V tem članku bom govoril o kako najti povprečje standardni odklon . To gradivo je izredno pomembno za popolno razumevanje matematike, zato bi moral mentor matematike posvetiti ločeno lekcijo ali celo več, da bi jo preučili. V tem članku boste našli povezavo do podrobne in razumljive video vadnice, ki pojasnjuje, kaj je standardni odklon in kako ga najti.
Standardni odklon omogoča ovrednotenje širjenja vrednosti, dobljenih kot rezultat merjenja določenega parametra. Označeno s simbolom (grška črka "sigma").
Formula za izračun je precej preprosta. Če želite najti standardni odklon, morate vzeti kvadratni koren variance. Zdaj se morate vprašati: "Kaj je varianca?"
Kaj je varianca
Definicija variance gre takole. Disperzija je aritmetična sredina kvadratnih odstopanj vrednosti od povprečja.
Če želite ugotoviti varianco, zaporedoma izvedite naslednje izračune:
- Določite povprečje (preprosto aritmetično povprečje niza vrednosti).
- Nato od vsake vrednosti odštejte povprečje in kvadrirajte dobljeno razliko (dobite kvadrat razlike).
- Naslednji korak je izračun aritmetične sredine dobljenih kvadratov razlik (zakaj točno kvadratov lahko izveste spodaj).
Poglejmo si primer. Recimo, da se vi in vaši prijatelji odločite izmeriti višino svojih psov (v milimetrih). Kot rezultat meritev ste prejeli naslednje mere višine (v vihru): 600 mm, 470 mm, 170 mm, 430 mm in 300 mm.
Izračunajmo povprečje, varianco in standardni odklon.
Najprej poiščemo povprečno vrednost. Kot že veste, morate za to sešteti vse izmerjene vrednosti in jih deliti s številom meritev. Napredek izračuna:
Povprečna mm.
Torej je povprečje (aritmetična sredina) 394 mm.
Zdaj moramo določiti odstopanje višine posameznega psa od povprečja:

končno, za izračun variance, kvadriramo vsako od dobljenih razlik in nato poiščemo aritmetično sredino dobljenih rezultatov:
Razpršenost mm 2 .
Tako je disperzija 21704 mm 2.
Kako najti standardno odstopanje
Torej, kako lahko zdaj izračunamo standardni odklon, če poznamo varianco? Kot se spomnimo, iz tega vzemite kvadratni koren. To pomeni, da je standardni odklon enak:
Mm (zaokroženo na najbližje celo število v mm).
S to metodo smo ugotovili, da so nekateri psi (na primer rotvajlerji) zelo veliki psi. So pa tudi zelo majhni psi (na primer jazbečarji, a jim tega ne smeš povedati).
Najbolj zanimivo je, da standardna deviacija nosi s seboj koristne informacije. Sedaj lahko pokažemo, kateri od dobljenih rezultatov merjenja višine so znotraj intervala, ki ga dobimo, če narišemo standardni odklon od povprečja (na obe strani).
To pomeni, da s standardnim odklonom dobimo "standardno" metodo, ki nam omogoča, da ugotovimo, katera od vrednosti je normalna (statistično povprečje) in katera je izjemno velika ali, nasprotno, majhna.
Kaj je standardni odklon
Ampak ... vse bo malo drugače, če analiziramo vzorec podatke. V našem primeru smo upoštevali splošna populacija. Se pravi, naših 5 psov so bili edini psi na svetu, ki so nas zanimali.
Če pa so podatki vzorec (vrednosti, izbrane iz velike populacije), je treba izračune narediti drugače.
Če obstajajo vrednosti, potem:
Vsi ostali izračuni se izvajajo podobno, vključno z določitvijo povprečja.
Na primer, če je naših pet psov le vzorec populacije psov (vseh psov na planetu), moramo deliti z 4, ne 5, namreč:
Varianca vzorca =  mm 2.
mm 2.
V tem primeru je standardni odklon za vzorec enak  mm (zaokroženo na najbližje celo število).
mm (zaokroženo na najbližje celo število).
Lahko rečemo, da smo naredili nekaj "popravka" v primeru, ko so naše vrednosti le majhen vzorec.
Opomba. Zakaj točno kvadratne razlike?
Toda zakaj pri izračunu variance vzamemo točno kvadrat razlike? Recimo, da ste pri merjenju nekega parametra prejeli naslednji niz vrednosti: 4; 4; -4; -4. Če preprosto seštejemo absolutna odstopanja od povprečja (razlike)... se negativne vrednosti izničijo s pozitivnimi:
 .
