Modri matematiki in statistiki so se domislili bolj zanesljivega kazalnika, čeprav za nekoliko drugačen namen - srednji linearni odklon. Ta indikator označuje mero širjenja vrednosti nabora podatkov okoli njihove povprečne vrednosti.
Da bi prikazali mero razpršenosti podatkov, morate najprej določiti, glede na kaj bo ta razpršenost obravnavana - običajno je to povprečna vrednost. Nato morate izračunati, kako daleč so vrednosti analiziranega niza podatkov od povprečja. Jasno je, da vsaka vrednost ustreza določenemu odstopanju, vendar nas zanima tudi splošna ocena, ki zajema celotno populacijo. Zato se povprečno odstopanje izračuna po formuli običajne aritmetične sredine. ampak! A da bi izračunali povprečje odstopanj, jih je treba najprej sešteti. In če seštejemo pozitivna in negativna števila, se bodo med seboj izničila in njihova vsota se bo nagibala k ničli. Da bi se temu izognili, se vsa odstopanja upoštevajo modulo, to pomeni, da vsa negativna števila postanejo pozitivna. Zdaj bo povprečno odstopanje pokazalo posplošeno mero širjenja vrednosti. Posledično se povprečno linearno odstopanje izračuna po formuli:
a je povprečno linearno odstopanje,
x- analizirani kazalnik, s pomišljajem na vrhu - povprečna vrednost kazalnika,
n je število vrednosti v analiziranem nizu podatkov,
operater seštevanja, upam, ne bo nikogar prestrašil.
Povprečno linearno odstopanje, izračunano z navedeno formulo, odraža povprečno absolutno odstopanje od povprečne vrednosti za to populacijo.

Rdeča črta na sliki je povprečna vrednost. Odstopanja vsakega opazovanja od povprečja so označena z majhnimi puščicami. Vzamejo se po modulu in seštejejo. Nato se vse deli s številom vrednosti.
Za popolnost je treba navesti še en primer. Recimo, da obstaja podjetje, ki proizvaja potaknjence za lopate. Vsak potaknjenec mora biti dolg 1,5 metra, še pomembneje pa je, da morajo biti vsi enaki oz. vsaj, plus ali minus 5 cm, vendar bodo malomarni delavci odžagali 1,2 m ali 1,8 m, poletni prebivalci so nezadovoljni. Direktor podjetja se je odločil za statistično analizo dolžine posekov. Izbral sem 10 kosov in izmeril njihovo dolžino, našel povprečje in izračunal povprečno linearno odstopanje. Povprečje se je izkazalo za ravno pravšnje - 1,5 m, vendar se je povprečno linearno odstopanje izkazalo za 0,16 m. Tako se izkaže, da je vsak rez daljši ali krajši, kot je potrebno, v povprečju za 16 cm. Obstaja nekaj za pogovor. z delavci. Pravzaprav še nisem videl dejanske uporabe tega indikatorja, zato sem si sam izmislil primer. Vendar pa v statistiki obstaja tak indikator.
Razpršenost
Tako kot povprečni linearni odklon tudi varianca odraža obseg, v katerem se podatki širijo okoli povprečja.
Formula za izračun variance je videti takole:
 (za serije variacij (utežena varianca))
(za serije variacij (utežena varianca))
 (za nezdružene podatke (enostavna varianca))
(za nezdružene podatke (enostavna varianca))
Kje: σ 2 - disperzija, Xi– analiziramo indikator sq (feature value), – povprečno vrednost kazalnika, f i – število vrednosti v analiziranem nizu podatkov.
Varianca je srednji kvadrat odstopanj.
Najprej se izračuna povprečje, nato se razlika med vsako izhodiščno vrednostjo in povprečjem vzame, kvadrira, pomnoži s frekvenco ustrezne vrednosti značilnosti, doda in nato deli s številom vrednosti v populaciji.
Vendar pa v čista oblika, kot je aritmetična sredina ali indeks, se varianca ne uporablja. Je bolj pomožni in vmesni indikator, ki se uporablja za druge vrste statističnih analiz.
Poenostavljen način izračuna variance
![]()
standardni odklon
Za uporabo variance za analizo podatkov se iz nje vzame kvadratni koren. Izkazalo se je tako imenovano standardni odklon.

