NIPS като .
- . Последният от авторите е правилно посочен в.
- . Трябва ни слаба вместо седмица.
- . Последният автор е правилно посочен в .
- . Първо - Ланда u.
- . Това е глава в книга.
- . Sch ö lkopf.
- . В заглавието - „…bia ссрок". В дубликата е изписано правилно.
- . В заглавието – „…gamm На".
- . Повторете.

В описахме най-много прости свойстваформални неврони. Говорихме за факта, че праговият суматор по-точно възпроизвежда природата на един пик, а линейният суматор ви позволява да симулирате реакцията на неврон, състоящ се от поредица от импулси. Те показаха, че стойността на изхода на линеен суматор може да се сравни с честотата на предизвиканите пикове на истински неврон. Сега ще разгледаме основните свойства, които имат такива формални неврони.
Филтър на Хеб
В това, което следва, често ще се позоваваме на модели на невронни мрежи. По принцип почти всички основни понятия от теорията на невронните мрежи са пряко свързани със структурата на реалния мозък. Човек, изправен пред определени проблеми, излезе с много интересни дизайни на невронни мрежи. Еволюцията, преминавайки през всички възможни невронни механизми, подбра всичко, което се оказа полезно за нея. Не е изненадващо, че за много модели, изобретени от човека, могат да бъдат намерени ясни биологични прототипи. Тъй като нашият разказ няма за цел да представи в подробности теорията на невронните мрежи, ще се докоснем само до най- общи точкинеобходими за описание на основните идеи. За по-задълбочено разбиране силно препоръчвам да се обърнете към специализирана литература. За мен най-добрият учебник по невронни мрежи е „Невронни мрежи“ на Саймън Хайкин. Пълен курс" (Khaikin, 2006).Много модели на невронни мрежи се основават на добре известното правило за обучение на Hebbian. Предложено е от физиолога Доналд Хеб през 1949 г. (Hebb, 1949). В малко свободна интерпретация има много просто значение: връзките между невроните, които се задействат заедно, трябва да бъдат засилени, връзките между невроните, които се задействат независимо, трябва да отслабнат.
Изходното състояние на линейния суматор може да бъде написано:
Ако инициираме първоначалните стойности на теглата с малки стойности и предоставим различни изображения като вход, тогава нищо не ни пречи да се опитаме да обучим този неврон според правилото на Хеб:
Където н– дискретна времева стъпка, – параметър на скоростта на обучение.
С тази процедура увеличаваме теглата на тези входове, към които се прилага сигналът, но правим това толкова по-силно, колкото по-активна е реакцията на самия обучаващ се неврон. Ако няма реакция, тогава обучението не се случва.
Вярно е, че такива тегла ще нарастват неограничено, така че нормализирането може да се приложи за стабилизиране. Например, разделете на дължината на вектора, получен от „новите“ синаптични тегла.
При такова обучение тежестите се преразпределят между синапсите. По-лесно е да разберете същността на преразпределението, ако наблюдавате промяната в теглата на два етапа. Първо, когато един неврон е активен, тези синапси, които получават сигнал, получават добавка. Теглата на синапсите без сигнал остават непроменени. След това общото нормализиране намалява теглата на всички синапси. Но в същото време синапсите без сигнали губят в сравнение с предишната си стойност, а синапсите със сигнали преразпределят тези загуби помежду си.
Правилото на Хеб не е нищо повече от прилагане на метода на градиентно спускане по повърхността на грешката. По същество ние принуждаваме неврона да се адаптира към подадените сигнали, като всеки път измества своите тежести в посока, обратна на грешката, тоест в посока на антиградиента. За да може градиентното спускане да ни доведе до локален екстремум, без да го превишаваме, скоростта на спускане трябва да е доста ниска. Което в Hebbian обучението се взема предвид от малкия параметър.