.
Izkazalo se je, da je ta možnost neuporabna. Potem je morda vredno poskusiti absolutne vrednosti odstopanj (to je module teh vrednosti)?
Na prvi pogled se izkaže dobro (dobljena vrednost, mimogrede, se imenuje povprečno absolutno odstopanje), vendar ne v vseh primerih. Poskusimo drug primer. Rezultat meritve naj bo naslednji niz vrednosti: 7; 1; -6; -2. Potem je povprečno absolutno odstopanje:
Vau! Spet smo dobili rezultat 4, čeprav imajo razlike precej večji razpon.
Zdaj pa poglejmo, kaj se zgodi, če kvadriramo razlike (in nato vzamemo kvadratni koren njihove vsote).
Za prvi primer bo to:
 .
.
Za drugi primer bo to:
Zdaj pa je čisto druga zadeva! Večja ko je razpršenost razlik, večja je standardna deviacija ... to je tisto, kar smo ciljali.
Pravzaprav v ta metoda Uporablja se ista ideja kot pri izračunu razdalje med točkami, le da se uporablja na drugačen način.
In z matematičnega vidika je uporaba kvadratov in kvadratni koreni zagotavlja več koristi, kot bi jih lahko dobili od absolutnih vrednosti odstopanj, zaradi česar je standardna deviacija uporabna za druge matematične probleme.
Sergey Valerievich vam je povedal, kako najti standardno odstopanje
Standardni odklon je eden tistih statističnih izrazov v podjetniškem svetu, ki daje verodostojnost ljudem, ki ga uspejo dobro izpeljati v pogovoru ali predstavitvi, hkrati pa pušča nejasno zmedo za tiste, ki ne vedo, kaj to je, a jim je preveč nerodno. vprašaj. Pravzaprav večina menedžerjev ne razume koncepta standardne deviacije in če ste eden izmed njih, je čas, da prenehate živeti v laži. V današnjem članku vam bom povedal, kako vam lahko ta premalo cenjena statistična mera pomaga bolje razumeti podatke, s katerimi delate.
Kaj meri standardni odklon?
Predstavljajte si, da ste lastnik dveh trgovin. Da bi se izognili izgubam, je pomembno imeti jasen nadzor nad stanjem zalog. Da bi ugotovili, kateri upravitelj bolje upravlja zaloge, se odločite analizirati zadnjih šest tednov zalog. Povprečni tedenski strošek zaloge za obe trgovini je približno enak in znaša približno 32 konvencionalnih enot. Na prvi pogled povprečni odtok kaže, da oba menedžerja delujeta podobno.

Toda če si podrobneje ogledate dejavnosti druge trgovine, se boste prepričali, da je povprečna vrednost sicer pravilna, vendar je variabilnost zaloge zelo visoka (od 10 do 58 USD). Tako lahko sklepamo, da povprečje podatkov ne ovrednoti vedno pravilno. Tukaj nastopi standardni odklon.
Standardni odklon kaže, kako so vrednosti porazdeljene glede na povprečje v našem . Z drugimi besedami, razumete lahko, kako velik je razpon odtoka iz tedna v teden.
V našem primeru smo uporabili Excelovo funkcijo STDEV za izračun standardnega odklona skupaj s srednjo vrednostjo.

Pri prvem vodji je bila standardna deviacija 2. To nam pove, da vsaka vrednost v vzorcu v povprečju za 2 odstopa od povprečja. Je dober? Poglejmo vprašanje z drugega zornega kota – standardni odklon 0 nam pove, da je vsaka vrednost v vzorcu enaka svojemu povprečju (v našem primeru 32,2). Tako se standardna deviacija 2 ne razlikuje veliko od 0, kar pomeni, da je večina vrednosti blizu povprečja. Bližje ko je standardni odklon 0, bolj zanesljivo je povprečje. Poleg tega standardni odklon blizu 0 kaže na majhno variabilnost podatkov. To pomeni, da vrednost odtoka s standardnim odklonom 2 kaže na neverjetno doslednost prvega upravitelja.
V primeru druge trgovine je bil standardni odklon 18,9. Se pravi, strošek odtoka v povprečju iz tedna v teden odstopa za 18,9 od povprečne vrednosti. Noro namaz! Bolj kot je standardni odklon od 0, manj natančno je povprečje. V našem primeru številka 18,9 nakazuje, da povprečni vrednosti (32,8 USD na teden) preprosto ni mogoče zaupati. Pove nam tudi, da je tedenski odtok zelo spremenljiv.