Mimogrede, standardni odklon se imenuje tudi sigma - iz grške črke, ki jo označuje.
Standardni odklon očitno označuje tudi merilo razpršenosti podatkov, vendar ga je zdaj (za razliko od razpršenosti) mogoče primerjati z izvirnimi podatki. Praviloma srednje kvadratni kazalniki v statistiki dajejo natančnejše rezultate kot linearni. Zato povprečno standardni odklon je natančnejša mera razpršenosti podatkov kot srednji linearni odklon.
$X$. Najprej se spomnimo naslednje definicije:
Definicija 1
Prebivalstvo-- niz naključno izbranih predmetov dane vrste, nad katerimi se izvajajo opazovanja, da bi dobili specifične vrednosti naključne spremenljivke, ki se izvajajo pod nespremenjenimi pogoji pri preučevanju ene naključne spremenljivke dane vrste.
Definicija 2
Splošno odstopanje-- aritmetična sredina kvadratnih odstopanj vrednosti različice splošne populacije od njihove srednje vrednosti.
Naj imajo vrednosti različice $x_1,\ x_2,\dots ,x_k$ frekvence $n_1,\ n_2,\dots ,n_k$. Nato se splošna varianca izračuna po formuli:
Razmislite poseben primer. Naj bodo vse različice $x_1,\ x_2,\dots ,x_k$ različne. V tem primeru $n_1,\ n_2,\dots ,n_k=1$. Dobimo, da se v tem primeru splošna varianca izračuna po formuli:
S tem konceptom je povezan tudi koncept splošnega standardnega odklona.
Definicija 3
Splošno standardno odstopanje
\[(\sigma )_r=\sqrt(D_r)\]
Varianca vzorca
Naj nam bo dana vzorčna množica glede na naključno spremenljivko $X$. Najprej se spomnimo naslednje definicije:
Definicija 4
Vzorčna populacija-- del izbranih objektov iz splošne populacije.
Definicija 5
Varianca vzorca-- aritmetična sredina vrednosti različice vzorčne populacije.
Naj imajo vrednosti različice $x_1,\ x_2,\dots ,x_k$ frekvence $n_1,\ n_2,\dots ,n_k$. Nato se vzorčna varianca izračuna po formuli:
Razmislimo o posebnem primeru. Naj bodo vse različice $x_1,\ x_2,\dots ,x_k$ različne. V tem primeru $n_1,\ n_2,\dots ,n_k=1$. Dobimo, da se v tem primeru vzorčna varianca izračuna po formuli:
S tem konceptom je povezan tudi koncept standardne deviacije vzorca.
Opredelitev 6
Standardni odklon vzorca-- kvadratni koren splošne variance:
\[(\sigma )_v=\sqrt(D_v)\]
Popravljena varianca
Da bi našli popravljeno varianco $S^2$, je treba vzorčno varianco pomnožiti z ulomkom $\frac(n)(n-1)$, tj.
Ta koncept je povezan tudi s konceptom popravljenega standardnega odklona, ki ga najdemo s formulo:
V primeru, ko vrednost variante ni diskretna, ampak so intervali, potem se v formulah za izračun generalnih ali vzorčnih varianc vrednost $x_i$ vzame kot vrednost sredine intervala, do katerega $ x_i.$ pripada
Primer problema za iskanje variance in standardnega odklona
Primer 1
Vzorčna populacija je podana z naslednjo porazdelitveno tabelo:
Slika 1.
Poiščite zanj vzorčno varianco, vzorčni standardni odklon, popravljeno varianco in popravljeni standardni odklon.
Za rešitev tega problema bomo najprej naredili tabelo za izračun:
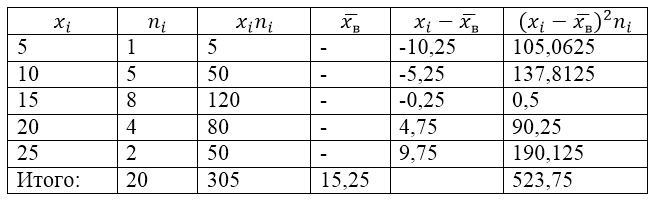
Slika 2.
Vrednost $\overline(x_v)$ (vzorčno povprečje) v tabeli najdemo po formuli:
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15,25\]
Poiščite vzorčno varianco z uporabo formule:
Standardni odklon vzorca:
\[(\sigma )_v=\sqrt(D_v)\približno 5,12\]
Popravljeno odstopanje:
\[(S^2=\frac(n)(n-1)D)_v=\frac(20)(19)\cdot 26,1875\približno 27,57\]
Popravljeno standardno odstopanje.
standardni odklon(sinonimi: standardni odklon, standardni odklon, standardni odklon; povezani izrazi: standardni odklon, standardni namaz) - v teoriji verjetnosti in statistiki najpogostejši indikator razpršenosti vrednosti naključne spremenljivke glede na njeno matematično pričakovanje. Pri omejenih nizih vzorcev vrednosti se namesto matematičnega pričakovanja uporablja aritmetična sredina množice vzorcev.
Enciklopedični YouTube
-
1 / 5
Standardni odklon se meri v merskih enotah same naključne spremenljivke in se uporablja pri izračunu standardne napake aritmetične sredine, pri konstruiranju intervalov zaupanja, pri statističnem preverjanju hipotez, pri merjenju linearne povezave med naključnimi spremenljivkami. Definirana je kot kvadratni koren variance naključne spremenljivke.
Standardni odklon:
s = n n − 1 σ 2 = 1 n − 1 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s=(\sqrt ((\frac (n)(n-1))\sigma ^(2)))=(\sqrt ((\frac (1)(n-1))\sum _( i=1)^(n)\levo(x_(i)-(\bar (x))\desno)^(2)));)- Opomba: Zelo pogosto prihaja do neskladij v imenih RMS (standardni odklon) in SRT (standardni odklon) z njihovimi formulami. Na primer, v modulu numPy programskega jezika Python je funkcija std() opisana kot "standardni odklon", medtem ko formula odraža standardni odklon (deljeno s korenom vzorca). V Excelu je funkcija STDEV() drugačna (deljenje s kvadratnim korenom iz n-1).
Standardni odklon(ocena standardnega odklona naključne spremenljivke x glede na njegovo matematično pričakovanje, ki temelji na nepristranski oceni njegove variance) s (\displaystyle s):
σ = 1 n ∑ i = 1 n (x i − x ¯) 2 . (\displaystyle \sigma =(\sqrt ((\frac (1)(n))\sum _(i=1)^(n)\levo(x_(i)-(\bar (x))\desno) ^(2))).)Kje σ 2 (\displaystyle \sigma ^(2))- disperzija ; x i (\displaystyle x_(i)) - jaz-th vzorčni element; n (\displaystyle n)- Velikost vzorca; - aritmetična sredina vzorca:
x ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + … + x n) . (\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\pike +x_(n)).)Opozoriti je treba, da sta obe oceni pristranski. V splošnem primeru je nemogoče sestaviti nepristransko oceno. Vendar je ocena, ki temelji na nepristranski oceni variance, dosledna.
V skladu z GOST R 8.736-2011 se standardni odklon izračuna po drugi formuli tega razdelka. Preverite svoje rezultate.
pravilo treh sigm
pravilo treh sigm (3 σ (\displaystyle 3\sigma )) - skoraj vse vrednosti normalno porazdeljene naključne spremenljivke ležijo v intervalu (x ¯ − 3 σ ; x ¯ + 3 σ) (\displaystyle \left((\bar (x))-3\sigma ;(\bar (x))+3\sigma \desno)). Strožje - približno z verjetnostjo 0,9973 je vrednost normalno porazdeljene naključne spremenljivke v določenem intervalu (pod pogojem, da vrednost x ¯ (\displaystyle (\bar (x))) res in ni pridobljeno kot rezultat obdelave vzorca).
Če je prava vrednost x ¯ (\displaystyle (\bar (x))) neznano, potem morate uporabiti σ (\displaystyle \sigma ), A s. Tako se pravilo treh sigm spremeni v pravilo treh s .
Interpretacija vrednosti standardnega odklona
Večja vrednost standardnega odklona pomeni večji razpon vrednosti v predstavljenem nizu s povprečjem niza; manjša vrednost pomeni, da so vrednosti v nizu združene okoli povprečne vrednosti.
Na primer, imamo tri nize številk: (0, 0, 14, 14), (0, 6, 8, 14) in (6, 6, 8, 8). Vsi trije nizi imajo povprečne vrednosti 7 in standardne odklone 7, 5 oziroma 1. Zadnji niz ima majhen standardni odklon, ker so vrednosti v nizu združene okoli povprečja; prvi niz ima največ velik pomen standardni odklon - vrednosti v nizu močno odstopajo od srednje vrednosti.
V splošnem se lahko standardni odklon šteje za merilo negotovosti. Na primer, v fiziki se standardna deviacija uporablja za določitev napake niza zaporednih meritev neke količine. Ta vrednost je zelo pomembna za določanje verjetnosti preučevanega pojava v primerjavi z vrednostjo, ki jo predvideva teorija: če se srednja vrednost meritev zelo razlikuje od vrednosti, ki jih predvideva teorija (velik standardni odklon), potem dobljene vrednosti ali način njihovega pridobivanja je treba ponovno preveriti. se identificira s tveganjem portfelja.
Podnebje
Recimo, da obstajata dve mesti z enako povprečno najvišjo dnevno temperaturo, vendar se eno nahaja na obali, drugo pa na ravnini. Znano je, da imajo obalna mesta veliko različnih dnevnih najvišjih temperatur nižjih kot mesta v notranjosti. Zato bo standardni odklon najvišjih dnevnih temperatur za obalno mesto manjši kot za drugo mesto, kljub temu da imata enako povprečno vrednost te vrednosti, kar v praksi pomeni, da je verjetnost, da Najvišja temperatura zrak vsakega določenega dne v letu se bo bolj razlikoval od povprečne vrednosti, višje za mesto znotraj celine.
Šport
Recimo, da obstaja več nogometnih moštev, ki so razvrščena po nekem naboru parametrov, na primer po številu doseženih in prejetih golov, priložnosti za zadetek itd. Najverjetneje bo najboljša ekipa v tej skupini imela najboljše vrednosti za več možnosti. Manjši kot je standardni odklon ekipe za vsakega od predstavljenih parametrov, bolj predvidljiv je rezultat ekipe, takšne ekipe so uravnotežene. Na drugi strani pa ekipa z dobra vrednost standardni odklon je težko napovedati rezultat, kar je posledično razloženo z neravnovesjem, npr. močna obramba, vendar šibek napad.
Uporaba standardnega odklona parametrov ekipe omogoča do neke mere predvidevanje rezultata tekme med dvema ekipama, pri čemer se ocenijo moči in šibke strani ukazi, s tem pa tudi izbrani načini boja.
Opredeljena je kot posplošujoča značilnost velikosti variacije lastnosti v agregatu. Enak je kvadratnemu korenu povprečnega kvadrata odstopanj posameznih vrednosti lastnosti od aritmetične sredine, tj. koren in lahko najdete takole:
1. Za primarno vrstico:
2. Za variacijsko serijo:

Preoblikovanje formule standardnega odklona jo vodi v obliko, ki je primernejša za praktične izračune:
Povprečje standardni odklon določa, koliko v povprečju posamezne opcije odstopajo od svoje povprečne vrednosti, poleg tega pa je absolutna mera nihanja lastnosti in je izražena v enakih enotah kot opcije, zato je dobro interpretirana.
Primeri iskanja standardnega odklona: ,
Za alternativne lastnosti je formula za standardno odstopanje videti takole:

kjer je p delež enot v populaciji, ki imajo določeno lastnost;
q - delež enot, ki nimajo te lastnosti.
Koncept srednjega linearnega odstopanja
Povprečno linearno odstopanje definirana kot aritmetična sredina absolutne vrednosti odstopanja posameznih možnosti od .
1. Za primarno vrstico:

2. Za variacijsko serijo:

kjer je vsota n vsoto frekvenc variacijske serije.
Primer iskanja povprečnega linearnega odstopanja:
Prednost srednjega absolutnega odstopanja kot merila razpršenosti v območju variacije je očitna, saj ta mera temelji na upoštevanju vseh možna odstopanja. Toda ta indikator ima pomembne pomanjkljivosti. Samovoljno zavračanje algebrskih znakov odstopanj lahko privede do dejstva, da matematične lastnosti tega indikatorja še zdaleč niso osnovne. To močno oteži uporabo srednjega absolutnega odklona pri reševanju problemov, povezanih z verjetnostnimi izračuni.
Zato se povprečni linearni odklon kot merilo variacije lastnosti v statistični praksi redko uporablja, in sicer takrat, ko je seštevek kazalnikov brez upoštevanja predznakov ekonomsko smiseln. Z njegovo pomočjo se na primer analizira promet zunanje trgovine, sestava zaposlenih, ritem proizvodnje itd.
efektivna vrednost
Uporabljen RMS, na primer za izračun povprečne velikosti stranic n kvadratnih odsekov, povprečnih premerov debla, cevi itd. Razdeljen je na dve vrsti.
Srednji kvadratni koren je preprost. Če pri zamenjavi posameznih vrednosti funkcije z Povprečna vrednost je treba ohraniti konstantno vsoto kvadratov prvotnih vrednosti, potem bo povprečje kvadratno povprečje.
Je kvadratni koren količnika vsote kvadratov posameznih vrednosti lastnosti, deljenih z njihovim številom:
Srednja kvadratna utež se izračuna po formuli:

kjer je f znak teže.
Povprečna kubična
Uporabljeno povprečno kubično, na primer pri določanju povprečne dolžine stranice in kocke. Razdeljen je na dve vrsti.
Povprečna kubična preprosta:

Pri izračunu srednjih vrednosti in variance v seriji intervalne porazdelitve se prave vrednosti atributa nadomestijo z osrednjimi vrednostmi intervalov, ki se razlikujejo od povprečja aritmetične vrednosti vključeni v interval. To vodi do sistematične napake pri izračunu variance. V.F. Sheppard je to ugotovil napaka v izračunu variance, ki ga povzroči uporaba združenih podatkov, je 1/12 kvadrata vrednosti intervala, tako navzgor kot navzdol glede na velikost variance.
Sheppardov amandma je treba uporabiti, če je porazdelitev blizu normalne, se nanaša na značilnost z neprekinjeno naravo variacije, ki temelji na znatni količini začetnih podatkov (n> 500). Vendar pa je na podlagi dejstva, da se v številnih primerih obe napaki, ki delujeta v različnih smereh, kompenzirata, včasih mogoče zavrniti uvedbo sprememb.
Manjša ko sta varianca in standardni odklon, bolj homogena je populacija in bolj tipično bo povprečje.
V praksi statistike je pogosto treba primerjati variacije razna znamenja. Na primer, zelo zanimivo je primerjati razlike v starosti delavcev in njihovih kvalifikacijah, delovni dobi in velikosti delavcev. plače, stroški in dobiček, delovna doba in produktivnost dela itd. Za takšne primerjave so kazalniki absolutne variabilnosti lastnosti neprimerni: nemogoče je primerjati variabilnost delovnih izkušenj, izraženo v letih, z variabilnostjo plač, izraženo v rubljih.Za izvedbo tovrstnih primerjav, kot tudi primerjav nihanja istega atributa v več populacijah z različno aritmetično sredino, uporabljamo relativni indikator variation - koeficient variacije.
Strukturna povprečja
Za karakterizacijo osrednjega trenda v statističnih distribucijah je pogosto smiselno uporabiti skupaj z aritmetično sredino določeno vrednost atributa X, ki lahko zaradi določenih značilnosti svoje lokacije v nizu distribucije označuje njegovo raven.
To je še posebej pomembno, kadar imajo skrajne vrednosti funkcije v seriji distribucije mehke meje. Zaradi tega natančna definicija aritmetična sredina je praviloma nemogoča ali zelo težka. V takih primerih povprečna raven lahko določite tako, da na primer vzamete vrednost funkcije, ki se nahaja na sredini niza frekvenc ali ki se najpogosteje pojavlja v trenutnem nizu.
Takšne vrednosti so odvisne samo od narave frekvenc, to je od strukture porazdelitve. Značilne so glede na lokacijo v nizu frekvenc, zato se takšne vrednosti obravnavajo kot značilnosti distribucijskega centra in so zato opredeljene kot strukturna povprečja. Uporabljajo se za študij notranja struktura in struktura serije porazdelitve vrednosti atributov. Ti kazalniki vključujejo.
Najbolj popolna značilnost variacije je standardna deviacija, ki se imenuje standard (ali standardna deviacija). Standardni odklon() je enak kvadratnemu korenu srednjega kvadrata odstopanj posameznih vrednosti lastnosti od aritmetične sredine:
Standardni odklon je preprost:


Uteženi standardni odklon se uporablja za združene podatke:

Med srednjimi kvadratnimi in srednjimi linearnimi odstopanji v pogojih normalne porazdelitve velja razmerje: ~ 1,25.
Standardni odklon, ki je glavno absolutno merilo variacije, se uporablja pri določanju vrednosti ordinat krivulje normalne porazdelitve, pri izračunih, povezanih z organizacijo opazovanja vzorca in ugotavljanjem točnosti značilnosti vzorca, pa tudi pri ocenjevanje meja variacije lastnosti v homogeni populaciji.
Disperzija, njene vrste, standardna deviacija.
Varianca naključne spremenljivke- merilo širjenja dane naključne spremenljivke, to je njen odklon od matematičnega pričakovanja. V statistiki se pogosto uporablja oznaka oz. Kvadratni koren variance se imenuje standardni odklon, standardni odklon ali standardni razpon.
Skupna varianca (σ2) meri variacijo lastnosti v celotni populaciji pod vplivom vseh dejavnikov, ki so to variacijo povzročili. Hkrati je zahvaljujoč metodi združevanja mogoče izolirati in izmeriti variacijo zaradi značilnosti združevanja in variacijo, ki nastane pod vplivom neupoštevanih dejavnikov.
Medskupinska varianca (σ 2 m.gr) označuje sistematično variacijo, to je razlike v velikosti proučevane lastnosti, ki nastanejo pod vplivom lastnosti - dejavnika, na katerem temelji združevanje.
standardni odklon(sinonimi: standardni odklon, standardni odklon, standardni odklon; podobni izrazi: standardni odklon, standardni razpon) - v teoriji verjetnosti in statistiki najpogostejši indikator razpršenosti vrednosti naključne spremenljivke glede na njeno matematično pričakovanje. Pri omejenih nizih vzorcev vrednosti se namesto matematičnega pričakovanja uporablja aritmetična sredina množice vzorcev.
Standardni odklon se meri v enotah same naključne spremenljivke in se uporablja pri izračunu standardne napake aritmetične sredine, pri konstruiranju intervalov zaupanja, pri statističnem testiranju hipotez in pri merjenju linearne povezave med naključnimi spremenljivkami. Definirana je kot kvadratni koren variance naključne spremenljivke.
Standardni odklon:

Standardni odklon(ocena standardnega odklona naključne spremenljivke x glede na njegovo matematično pričakovanje, ki temelji na nepristranski oceni njegove variance):

kje je disperzija; — jaz-th vzorčni element; - Velikost vzorca; - aritmetična sredina vzorca:

Opozoriti je treba, da sta obe oceni pristranski. V splošnem primeru je nemogoče sestaviti nepristransko oceno. Vendar je ocena, ki temelji na nepristranski oceni variance, dosledna.
Bistvo, obseg in postopek določanja modusa in mediane.
Poleg potenčnih povprečij v statistiki se za relativno karakteristiko velikosti spremenljive lastnosti in notranje strukture porazdelitvenih nizov uporabljajo strukturna povprečja, ki jih predstavlja predvsem način in mediana.
Moda- To je najpogostejša različica serije. Moda se uporablja na primer pri določanju velikosti oblačil, čevljev, po katerih je med kupci največje povpraševanje. Način za diskretno serijo je različica z najvišjo frekvenco. Pri izračunu načina za niz intervalnih variacij morate najprej določiti modalni interval (po največja frekvenca), nato pa - vrednost modalne vrednosti atributa po formuli:

- - modna vrednost
- - spodnja meja modalnega intervala
- - vrednost intervala
- - modalna intervalna frekvenca
- - frekvenca intervala pred modalnim
- - frekvenca intervala, ki sledi modalu
Mediana - to je vrednost značilnosti, ki je podlaga za rangirano serijo in to serijo deli na dva enaka po številu dela.
Če želite določiti mediano v diskretnem nizu ob prisotnosti frekvenc, najprej izračunajte polovično vsoto frekvenc in nato določite, katera vrednost variante pade nanjo. (Če razvrščena vrstica vsebuje liho število funkcij, potem se mediana izračuna po formuli:
M e \u003d (n (število funkcij v agregatu) + 1) / 2,
pri sodem številu značilnosti bo mediana enaka povprečju dveh značilnosti v sredini vrstice).
Pri izračunu mediane za intervalno variacijsko serijo najprej določite medianski interval, znotraj katerega se mediana nahaja, nato pa vrednost mediane po formuli:

- je želena mediana
- je spodnja meja intervala, ki vsebuje mediano
- - vrednost intervala
- - vsota frekvenc ali števila članov serije
Vsota akumuliranih frekvenc intervalov pred mediano
- je frekvenca medianega intervala
Primer. Poiščite modus in mediano.
rešitev:
V tem primeru je modalni interval znotraj starostne skupine 25-30 let, saj ta interval predstavlja največjo frekvenco (1054).Izračunajmo vrednost načina:
To pomeni, da je modalna starost študentov 27 let.
Izračunajte mediano. Mediani interval je pri starostna skupina 25-30 let, saj znotraj tega intervala obstaja varianta, ki populacijo razdeli na dva enaka dela (Σf i /2 = 3462/2 = 1731). Nato v formulo nadomestimo potrebne numerične podatke in dobimo vrednost mediane:

To pomeni, da je polovica študentov mlajših od 27,4 leta, druga polovica pa starejših od 27,4 leta.
Poleg načina in mediane je mogoče uporabiti indikatorje, kot so kvartili, ki razdelijo razvrščeno serijo na 4 enake dele, decili- 10 delov in percentili - na 100 delov.
Pojem selektivnega opazovanja in njegov obseg.
Selektivno opazovanje velja pri izvajanju stalnega opazovanja fizično nemogoče zaradi velike količine podatkov oz ekonomsko nepraktično. Do fizične nezmožnosti pride na primer pri preučevanju potniških tokov, tržnih cen, družinski proračuni. Ekonomska neprimernost se pojavi pri ocenjevanju kakovosti blaga, povezanega z njihovim uničenjem, na primer pri degustaciji, testiranju opeke na trdnost itd.
Statistične enote, izbrane za opazovanje, sestavljajo vzorec ali vzorec in njihov celoten niz - generalno populacijo (GS). V tem primeru pomeni število enot v vzorcu n in v celotnem HS - n. Odnos n/n imenujemo relativna velikost ali delež vzorca.
Kakovost rezultatov vzorčenja je odvisna od reprezentativnosti vzorca, to je, kako reprezentativen je v HS. Za zagotovitev reprezentativnosti vzorca je treba upoštevati princip naključnega izbora enot, ki predpostavlja, da na vključitev enote HS v vzorec ne more vplivati noben drug dejavnik kot naključje.
obstaja 4 načini naključne izbire za vzorec:
- Pravzaprav naključno izbor ali "metoda loto", ko je dodeljena statistika zaporedne številke, prinesejo določene predmete (na primer sode), ki jih nato pomešajo v določeno posodo (na primer v vrečko) in naključno izberejo. V praksi se ta metoda izvaja z uporabo generatorja naključnih števil ali matematičnih tabel naključnih števil.
- Mehanski izbor, po katerem vsak ( N/n)-ta vrednost splošne populacije. Na primer, če vsebuje 100.000 vrednosti in želite izbrati 1000, bo vsaka 100.000 / 1000 = 100. vrednost padla v vzorec. Poleg tega, če niso razvrščeni, se prvi izbere naključno izmed prvih sto, številke ostalih pa bodo za sto več. Na primer, če je bila enota številka 19 prva, bi morala biti naslednja številka 119, nato številka 219, nato številka 319 in tako naprej. Če so populacijske enote razvrščene, je najprej izbrana #50, nato #150, nato #250 in tako naprej.
- Izvede se izbor vrednosti iz heterogenega podatkovnega niza stratificiran(stratificirana) metoda, ko je splošna populacija predhodno razdeljena na homogene skupine, za katere se uporablja naključna ali mehanska selekcija.
- Posebna metoda vzorčenja je serijski selekcija, pri kateri niso naključno ali mehansko izbrane posamezne količine, temveč njihove serije (zaporedja od nekega števila do nekaterih v vrsti), znotraj katerih poteka kontinuirano opazovanje.
Kakovost vzorčnih opazovanj je odvisna tudi od vrsta vzorčenja: ponovljeno oz neponavljajoče se.
pri ponovni izbor statistične vrednosti ali njihove serije, ki so padle v vzorec, se po uporabi vrnejo splošni populaciji in imajo možnost, da pridejo v nov vzorec. Hkrati imajo vse vrednosti splošne populacije enako verjetnost, da bodo vključene v vzorec.
Izbor brez ponavljanja pomeni, da se statistične vrednosti ali njihove serije, vključene v vzorec, po uporabi ne vrnejo splošni populaciji, zato se poveča verjetnost, da pridejo v naslednji vzorec, za preostale vrednosti slednjega.
Neponavljajoče se vzorčenje daje natančnejše rezultate, zato se uporablja pogosteje. Obstajajo pa situacije, ko je ni mogoče uporabiti (študija tokov potnikov, povpraševanje potrošnikov itd.), nato pa se izvede ponovna izbira.
Mejna napaka vzorca opazovanja, povprečna napaka vzorca, vrstni red, v katerem so izračunani.
Oglejmo si podrobneje zgornje metode oblikovanja vzorčne populacije in napake, ki nastanejo v tem primeru. reprezentativnost .
Pravzaprav - naključno vzorec temelji na naključnem izboru enot iz splošne populacije brez elementov konsistentnosti. Tehnično se pravilna naključna izbira izvede z žrebom (na primer loterija) ali s tabelo naključnih števil.Pravzaprav naključna izbira "v svoji čisti obliki" se v praksi selektivnega opazovanja redko uporablja, vendar je začetna med drugimi vrstami selekcije, izvaja osnovna načela selektivnega opazovanja. Razmislimo o nekaterih vprašanjih teorije metode vzorčenja in formule napake za preprost naključni vzorec.
Napaka vzorčenja- to je razlika med vrednostjo parametra v splošni populaciji in njegovo vrednostjo, izračunano iz rezultatov vzorčnega opazovanja. Za povprečno kvantitativno značilnost se vzorčna napaka določi z
Indikator se imenuje mejna vzorčna napaka.
Vzorčno povprečje je naključna spremenljivka, ki lahko traja različne pomene odvisno od tega, katere enote so bile vključene v vzorec. Zato so tudi vzorčne napake naključne spremenljivke in lahko zavzamejo različne vrednosti. Zato je določeno povprečje možne napake - povprečna napaka vzorčenja, kar je odvisno od:Velikost vzorca: kot več moči, manjša je vrednost povprečne napake;
Stopnja spremenjenosti proučevane lastnosti: manjša kot je variacija lastnosti in posledično varianca, manjša je povprečna vzorčna napaka.
pri naključna ponovna izbira povprečna napaka se izračuna:
.
V praksi splošna varianca ni natančno znana, vendar v teorija verjetnosti dokazal, da .
.
Ker je vrednost za dovolj velik n blizu 1, lahko domnevamo, da . Nato je mogoče izračunati srednjo vzorčno napako:
.
Toda v primerih majhnega vzorca (za n<30) коэффициент необходимо учитывать, и среднюю ошибку малой выборки рассчитывать по формуле .
.pri naključno vzorčenje podane formule so popravljene z vrednostjo . Potem je povprečna napaka nevzorčenja:
 in
in  .
.
Ker je vedno manjša od , potem je faktor () vedno manjši od 1. To pomeni, da je povprečna napaka pri neponovljivi izbiri vedno manjša kot pri ponovljeni izbiri.
Mehansko vzorčenje se uporablja, kadar je splošna populacija na nek način urejena (na primer volilni seznami po abecedi, telefonske številke, hišne številke, stanovanja). Izbor enot poteka v določenem intervalu, ki je enak recipročnemu odstotku vzorca. Torej, pri 2% vzorcu je izbranih vsakih 50 enot = 1 / 0,02, pri 5% vsakih 1 / 0,05 = 20 enot splošne populacije.Izvor je izbran na različne načine: naključno, iz sredine intervala, s spremembo izvora. Glavna stvar je, da se izognete sistematičnim napakam. Na primer, pri 5-odstotnem vzorcu, če je kot prva enota izbrana 13., potem naslednjih 33, 53, 73 itd.
Z vidika natančnosti je mehanska selekcija blizu pravilnemu naključnemu vzorčenju. Zato se za določitev povprečne napake mehanskega vzorčenja uporabljajo formule pravilne naključne izbire.
pri tipičen izbor anketirana populacija je predhodno razdeljena na homogene skupine enega tipa. Na primer, pri anketiranju podjetij so to lahko panoge, podsektorji, medtem ko preučujemo prebivalstvo - območja, družbene ali starostne skupine. Nato se izvede neodvisen izbor iz vsake skupine na mehaničen ali pravilno naključen način.
Običajno vzorčenje daje natančnejše rezultate kot druge metode. Tipizacija generalne populacije zagotavlja zastopanost vsake tipološke skupine v vzorcu, kar omogoča izključitev vpliva medskupinske variance na povprečno vzorčno napako. Zato je treba pri ugotavljanju napake tipičnega vzorca po pravilu dodajanja varianc () upoštevati le povprečje skupinskih varianc. Potem je povprečna napaka vzorčenja:
pri ponovnem izboru
,
z neponavljajočim se izborom ,
,
Kje je povprečje varianc znotraj skupine v vzorcu.
je povprečje varianc znotraj skupine v vzorcu.Serijski (ali ugnezdeni) izbor uporablja se, ko je populacija razdeljena v serije ali skupine pred začetkom vzorčnega raziskovanja. Te serije so lahko paketi končnih izdelkov, študentske skupine, ekipe. Serije za pregled se izberejo strojno ali naključno, znotraj serije pa se opravi celoten pregled enot. Zato je povprečna vzorčna napaka odvisna le od medskupinske (medserijske) variance, ki se izračuna po formuli:

kjer je r število izbranih serij;
- povprečje i-te serije.Povprečna napaka serijskega vzorčenja se izračuna:
ob ponovni izbiri:
,
z neponavljajočo se izbiro: ,
,
kjer je R skupno število serij.Kombinirano izbor je kombinacija obravnavanih metod selekcije.
Povprečna vzorčna napaka pri kateri koli selekcijski metodi je odvisna predvsem od absolutne velikosti vzorca in v manjši meri od odstotka vzorca. Recimo, da je v prvem primeru opravljenih 225 opazovanj iz populacije 4.500 enot, v drugem primeru pa iz 225.000 enot. Variance v obeh primerih so enake 25. Potem bo v prvem primeru s 5-odstotnim izborom vzorčna napaka:

V drugem primeru bo z izbiro 0,1 % enako:
torej, z zmanjšanjem vzorčnega odstotka za 50-krat, se je vzorčna napaka nekoliko povečala, saj se velikost vzorca ni spremenila.
Predpostavimo, da se velikost vzorca poveča na 625 opazovanj. V tem primeru je napaka vzorčenja:
Povečanje vzorca za 2,8-krat pri enaki velikosti generalne populacije zmanjša velikost vzorčne napake za več kot 1,6-krat.Metode in sredstva za oblikovanje vzorčne populacije.
V statistiki se uporabljajo različne metode oblikovanja vzorčnih nizov, ki je določena s cilji študije in je odvisna od posebnosti predmeta študije.
Glavni pogoj za izvedbo vzorčnega raziskovanja je preprečitev pojava sistemskih napak, ki izhajajo iz kršitve načela enakih možnosti vsake enote generalne populacije za vstop v vzorec. Preprečevanje sistematičnih napak je doseženo z uporabo znanstveno utemeljenih metod za oblikovanje vzorčne populacije.
Obstajajo naslednji načini za izbiro enot iz splošne populacije:
1) individualni izbor - v vzorec so izbrane posamezne enote;
2) skupinska selekcija - v vzorec spadajo kvalitativno homogene skupine ali serije preučevanih enot;
3) kombinirana selekcija je kombinacija individualne in skupinske selekcije.
Metode izbire določajo pravila za oblikovanje vzorčne populacije.Vzorec je lahko:
- pravilno naključno je v tem, da vzorec nastane kot rezultat naključnega (nenamernega) izbora posameznih enot iz splošne populacije. V tem primeru se število izbranih enot v vzorčnem nizu običajno določi na podlagi sprejetega deleža vzorca. Vzorčni delež je razmerje med številom enot v vzorčni populaciji n in številom enot v generalni populaciji N, tj.
- mehanski je v tem, da je izbor enot v vzorcu narejen iz splošne populacije, razdeljene na enake intervale (skupine). V tem primeru je velikost intervala v splošni populaciji enaka recipročnemu deležu vzorca. Tako je pri 2% vzorcu izbrana vsaka 50. enota (1:0,02), pri 5% vzorcu vsaka 20. enota (1:0,05) itd. Tako je v skladu s sprejetim deležem selekcije splošna populacija tako rekoč mehanično razdeljena na enake skupine. Iz vsake skupine v vzorcu je izbrana samo ena enota.
- tipično - pri kateri se splošna populacija najprej razdeli na homogene tipične skupine. Nato se iz vsake tipične skupine z naključnim ali mehanskim vzorcem izvede posamezen izbor enot v vzorec. Pomembna značilnost tipičnega vzorca je, da daje natančnejše rezultate v primerjavi z drugimi metodami izbire enot v vzorec;
- serijski- pri kateri je generalna populacija razdeljena na enako velike skupine - serije. Serije so izbrane v vzorčnem nizu. Znotraj serije se izvaja kontinuirano opazovanje enot, ki so padle v serijo;
- kombinirano- vzorčenje je lahko dvostopenjsko. V tem primeru se splošna populacija najprej razdeli na skupine. Nato se izberejo skupine, znotraj slednjih pa posamezne enote.
V statistiki se razlikujejo naslednje metode izbire enot v vzorcu::
- enostopenjski vzorec - vsaka izbrana enota je takoj predmet študije na dani osnovi (pravzaprav naključni in serijski vzorci);
- večstopenjski vzorčenje - izbor poteka iz generalne populacije posameznih skupin, iz skupin pa se izberejo posamezne enote (tipični vzorec z mehanskim načinom izbora enot v vzorčno populacijo).
Poleg tega obstajajo:
- ponovna izbira- po shemi vrnjene žoge. V tem primeru se vsaka enota ali serija, ki je padla v vzorec, vrne v splošno populacijo in ima torej možnost, da se ponovno vključi v vzorec;
- izbor brez ponavljanja- po shemi nevrnjene žoge. Ima natančnejše rezultate za enako velikost vzorca.
Določitev zahtevane velikosti vzorca (z uporabo Studentove tabele).
Eno od znanstvenih načel teorije vzorčenja je zagotoviti, da je izbrano zadostno število enot. Teoretično je potreba po upoštevanju tega načela predstavljena v dokazih mejnih izrekov teorije verjetnosti, ki vam omogočajo, da ugotovite, koliko enot je treba izbrati iz splošne populacije, tako da je zadostna in zagotavlja reprezentativnost vzorca.
Zmanjšanje standardne napake vzorca in posledično povečanje natančnosti ocene je vedno povezano s povečanjem velikosti vzorca, zato se je treba že v fazi organiziranja vzorčnega opazovanja odločiti, kakšna mora biti velikost vzorca, da se zagotovi zahtevana točnost rezultatov opazovanja. Izračun zahtevane velikosti vzorca je zgrajen z uporabo formul, izpeljanih iz formul za mejne napake vzorčenja (A), ki ustrezajo eni ali drugi vrsti in metodi izbire. Za naključno ponovljeno velikost vzorca (n) imamo torej:

Bistvo te formule je, da je z naključnim ponovnim izborom zahtevanega števila velikost vzorca neposredno sorazmerna s kvadratom koeficienta zaupanja. (t2) in varianco značilnosti variacije (?2) in je obratno sorazmerna s kvadratom mejne vzorčne napake (?2). Zlasti s podvojitvijo mejne napake se lahko zahtevana velikost vzorca zmanjša za faktor štiri. Od treh parametrov dva (t in?) določi raziskovalec.
Hkrati pa raziskovalec Za namene vzorčnega raziskovanja se je treba odločiti o vprašanju, v kakšno kvantitativno kombinacijo je bolje vključiti te parametre, da bi zagotovili optimalno varianto? V enem primeru je lahko bolj zadovoljen z zanesljivostjo dobljenih rezultatov (t) kot z merilom natančnosti (?), v drugem - obratno. Težje je rešiti vprašanje glede vrednosti mejne vzorčne napake, saj raziskovalec tega indikatorja v fazi načrtovanja vzorčnega opazovanja nima, zato je v praksi običajno, da se mejna vzorčna napaka določi kot praviloma znotraj 10 % pričakovane povprečne ravni lastnosti. Določitvi domnevne povprečne ravni se je mogoče lotiti na različne načine: z uporabo podatkov iz podobnih prejšnjih raziskav ali z uporabo podatkov iz vzorčnega okvira in vzeti majhen pilotni vzorec.
Pri načrtovanju vzorčnega opazovanja je najtežje ugotoviti tretji parameter v formuli (5.2) - varianco vzorčne populacije. V tem primeru je treba uporabiti vse podatke, ki so na voljo raziskovalcu in so pridobljeni iz prejšnjih podobnih in pilotnih raziskav.
Vprašanje definicije Zahtevana velikost vzorca postane bolj zapletena, če vzorčno raziskovanje vključuje preučevanje več značilnosti vzorčnih enot. V tem primeru so povprečne ravni vsake značilnosti in njihove variacije praviloma različne, zato se je mogoče odločiti, kateri razpršenosti katere od značilnosti dati prednost le ob upoštevanju namena in ciljev anketa.
Pri načrtovanju vzorčnega opazovanja se predpostavi vnaprej določena vrednost dopustne vzorčne napake v skladu s cilji posamezne študije in verjetnostjo sklepov na podlagi rezultatov opazovanja.
Na splošno vam formula za mejno napako vzorčne srednje vrednosti omogoča določitev:
Velikost možnih odstopanj kazalnikov splošne populacije od kazalnikov vzorčne populacije;
zahtevana velikost vzorca, ki zagotavlja zahtevano natančnost, pri kateri meje možne napake ne bodo presegle določene določene vrednosti;
Verjetnost, da bo napaka v vzorcu imela dano mejo.
Študentska distribucija v teoriji verjetnosti je enoparametrska družina absolutno zveznih porazdelitev.
Niz dinamike (interval, moment), zaprtje niza dinamike.
Serija dinamike- to so vrednosti statističnih kazalnikov, ki so predstavljene v določenem kronološkem zaporedju.
Vsaka časovna vrsta vsebuje dve komponenti:
1) kazalniki časovnih obdobij (leta, četrtletja, meseci, dnevi ali datumi);
2) kazalniki, ki označujejo preučevani predmet za časovna obdobja ali na ustrezne datume, ki se imenujejo ravni serije.
Stopnje serije so izražene tako absolutne kot povprečne ali relativne vrednosti. Glede na naravo kazalnikov so zgrajene dinamične serije absolutnih, relativnih in povprečnih vrednosti. Dinamični nizi relativnih in povprečnih vrednosti so zgrajeni na podlagi izpeljanih nizov absolutnih vrednosti. Obstajajo intervalne in trenutne serije dinamike.
Dinamične intervalne serije vsebuje vrednosti kazalnikov za določena časovna obdobja. V intervalnem nizu lahko nivoje seštejemo in tako dobimo obseg pojava za daljše obdobje ali tako imenovane akumulirane vsote.
Serija dinamičnih trenutkov odraža vrednosti kazalnikov v določenem trenutku (datum). Pri trenutnih nizih lahko raziskovalca zanima le razlika pojavov, ki odraža spremembo nivoja niza med določenimi datumi, saj vsota nivojev tukaj nima prave vsebine. Kumulativne vsote tukaj niso izračunane.
Najpomembnejši pogoj za pravilno konstrukcijo dinamičnih serij je primerljivost ravni serij, ki se nanašajo na različna obdobja. Ravni morajo biti predstavljene v homogenih količinah, mora biti enaka popolnost pokritosti različnih delov pojava.
Da bi Da bi se izognili izkrivljanju realne dinamike, se v statistični študiji (zapiranje časovne vrste) izvedejo preliminarni izračuni pred statistično analizo časovne vrste. Zaprtost časovnih vrst se razume kot združevanje dveh ali več serij v eno serijo, katere ravni so izračunane po različnih metodologijah ali ne ustrezajo teritorialnim mejam itd. Zapiranje dinamičnega niza lahko pomeni tudi redukcijo absolutnih nivojev dinamičnega niza na skupno osnovo, kar odpravlja nekompatibilnost nivojev dinamičnega niza.
Koncept primerljivosti časovnih vrst, koeficientov, rasti in stopenj rasti.
Serija dinamike- to so nizi statističnih kazalcev, ki označujejo razvoj naravnih in družbenih pojavov v času. Statistične zbirke, ki jih objavlja Državni statistični odbor Rusije, vsebujejo veliko število časovnih vrst v obliki tabele. Niz dinamike omogoča razkrivanje vzorcev razvoja proučevanih pojavov.
Časovne vrste vsebujejo dve vrsti indikatorjev. Indikatorji časa(leta, četrtletja, meseci itd.) ali časovne točke (na začetku leta, na začetku vsakega meseca itd.). Indikatorji ravni vrstic. Kazalnike ravni časovne vrste lahko izrazimo v absolutnih vrednostih (proizvodnja izdelka v tonah ali rubljih), relativnih vrednostih (delež mestnega prebivalstva v %) in povprečnih vrednostih (povprečne plače delavcev v industriji). po letih itd.). V obliki tabele časovna vrsta vsebuje dva stolpca ali dve vrstici.
Pravilna konstrukcija časovnih vrst vključuje izpolnjevanje številnih zahtev:
- vsi kazalniki niza dinamike morajo biti znanstveno utemeljeni, zanesljivi;
- kazalniki serije dinamike morajo biti časovno primerljivi, tj. morajo biti izračunani za ista časovna obdobja ali na iste datume;
- kazalniki številnih dinamik naj bodo primerljivi po ozemlju;
- kazalniki niza dinamike naj bodo vsebinsko primerljivi, tj. izračunano po enotni metodologiji, na enak način;
- kazalniki vrste dinamike bi morali biti primerljivi med vsemi obravnavanimi kmetijami. Vse kazalnike niza dinamike je treba navesti v istih merskih enotah.
Statistični kazalci lahko označi bodisi rezultate preučevanega procesa v določenem časovnem obdobju bodisi stanje preučevanega pojava v določenem trenutku, tj. kazalniki so lahko intervalni (periodični) in trenutni. V skladu s tem je na začetku lahko niz dinamike interval ali trenutek. Trenutni nizi dinamike pa so lahko z enakimi in neenakimi časovnimi intervali.
Začetni niz dinamike se lahko pretvori v niz povprečnih vrednosti in niz relativnih vrednosti (veriga in osnova). Takšne časovne vrste imenujemo izpeljane časovne vrste.
Metoda izračuna povprečne ravni v nizu dinamike je različna, odvisno od vrste niza dinamike. Na primerih razmislite o vrstah časovnih vrst in formulah za izračun povprečne ravni.
Absolutni dobički (Δy) prikazujejo, za koliko enot se je naslednja raven niza spremenila glede na prejšnjo (stolpec 3. - verižni absolutni prirastki) oziroma glede na začetno raven (stolpec 4. - osnovni absolutni prirastki). Formule za izračun lahko zapišemo na naslednji način:

Z zmanjšanjem absolutnih vrednosti serije bo prišlo do "zmanjšanja", "zmanjšanja" oz.
Kazalniki absolutne rasti kažejo, da se je na primer v letu 1998 proizvodnja proizvoda »A« v primerjavi z letom 1997 povečala za 4.000 ton, v primerjavi z letom 1994 pa za 34.000 ton; za druga leta glej tabelo. 11,5 gr. 3 in 4.
Faktor rasti prikazuje, kolikokrat se je stopnja serije spremenila glede na prejšnjo (stolpec 5 - verižni faktorji rasti ali upadanja) oziroma glede na začetno raven (stolpec 6 - osnovni faktorji rasti ali upadanja). Formule za izračun lahko zapišemo na naslednji način:

Stopnje rasti kažejo, za koliko odstotkov je naslednja stopnja niza v primerjavi s prejšnjo (stolpec 7 - verižne stopnje rasti) ali v primerjavi z začetno stopnjo (stolpec 8 - osnovne stopnje rasti). Formule za izračun lahko zapišemo na naslednji način:

Tako je na primer leta 1997 obseg proizvodnje izdelka "A" v primerjavi z letom 1996 znašal 105,5% (
Stopnja rasti za koliko odstotkov se je povečala raven poročevalskega obdobja glede na prejšnje (stolpec 9 - verižne stopnje rasti) oziroma glede na začetno raven (stolpec 10 - osnovne stopnje rasti). Formule za izračun lahko zapišemo na naslednji način:
T pr \u003d T p - 100% ali T pr \u003d absolutno povečanje / raven prejšnjega obdobja * 100%
Tako je bil na primer leta 1996 v primerjavi z letom 1995 proizveden izdelek "A" več za 3,8% (103,8% - 100%) ali (8:210) x 100%, v primerjavi z letom 1994 - za 9% ( 109 % - 100 %).
Če se absolutne ravni v nizu zmanjšajo, bo stopnja nižja od 100% in v skladu s tem bo prišlo do stopnje upadanja (stopnja rasti s predznakom minus).
Absolutna vrednost 1 % povečanja(stolpec 11) prikazuje, koliko enot je treba proizvesti v določenem obdobju, da se raven prejšnjega obdobja poveča za 1 %. V našem primeru je bilo leta 1995 potrebno proizvesti 2,0 tisoč ton, leta 1998 pa 2,3 tisoč ton, tj. veliko večji.
Obstajata dva načina za določitev velikosti absolutne vrednosti 1-odstotne rasti:
Raven prejšnjega obdobja delite s 100;
Delite absolutne stopnje rasti verige z ustreznimi stopnjami rasti verige.
Absolutna vrednost 1 % povečanja =