Малкият параметър на скоростта на обучение ни позволява да пренапишем предишната формула като серия в:
Ако отхвърлим термини от втори ред и по-високи, получаваме правилото за обучение на Oja (Oja, 1982):
Положителната добавка е отговорна за Hebbian обучението, а отрицателната добавка е отговорна за общата стабилност. Записването в тази форма ви позволява да почувствате как подобно обучение може да се приложи в аналогова среда без използване на изчисления, опериращи само с положителни и отрицателни връзки.
И така, такова изключително просто обучение има невероятно свойство. Ако постепенно намалим скоростта на обучение, теглата на синапсите на тренирания неврон ще се сближат до такива стойности, че неговият изход започва да съответства на първия главен компонент, който би се получил, ако приложим подходящите процедури за анализ на главния компонент към предоставените данни. Този дизайн се нарича филтър на Хеб.
Например, нека подадем пикселно изображение към входа на неврон, тоест свързваме една точка на изображението към всеки синапс на неврона. Ще подадем само две изображения на входа на неврона - изображения на вертикални и хоризонтални линии, минаващи през центъра. Една стъпка на обучение - едно изображение, една линия, хоризонтална или вертикална. Ако тези изображения се осреднят, получавате кръст. Но резултатът от обучението няма да бъде подобен на осредняването. Това ще бъде една от линиите. Този, който ще се появява по-често в изпратените изображения. Невронът няма да подчертае осредняване или пресичане, а онези точки, които най-често се срещат заедно. Ако изображенията са по-сложни, резултатът може да не е толкова ясен. Но това винаги ще бъде основният компонент.
Обучението на неврон води до факта, че определено изображение се подчертава (филтрира) на неговите скали. Когато се даде нов сигнал, колкото по-точно е съвпадението между сигнала и настройките на теглото, толкова по-висока е реакцията на неврона. Обучен неврон може да се нарече детекторен неврон. В този случай изображението, което се описва от неговите мащаби, обикновено се нарича характерен стимул.
Главни компоненти
Самата идея на метода на главния компонент е проста и гениална. Да кажем, че имаме последователност от събития. Описваме всеки от тях чрез влиянието му върху сензорите, с които възприемаме света. Да кажем, че имаме сензори, които описват функции. Всички събития за нас се описват чрез вектори на измерение. Всеки компонент на такъв вектор показва стойността на съответния ти атрибут. Заедно те образуват случайна променлива х . Можем да изобразим тези събития като точки в -измерното пространство, където осите ще бъдат знаците, които наблюдаваме.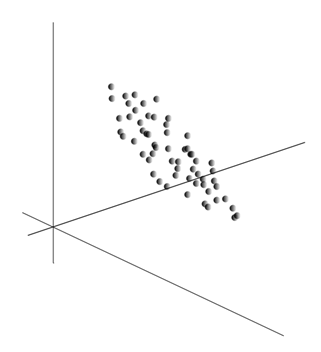
Осредняването на стойности дава математическото очакване на случайна променлива х, означен като E( х). Ако центрираме данните така, че E( х)=0, тогава облакът от точки ще бъде концентриран около началото.
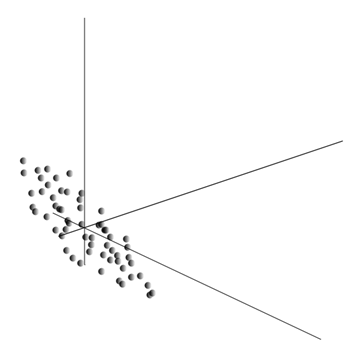
Този облак може да бъде удължен във всяка посока. Опитвайки всичко възможни посоки, можем да намерим такава, по която дисперсията на данните ще бъде максимална.
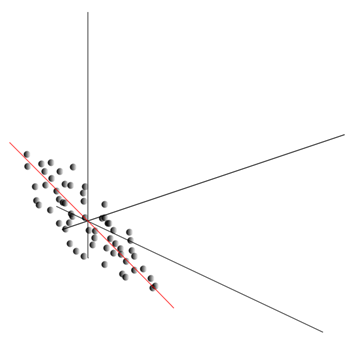
И така, тази посока съответства на първия главен компонент. Самият главен компонент се определя от единичен вектор, излизащ от началото и съвпадащ с тази посока.