To je na kratko koncept standardne deviacije. Čeprav ne omogoča vpogleda v druge pomembne statistične meritve (Mode, Mediana ...), ima standardna deviacija dejansko ključno vlogo pri večini statističnih izračunov. Razumevanje načel standardnega odklona bo osvetlilo številne vaše poslovne procese.
Kako izračunati standardno odstopanje?
Zdaj vemo, kaj pravi standardna deviacijska številka. Ugotovimo, kako se izračuna.
Oglejmo si nabor podatkov od 10 do 70 v korakih po 10. Kot lahko vidite, sem zanje že izračunal vrednost standardnega odklona s funkcijo STANDARDEV v celici H2 (oranžno).

Spodaj so koraki, po katerih Excel doseže 21.6.
Upoštevajte, da so vsi izračuni vizualizirani za boljše razumevanje. Pravzaprav se v Excelu izračun zgodi takoj, vsi koraki pa ostanejo v zakulisju.
Najprej Excel najde vzorčno povprečje. V našem primeru se je izkazalo povprečje 40, ki se v naslednjem koraku odšteje od vsake vzorčne vrednosti. Vsaka dobljena razlika se kvadrira in sešteje. Dobili smo vsoto, ki je enaka 2800, ki jo je treba deliti s številom vzorčnih elementov minus 1. Ker imamo 7 elementov, se izkaže, da moramo 2800 deliti s 6. Iz dobljenega rezultata najdemo kvadratni koren, to številka bo standardna deviacija.

Za tiste, ki jim načelo izračuna standardnega odklona z vizualizacijo ni povsem jasno, podajam matematično razlago iskanja te vrednosti.

Funkcije za izračun standardnega odklona v Excelu
Excel ima več vrst formul standardnega odklona. Vse kar morate storiti je, da vnesete =STDEV in videli boste sami.

Omeniti velja, da funkciji STDEV.V in STDEV.G (prva in druga funkcija na seznamu) podvajata funkciji STDEV oziroma STDEV (peta oziroma šesta funkcija na seznamu), ki sta bili obdržani zaradi združljivosti s prejšnjimi različice Excela.
Na splošno razlika v končnicah funkcij .B in .G kaže načelo izračuna standardnega odklona vzorca ali populacije. Razliko med tema dvema nizoma sem razložil že v prejšnjem.
Značilnost funkcij STANDARDEVAL in STANDARDEVAL (tretja in četrta funkcija na seznamu) je, da se pri izračunu standardnega odklona matrike logično in besedilne vrednosti. Besedilne in prave logične vrednosti so 1, lažne logične vrednosti pa 0. Ne morem si predstavljati situacije, v kateri bi potreboval ti dve funkciji, zato menim, da ju je mogoče prezreti.
$X$. Za začetek se spomnimo naslednje definicije:
Definicija 1
Prebivalstvo-- niz naključno izbranih predmetov dane vrste, nad katerimi se izvajajo opazovanja, da bi dobili specifične vrednosti naključne spremenljivke, ki se izvajajo pod stalnimi pogoji pri preučevanju ene naključne spremenljivke dane vrste.
Definicija 2
Splošno odstopanje-- aritmetična sredina kvadratnih odstopanj vrednosti različice populacije od njihove srednje vrednosti.
Naj imajo vrednosti možnosti $x_1,\ x_2,\dots ,x_k$ frekvence $n_1,\ n_2,\dots ,n_k$. Nato se splošna varianca izračuna po formuli:
Razmislimo poseben primer. Naj bodo vse možnosti $x_1,\ x_2,\dots ,x_k$ različne. V tem primeru $n_1,\ n_2,\dots ,n_k=1$. Ugotovimo, da se v tem primeru splošna varianca izračuna po formuli:
Ta koncept je povezan tudi s konceptom splošnega standardnega odklona.
Definicija 3
Splošno standardno odstopanje
\[(\sigma )_g=\sqrt(D_g)\]
Varianca vzorca
Naj nam bo dana vzorčna populacija glede na naključno spremenljivko $X$. Za začetek se spomnimo naslednje definicije:
Definicija 4
Vzorčna populacija-- del izbranih objektov iz splošne populacije.