След това можем да намерим друга посока, перпендикулярна на първия компонент, така че по протежение на нея дисперсията също да е максимална сред всички перпендикулярни посоки. След като го намерихме, получаваме втория компонент. След това можем да продължим търсенето, като поставим условието да търсим между посоките, перпендикулярни на вече намерените компоненти. Ако първоначалните координати бяха линейно независими, тогава можем да направим това веднъж, докато измерението на пространството свърши. Така ще получим взаимно ортогонални компоненти, подредени според това какъв процент от дисперсията в данните обясняват.
Естествено, получените основни компоненти отразяват вътрешните модели на нашите данни. Но има по-прости характеристики, които също описват същността на съществуващите модели.
Да приемем, че имаме общо n събития. Всяко събитие се описва с вектор. Компоненти на този вектор:
За всеки знак можете да запишете как се е проявил във всяко от събитията:
За всеки две характеристики, на които се основава описанието, е възможно да се изчисли стойност, показваща степента на тяхното съвместно проявление. Това количество се нарича ковариация: 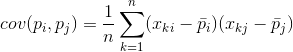
Той показва как отклоненията от средната стойност на една от характеристиките съвпадат по проява с подобни отклонения на друга характеристика. Ако средните стойности на характеристиките са равни на нула, тогава ковариацията приема формата: 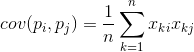
Ако коригираме ковариацията за стандартните отклонения, присъщи на характеристиките, получаваме линеен корелационен коефициент, наричан също корелационен коефициент на Пиърсън: ![]()
Коефициентът на корелация има забележително свойство. Приема стойности от -1 до 1. Освен това 1 означава пряка пропорционалност на две количества, а -1 показва тяхната обратна линейна зависимост.
От всички двойки ковариации на характеристики можем да създадем ковариационна матрица, която, както лесно можете да видите, е математическото очакване на продукта: ![]()
Така се оказва, че за основните компоненти е вярно следното:
Тоест основните компоненти или, както се наричат още, фактори, са собствени вектори на корелационната матрица. Те съответстват на собствените стойности. В същото време, толкова повече собствена стойност, толкова по-голям е процентът на дисперсията, обяснен с този фактор.
Познаване на всички основни компоненти, за всяко събитие, което е реализация х
, можем да запишем неговите проекции върху главните компоненти:
По този начин е възможно да се представят всички първоначални събития в нови координати, координатите на главните компоненти: 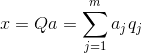
Като цяло се прави разлика между процедурата за търсене на главни компоненти и процедурата за намиране на база от фактори и нейното последващо въртене, което улеснява интерпретацията на факторите, но тъй като тези процедури са идеологически близки и дават подобен резултат, ние ще нарече и двата факторни анализа.
Зад сравнително простата процедура на факторния анализ се крие много дълбок смисъл. Факт е, че ако пространството на първоначалните характеристики е наблюдаемо пространство, тогава факторите са характеристики, които, въпреки че описват свойствата на околния свят, в общия случай (ако не съвпадат с наблюдаваните характеристики) са скрити единици. Тоест формалната процедура на факторния анализ ни позволява да преминем от наблюдавани явления към откриване на явления, макар и директно невидими, но въпреки това съществуващи в околния свят.
Може да се предположи, че нашият мозък активно използва подбора на фактори като една от процедурите за разбиране на света около нас. Идентифицирайки факторите, ние получаваме възможност да изградим нови описания на случващото се с нас. Основата на тези нови описания е изразяването в случващото се на онези явления, които съответстват на идентифицираните фактори.