Definicija 5
Varianca vzorca--povprečno aritmetične vrednosti možnost vzorčenja.
Naj imajo vrednosti možnosti $x_1,\ x_2,\dots ,x_k$ frekvence $n_1,\ n_2,\dots ,n_k$. Nato se vzorčna varianca izračuna po formuli:
Razmislimo o posebnem primeru. Naj bodo vse možnosti $x_1,\ x_2,\dots ,x_k$ različne. V tem primeru $n_1,\ n_2,\dots ,n_k=1$. Ugotovimo, da se vzorčna varianca v tem primeru izračuna po formuli:
S tem konceptom je povezan tudi koncept standardne deviacije vzorca.
Opredelitev 6
Standardni odklon vzorca-- kvadratni koren splošne variance:
\[(\sigma )_v=\sqrt(D_v)\]
Popravljena varianca
Da bi našli popravljeno varianco $S^2$, je treba vzorčno varianco pomnožiti z ulomkom $\frac(n)(n-1)$, tj.
Ta koncept je povezan tudi s konceptom popravljenega standardnega odklona, ki ga najdemo s formulo:
V primeru, ko vrednosti variant niso diskretne, ampak predstavljajo intervale, se v formulah za izračun splošne ali vzorčne variance vrednost $x_i$ vzame kot vrednost sredine intervala do kateri $x_i.$ pripada.
Primer težave za iskanje variance in standardnega odklona
Primer 1
Vzorčna populacija je opredeljena z naslednjo distribucijsko tabelo:
Slika 1.
Poiščimo zanj vzorčno varianco, vzorčni standardni odklon, popravljeno varianco in popravljeni standardni odklon.
Za rešitev te težave najprej naredimo tabelo za izračun:
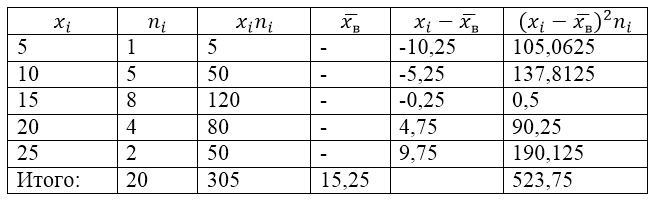
Slika 2.
Vrednost $\overline(x_в)$ (vzorčno povprečje) v tabeli najdemo po formuli:
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15,25\]
Poiščimo vzorčno varianco s formulo:
Standardni odklon vzorca:
\[(\sigma )_v=\sqrt(D_v)\približno 5,12\]
Popravljeno odstopanje:
\[(S^2=\frac(n)(n-1)D)_v=\frac(20)(19)\cdot 26,1875\približno 27,57\]
Popravljeno standardno odstopanje.
Kvadratni koren variance se imenuje standardni odklon od povprečja, ki se izračuna na naslednji način:
Osnovna algebraična transformacija formule standardnega odklona jo pripelje do naslednje oblike:
Ta formula se v praksi izračunov pogosto izkaže za bolj priročno.
Standardni odklon, tako kot povprečni linearni odklon, kaže, koliko v povprečju posamezne vrednosti lastnosti odstopajo od njihove povprečne vrednosti. Standardni odklon je vedno večji od srednjega linearnega odklona. Med njimi obstaja naslednje razmerje:
Če poznate to razmerje, lahko uporabite znane kazalnike za določitev neznanega, na primer, vendar (JAZ izračunajte a in obratno. Standardni odklon meri absolutno velikost variabilnosti značilnosti in je izražen v enakih merskih enotah kot vrednosti značilnosti (rublji, tone, leta itd.). Je absolutno merilo variacije.
Za alternativni znaki, na primer prisotnost ali odsotnost višja izobrazba, formule zavarovanja, disperzije in standardnega odklona so naslednje:
Pokažimo izračun standardnega odklona po podatkih diskretne serije, ki označuje porazdelitev študentov ene od univerzitetnih fakultet po starosti (tabela 6.2).
Tabela 6.2.

Rezultati pomožnih izračunov so podani v stolpcih 2-5 tabele. 6.2.
Povprečna starost študenta, let, je določena s formulo utežene aritmetične sredine (stolpec 2):
![]()
Kvadrati odstopanj posamezne starosti dijaka od povprečja so v stolpcih 3-4, zmnožki kvadratov odstopanj in pripadajočih frekvenc pa v stolpcu 5.
Varianco starosti učencev, let, poiščemo s formulo (6.2):
![]()
Potem je o = l/3,43 1,85 *oda, tj. Vsaka posamezna vrednost starosti študenta odstopa od povprečja za 1,85 leta.
Koeficient variacije
Na svoj način absolutna vrednost standardni odklon ni odvisen le od stopnje variacije značilnosti, temveč tudi od absolutnih ravni različic in povprečja. Zato je nemogoče neposredno primerjati standardne deviacije variacijskih serij z različnimi povprečnimi ravnmi. Da bi lahko naredili takšno primerjavo, morate najti delež povprečnega odstopanja (linearnega ali kvadratnega) v aritmetičnem povprečju, izraženem v odstotkih, tj. izračunati relativni indikatorji variacije.
Linearni koeficient variacije izračunano po formuli
Koeficient variacije določeno z naslednjo formulo:
V koeficientih variacije ni odpravljena le neprimerljivost, povezana z različnimi merskimi enotami preučevane značilnosti, temveč tudi neprimerljivost, ki nastane zaradi razlik v vrednosti aritmetičnih sredin. Poleg tega indikatorji variacije označujejo homogenost populacije. Populacija se šteje za homogeno, če koeficient variacije ne presega 33 %.
Glede na tabelo. 6.2 in zgoraj pridobljenih rezultatov izračuna določimo koeficient variacije, %, po formuli (6.3):
![]()
Če koeficient variacije presega 33 %, potem to kaže na heterogenost proučevane populacije. Dobljena vrednost v našem primeru kaže, da je populacija študentov po starosti homogena po sestavi. torej pomembna funkcija generalizirajoči indikatorji variacije - ocena zanesljivosti povprečij. Manj c1, a2 in V, bolj homogen je nastali niz pojavov in bolj zanesljivo je nastalo povprečje. V skladu s "pravilom treh sigm", ki ga upošteva matematična statistika, se v serijah z normalno porazdelitvijo ali nizih, ki so jim blizu, odstopanja od aritmetične sredine, ki ne presegajo ±3, pojavijo v 997 primerih od 1000. Tako vemo, X in a, lahko dobite splošno začetno predstavo o vrsti variacij. Če je npr.povprečje plača zaposlenega v podjetju 25.000 rubljev, a je enako 100 rubljev, potem je z verjetnostjo, ki je blizu gotovosti, mogoče trditi, da plače zaposlenih v podjetju nihajo v območju (25.000 ± ± 3 x 100), tj. od 24.700 do 25.300 rubljev.
X i - naključne (trenutne) spremenljivke;
X̅– povprečna vrednost naključnih spremenljivk za vzorec se izračuna po formuli:

Torej, varianca je povprečni kvadrat odstopanj . To pomeni, da se povprečna vrednost najprej izračuna, nato pa vzame razlika med vsako izvirno in povprečno vrednostjo je na kvadrat , sešteje in nato deli s številom vrednosti v populaciji.
Razlika med posamezno vrednostjo in povprečjem odraža mero odstopanja. Kvadrira se tako, da postanejo vsa odstopanja izključno pozitivna števila in da se izognemo medsebojnemu uničenju pozitivnih in negativnih odstopanj pri njihovem seštevanju. Nato glede na kvadrat odstopanja preprosto izračunamo aritmetično sredino.
Odgovor na čarobno besedo »razpršenost« se skriva v teh treh besedah: povprečje - kvadrat - odstopanja.
Povprečje standardni odklon(RMS)
Če vzamemo kvadratni koren variance, dobimo tako imenovani " standardni odklon". Obstajajo imena "standardni odklon" ali "sigma" (iz imena grške črke σ .). Formula za standardni odklon je:
Torej, disperzija je sigma na kvadrat ali standardni odklon na kvadrat.
Standardni odklon seveda označuje tudi mero razpršenosti podatkov, vendar ga je zdaj (za razliko od razpršenosti) mogoče primerjati z izvirnimi podatki, saj imajo enake merske enote (to je jasno iz formule za izračun). Razpon variacije je razlika med skrajnimi vrednostmi. Standardni odklon kot merilo negotovosti je prav tako vključen v številne statistične izračune. Z njegovo pomočjo se določi stopnja točnosti različnih ocen in napovedi. Če je variacija zelo velika, bo velik tudi standardni odklon, zato bo napoved netočna, kar se bo izrazilo na primer v zelo širokih intervalih zaupanja.