Нека обясня малко същността на факторите на битово ниво. Да приемем, че сте мениджър човешки ресурси. Много хора идват при вас и за всеки от тях попълвате определена форма, където записвате различни видими данни за посетителя. След като прегледате бележките си по-късно, може да откриете, че някои графики имат определена връзка. Например мъжките прически ще бъдат средно по-къси от женските. Най-вероятно ще срещнете плешиви хора само сред мъжете и само жените ще носят червило. Ако се прилага за лични данни факторен анализ, тогава полът ще бъде един от факторите, които обясняват няколко модела наведнъж. Но факторният анализ ви позволява да намерите всички фактори, които обясняват корелациите в набор от данни. Това означава, че в допълнение към фактора пол, който можем да наблюдаваме, ще има и други, включително имплицитни, ненаблюдаеми фактори. И ако полът се появява изрично във въпросника, тогава друг важен факторще остане между редовете. Оценявайки способността на хората да изразяват мислите си, оценявайки техния успех в кариерата, анализирайки оценките от дипломата им и подобни признаци, ще стигнете до извода, че има обща класациячовешка интелигентност, което не е изрично записано във въпросника, но което обяснява много от точките му. Оценката на интелигентността е това, което е скрит фактор, основен компонент с висок обяснителен ефект. Ние не наблюдаваме изрично този компонент, но записваме признаци, които са свързани с него. Имайки житейски опит, можем подсъзнателно да формираме представа за интелигентността на нашия събеседник въз основа на определени характеристики. Процедурата, която нашият мозък използва в този случай, е по същество факторен анализ. Наблюдавайки как определени явления се появяват заедно, мозъкът, използвайки формална процедура, идентифицира факторите като отражение на стабилни статистически модели, присъщи на света около нас.
Идентифициране на набор от фактори
Показахме как филтърът на Хеб избира първия главен компонент. Оказва се, че с помощта на невронни мрежи можете лесно да получите не само първия, но и всички останали компоненти. Това може да стане например по следния начин. Да приемем, че имаме входни функции. Да вземем линейните неврони, където .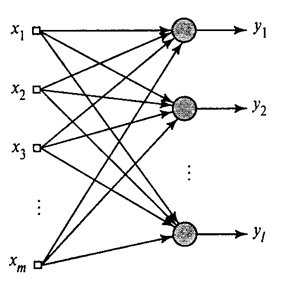
Обобщен алгоритъм на Хеб(Хайкин, 2006)
Ще обучим първия неврон като филтър на Хеб, така че да избере първия главен компонент. Но ние ще обучим всеки следващ неврон на сигнал, от който ще изключим влиянието на всички предишни компоненти.
Невронна активност по време на стъпка нопределен като 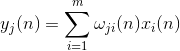
И корекцията на синоптичните тегла е като
където от 1 до и от 1 до .
За всички неврони това изглежда като обучение, подобно на филтър на Хеб. Единствената разлика е, че всеки следващ неврон не вижда целия сигнал, а само това, което предишните неврони „не са видели“. Този принцип се нарича преоценка. Ние всъщност възстановяваме оригиналния сигнал от ограничен набор от компоненти и принуждаваме следващия неврон да вижда само остатъка, разликата между оригиналния сигнал и възстановения. Този алгоритъм се нарича обобщен алгоритъм на Хеб.
Това, което не е съвсем добро за обобщения алгоритъм на Hebb, е, че той е твърде „изчислителен“ по природа. Невроните трябва да бъдат подредени и тяхната активност трябва да се брои строго последователно. Това не е много съвместимо с принципите на работа на мозъчната кора, където всеки неврон, въпреки че взаимодейства с останалите, работи автономно и където няма ясно дефиниран „централен процесор“, който да определя цялостната последователност от събития. Поради тези причини алгоритмите, наречени алгоритми за декорелация, изглеждат малко по-привлекателни.
Нека си представим, че имаме два слоя неврони Z 1 и Z 2. Активността на невроните в първия слой формира определена картина, която се проектира по аксоните към следващия слой.
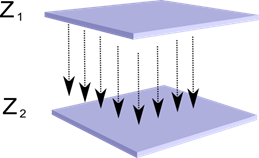
Проекция на един слой върху друг
Сега си представете, че всеки неврон от втория слой има синаптични връзки с всички аксони, идващи от първия слой, ако попадат в границите на определен квартал на този неврон (фигурата по-долу). Аксоните, навлизащи в такава област, образуват рецептивното поле на неврона. Рецептивното поле на неврона е този фрагмент от общата активност, който му е достъпен за наблюдение. Всичко останало просто не съществува за този неврон.
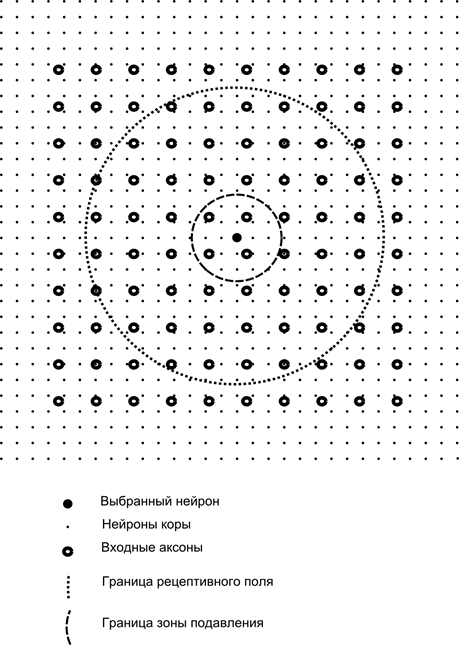
В допълнение към рецептивното поле на неврона ще въведем малко по-малка област, която ще наречем зона на потискане. Нека свържем всеки неврон с неговите съседи, които попадат в тази зона. Такива връзки се наричат латерални или, според приетата в биологията терминология, латерални. Нека направим страничните връзки инхибиторни, тоест намаляване на активността на невроните. Логиката на тяхната работа е, че един активен неврон инхибира активността на всички онези неврони, които попадат в неговата зона на инхибиране.
Възбуждащите и инхибиторните връзки могат да бъдат разпределени стриктно с всички аксони или неврони в границите на съответните области или могат да бъдат определени произволно, например с плътно запълване на определен център и експоненциално намаляване на плътността на връзките като един отдалечава се от него. Непрекъснатото запълване е по-лесно за моделиране; произволното разпределение е по-анатомично от гледна точка на организацията на връзките в реалната кора.
Функцията на невронната активност може да бъде записана:
където е крайната активност, е наборът от аксони, попадащи в рецептивната област на избрания неврон, е наборът от неврони, в зоната на потискане, от които избраният неврон попада, и е силата на съответното странично инхибиране, което приема отрицателни стойности.
Тази функция на активност е рекурсивна, тъй като активността на невроните се оказва зависима една от друга. Това води до факта, че практическите изчисления се извършват итеративно.
Обучението на синаптичните тежести се извършва подобно на филтъра на Хеб:
Страничните тежести се учат според антихебийското правило, увеличавайки инхибирането между „подобни“ неврони:
Същността на този дизайн е, че Hebbian обучението трябва да доведе до разпределяне на невронните скали на стойности, съответстващи на първия основен фактор, характерен за предоставените данни. Но невронът може да се учи в посока на който и да е фактор само ако е активен. Когато невронът започне да отделя фактор и съответно да реагира на него, той започва да блокира активността на невроните, попадащи в неговата зона на потискане. Ако няколко неврона се конкурират за активиране, тогава взаимната конкуренция води до факта, че най-силният неврон печели, като същевременно потиска всички останали. Други неврони нямат друг избор, освен да се учат в онези моменти, когато наблизо няма съседи с тях. висока активност. По този начин възниква декорелация, тоест всеки неврон в рамките на зоната, чийто размер се определя от размера на зоната на потискане, започва да подчертава свой собствен фактор, ортогонален на всички останали. Този алгоритъм се нарича алгоритъм за адаптивно извличане на главни компоненти (APEX) (Kung S., Diamantaras K.I., 1990).