Zato v metodah statistične obdelave podatkov pri ocenjevanju nepremičnin se glede na zahtevano natančnost naloge uporablja pravilo dveh ali treh sigm.
Za primerjavo pravila dveh sigm in pravil treh sigm uporabimo Laplaceovo formulo:
![]() Ž - Ž ,
Ž - Ž ,
kjer je Ф(x) Laplaceova funkcija;
Najmanjša vrednost
β = največja vrednost
s = sigma vrednost (standardni odklon)
a = povprečje
V tem primeru se uporablja posebna oblika Laplaceove formule, ko sta meji α in β vrednosti naključne spremenljivke X enako oddaljeni od središča porazdelitve a = M(X) za določeno vrednost d: a = a-d, b = a+d.  oz oz   (1) Formula (1) določa verjetnost danega odstopanja d naključne spremenljivke X z normalnim zakonom porazdelitve od njenega matematičnega pričakovanja M(X) = a. Če v formuli (1) zaporedno vzamemo d = 2s in d = 3s, dobimo: (2), (3). (1) Formula (1) določa verjetnost danega odstopanja d naključne spremenljivke X z normalnim zakonom porazdelitve od njenega matematičnega pričakovanja M(X) = a. Če v formuli (1) zaporedno vzamemo d = 2s in d = 3s, dobimo: (2), (3). |
Pravilo dveh sigm
Lahko je skoraj zanesljivo (z verjetnostjo zaupanja 0,954), da vse vrednosti naključne spremenljivke X z normalnim porazdelitvenim zakonom odstopajo od njenega matematičnega pričakovanja M(X) = a za znesek, ki ni večji od 2s (dva standardna odklona ). Verjetnost zaupanja (Pd) je verjetnost dogodkov, ki so običajno sprejeti kot zanesljivi (njihova verjetnost je blizu 1).
Geometrično ponazorimo pravilo dveh sigm. Na sl. Slika 6 prikazuje Gaussovo krivuljo z distribucijskim središčem a. Območje, omejeno s celotno krivuljo in osjo Ox, je 1 (100 %), območje pa ukrivljen trapez med abscisama a–2s in a+2s je po pravilu dveh sigm enaka 0,954 (95,4 % celotne površine). Površina zasenčenih območij je 1-0,954 = 0,046 (»5% celotne površine). Ta območja se imenujejo kritična regija naključne spremenljivke. Vrednosti naključne spremenljivke, ki spadajo v kritično območje, so malo verjetne in so v praksi običajno sprejete kot nemogoče.

Verjetnost pogojno nemogočih vrednosti se imenuje stopnja pomembnosti naključne spremenljivke. Stopnja pomembnosti je povezana z verjetnostjo zaupanja s formulo:
kjer je q stopnja pomembnosti, izražena v odstotkih.
Pravilo treh sigm
Pri reševanju vprašanj, ki zahtevajo večjo zanesljivost, ko je verjetnost zaupanja (Pd) enaka 0,997 (natančneje 0,9973), se namesto pravila dveh sigm po formuli (3) uporablja pravilo tri sigme
Po navedbah pravilo treh sigm z verjetnostjo zaupanja 0,9973 bo kritično območje območje vrednosti atributov zunaj intervala (a-3s, a+3s). Stopnja pomembnosti je 0,27 %.
Z drugimi besedami, verjetnost, da bo absolutna vrednost odstopanja presegla trikratnik standardnega odklona, je zelo majhna, in sicer 0,0027 = 1-0,9973. To pomeni, da se bo to zgodilo le v 0,27 % primerov. Takšni dogodki, ki temeljijo na načelu nemogoče malo verjetnih dogodkov, se lahko štejejo za praktično nemogoče. Tisti. vzorčenje je zelo natančno.
To je bistvo pravila treh sigm:
Če je naključna spremenljivka porazdeljena normalno, potem absolutna vrednost njenega odstopanja od matematičnega pričakovanja ne presega trikratne standardne deviacije (MSD).
V praksi se pravilo treh sigm uporablja na naslednji način: če porazdelitev preučevane naključne spremenljivke ni znana, vendar je pogoj, določen v zgornjem pravilu, izpolnjen, obstaja razlog za domnevo, da je preučevana spremenljivka normalno porazdeljena ; sicer ni normalno razporejen.
Stopnja pomembnosti je vzeta glede na dovoljeno stopnjo tveganja in nalogo. Za vrednotenje nepremičnin se običajno uporabi manj natančen vzorec po pravilu dveh sigm.