Идеята за странично инхибиране е близка по дух до добре познатата различни моделипринципът „победителят взема всичко“, който също позволява декориране на зоната, в която се търси победителят. Този принцип се използва например в неокогнитрона във Фукушима, самоорганизиращите се карти на Коханен и този принцип се използва и при обучението на добре известната йерархична времева памет на Джеф Хокинс.
Можете да определите победителя просто сравнениеневронна активност. Но такова търсене, лесно реализирано на компютър, е донякъде несъвместимо с аналогиите с реалния кортекс. Но ако си поставите за цел да направите всичко на ниво взаимодействие между невроните, без да включвате външни алгоритми, тогава същият резултат може да бъде постигнат, ако в допълнение към страничното инхибиране на съседите невронът има положителна обратна връзка, която го вълнува. Тази техника за намиране на победител се използва например в адаптивните резонансни мрежи на Гросберг.
Ако идеологията на невронната мрежа позволява това, тогава използването на правилото „победителят взема всичко“ е много удобно, тъй като търсенето на максимална активност е много по-просто от итеративното изчисляване на дейностите, като се вземе предвид взаимното инхибиране.
Време е да завършим тази част. Оказа се доста дълго, но наистина не исках да разделям свързания по смисъл разказ. Не се изненадвайте от KDPV, тази снимка за мен беше свързана както с изкуствения интелект, така и с основния фактор.
Тази статия съдържа материали - предимно на руски - за основно изследване на изкуствените невронни мрежи.
Изкуствена невронна мрежа или ANN - математически модел, както и неговото софтуерно или хардуерно изпълнение, изградено на принципа на организация и функциониране на биологични невронни мрежи - мрежи нервни клеткижив организъм. Науката за невронните мрежи съществува от доста дълго време, но именно във връзка с най-новите постиженияС научно-техническия прогрес тази област започва да набира популярност.
Книги
Да започнем селекцията с класически начинучене - с помощта на книги. Избрахме книги на руски език с голям брой примери:
- Ф. Васерман, Неврокомпютърна технология: Теория и практика. 1992 г
Книгата излага в публично достъпна форма основите на изграждането на неврокомпютри. Описани са структурата на невронните мрежи и различни алгоритми за тяхното конфигуриране. Отделни глави са посветени на внедряването на невронни мрежи. - С. Хайкин, Невронни мрежи: Пълен курс. 2006 г
Тук се обсъждат основните парадигми на изкуствените невронни мрежи. Представеният материал съдържа строга математическа обосновка за всички парадигми на невронни мрежи, илюстриран е с примери, описания на компютърни експерименти и съдържа много практически проблеми, както и обширна библиография.
Д. Форсайт, Компютърно зрение. Модерен подход. 2004 г
Компютърното зрение е една от най-популярните области на този етап от развитието на глобалните цифрови компютърни технологии. Необходим е в производството, управлението на роботи, автоматизацията на процесите, медицинските и военните приложения, сателитното наблюдение и приложенията за персонални компютри като извличане на цифрови изображения.
Видео
Няма нищо по-достъпно и разбираемо от визуалното обучение с помощта на видео:
- За да разберете какво е машинно обучение като цяло, вижте тук тези две лекцииот Yandex ShaD.
- Въведениев основните принципи на проектиране на невронни мрежи - чудесно за продължаване на въведението ви в невронните мрежи.
- Лекционен курсна тема „Компютърно зрение” от Московския държавен университет по изчислителна техника. Компютърното зрение е теорията и технологията за създаване на изкуствени системи, които откриват и класифицират обекти в изображения и видеоклипове. Тези лекции могат да се считат за въведение в тази интересна и сложна наука.
Образователни ресурси и полезни връзки
- Портал за изкуствен интелект.
- Лаборатория “Аз съм интелект”.
- Невронни мрежи в Matlab.
- Невронни мрежи в Python (английски):
- Класифициране на текст с помощта на ;
- прост .
- Невронна мрежа на.
Поредица от наши публикации по темата
Преди това сме публикували курс #neuralnetwork@tprogerна невронни мрежи. В този списък публикациите са подредени по ред на изучаване за ваше удобство.