V dinamiki, zlasti v daljšem obdobju, je pomembna skupna analiza stopnje rasti z vsebino vsakega odstotka povečanja ali zmanjšanja.
Upoštevajte, da je obravnavana metodologija za analizo časovnih vrst uporabna tako za časovne serije, katerih ravni so izražene v absolutnih vrednostih (t, tisoč rubljev, število zaposlenih itd.), In za časovne serije, ravni ki so izraženi v relativnih kazalnikih (% ostankov, % vsebnosti pepela v premogu itd.) ali povprečnih vrednostih (povprečni pridelek v c/ha, povprečne plače itd.).
Poleg obravnavanih analitičnih kazalnikov, izračunanih za vsako leto v primerjavi s prejšnjo ali začetno ravnjo, je treba pri analizi časovne vrste izračunati povprečne analitične kazalnike za obdobje: povprečno raven serije, povprečno letno absolutno povečanje (zmanjšanje) ter povprečna letna stopnja rasti in stopnja rasti.
Metode za izračun povprečne ravni niza dinamike so bile obravnavane zgoraj. V intervalni seriji dinamike, ki jo obravnavamo, se povprečna raven serije izračuna po formuli preproste aritmetične sredine:
Povprečna letna proizvodnja izdelka za 1994-1998. znašala 218,4 tisoč ton.
Tudi povprečni letni absolutni prirast se izračuna po formuli enostavne aritmetične sredine:
Letni absolutni prirastki so se po letih gibali od 4 do 12 tisoč ton (glej gr. 3), povprečno letno povečanje proizvodnje pa za obdobje 1995 - 1998. znašala 8,5 tisoč ton.
Metode za izračun povprečne stopnje rasti in povprečne stopnje rasti zahtevajo podrobnejšo obravnavo. Razmislimo o njih na primeru letnih kazalnikov ravni serije, podanih v tabeli.
Srednja raven razpona dinamike.
Niz dinamike (ali časovni niz)- to so številčne vrednosti določenega statističnega kazalnika v zaporednih trenutkih ali časovnih obdobjih (torej urejene v kronološkem vrstnem redu).
Imenujejo se številčne vrednosti določenega statističnega indikatorja, ki sestavlja vrsto dinamike ravni števila in je običajno označen s črko l. Prvi član serije y 1 imenovani začetni oz izhodišče, in zadnji y n - dokončno. Trenutki ali časovna obdobja, na katere se ravni nanašajo, so označeni z t.
Dinamične serije so praviloma predstavljene v obliki tabele ali grafa, časovna lestvica pa je zgrajena vzdolž osi x. t, in vzdolž ordinate - lestvica ravni serije l.
Povprečni kazalniki serije dinamike
Vsako serijo dinamike lahko obravnavamo kot določen niz nčasovno spremenljivi kazalci, ki jih je mogoče povzeti kot povprečja. Takšni posplošeni (povprečni) kazalniki so še posebej potrebni pri primerjavi sprememb enega ali drugega kazalnika v različnih obdobjih, v različnih državah itd.
Splošna značilnost serije dinamike je lahko najprej povprečna raven vrstice. Način izračuna povprečne ravni je odvisen od tega, ali gre za trenutni niz ali intervalni (periodni) niz.
Kdaj interval serije, je njena povprečna raven določena s formulo preproste aritmetične sredine ravni serije, tj.
=
Če je na voljo trenutek vrstica, ki vsebuje n stopnje ( y1, y2, …, yn) z enakimi intervali med datumi (časovnimi točkami), potem lahko takšno vrsto enostavno pretvorimo v vrsto povprečnih vrednosti. Hkrati je indikator (raven) na začetku vsakega obdobja hkrati indikator na koncu prejšnjega obdobja. Nato lahko povprečno vrednost indikatorja za vsako obdobje (interval med datumi) izračunamo kot polovično vsoto vrednosti pri na začetku in koncu obdobja, tj. Kako. Število takih povprečij bo . Kot smo že omenili, se za serije povprečij povprečna raven izračuna iz aritmetičnega povprečja.Zato lahko zapišemo:
 .
.
Po pretvorbi števca dobimo: ,
,Kje Y1 in Yn- prva in zadnja stopnja serije; Yi- vmesne stopnje.
To povprečje je v statistiki znano kot povprečno kronološko za trenutne serije. To ime je prejela iz besede "cronos" (čas, lat.), Ker se izračuna iz indikatorjev, ki se spreminjajo skozi čas.
V primeru neenakega intervalih med datumi, lahko kronološko povprečje za serijo trenutkov izračunamo kot aritmetično povprečje povprečnih vrednosti ravni za vsak par trenutkov, ponderiranih z razdaljami (časovnimi intervali) med datumi, tj.
 .
.
V tem primeru predpostavlja se, da so v intervalih med datumi nivoji prevzeli različne vrednosti in izhajamo iz dveh znanih ( yi in yi+1) določimo povprečja, iz katerih nato izračunamo skupno povprečje za celotno analizirano obdobje.
Če se predpostavi, da je vsaka vrednost yi ostane nespremenjena do naslednjega (i+ 1)- trenutek, tj. če je znan točen datum spremembe ravni, se lahko izračun izvede s formulo utežene aritmetične sredine:
,kjer je čas, v katerem je raven ostala nespremenjena.
Poleg povprečne ravni v seriji dinamike se izračunajo tudi drugi povprečni kazalniki - povprečna sprememba ravni serije (osnovne in verižne metode), povprečna stopnja spremembe.
Osnovna vrednost pomeni absolutno spremembo je količnik zadnje osnovne absolutne spremembe, deljen s številom sprememb. To je
Veriga pomeni absolutno spremembo ravni niza je količnik deljenja vsote vseh verižnih absolutnih sprememb s številom sprememb, tj.
Po predznaku povprečnih absolutnih sprememb se v povprečju presoja tudi narava spremembe pojava: rast, upad ali stabilnost.
Iz pravila za nadzor osnovne in verižne absolutne spremembe izhaja, da morata biti osnovna in verižna povprečna sprememba enaki.
Poleg povprečne absolutne spremembe se izračuna tudi povprečna relativna po osnovni in verižni metodi.
Osnovna povprečna relativna sprememba se določi s formulo:
Verižna srednja relativna sprememba se določi s formulo:
Seveda morata biti osnovna in verižna povprečna relativna sprememba enaki, s primerjavo z merilno vrednostjo 1 pa se sklepa o naravi spremembe pojava v povprečju: rast, upad ali stabilnost.
Z odštevanjem 1 od osnovne ali verižne povprečne relativne spremembe dobimo ustrezno povprečna stopnja spremembe, po znaku katerega je mogoče presoditi tudi naravo spremembe v proučevanem pojavu, ki ga odraža ta niz dinamike.Sezonska nihanja in indeksi sezonskosti.
Sezonska nihanja so stabilna znotrajletna nihanja.
Osnovno načelo upravljanja za doseganje maksimalnega učinka je maksimizacija prihodkov in minimizacija stroškov. S proučevanjem sezonskih nihanj se rešuje problem enačbe maksimuma v vsaki ravni leta.
Pri proučevanju sezonskih nihanj se rešujeta dve med seboj povezani nalogi:
1. Identifikacija posebnosti razvoja pojava v znotrajletni dinamiki;
2. Merjenje sezonskih nihanj z izgradnjo modela sezonskih valov;
Sezonski purani se običajno štejejo za merjenje sezonskosti. Na splošno so določene z razmerjem med izvirnimi enačbami dinamičnega niza in teoretičnimi enačbami, ki služijo kot osnova za primerjavo.
Ker so naključna odstopanja prekrita s sezonskimi nihanji, se indeksi sezonskosti povprečijo, da se jih odpravi.
V tem primeru se za vsako obdobje letnega cikla določijo splošni kazalniki v obliki povprečnih sezonskih indeksov:
Povprečni indeksi sezonskih nihanj so brez vpliva naključnih odstopanj glavnega trenda razvoja.
Odvisno od narave trenda ima lahko formula za povprečni indeks sezonskosti naslednje oblike:
1.Za serijo medletne dinamike z izrazitim glavnim trendom razvoja:
2. Za serijo medletne dinamike, v kateri ni naraščajočega ali padajočega trenda ali je nepomemben:
Kje je generalna povprečja;
Metode za analizo glavnega trenda.
Na razvoj pojavov skozi čas vplivajo po naravi in moči vpliva različni dejavniki. Nekateri od njih so naključne narave, drugi imajo skoraj konstanten učinek in tvorijo določen razvojni trend v nizu dinamike.
Pomembna naloga statistike je ugotoviti trend v nizu dinamike, osvobojen delovanja različnih naključnih dejavnikov. V ta namen se časovne vrste obdelujejo z metodami intervalne povečave, drsečega povprečja in analitične poravnave itd.
Metoda intervalnega grobenja temelji na širjenju časovnih obdobij, ki vključujejo stopnje niza dinamike, tj. je zamenjava podatkov, ki se nanašajo na majhna časovna obdobja, s podatki iz večjih obdobij. Še posebej učinkovito je, če so začetne stopnje serije kratke. Na primer, serije kazalnikov, povezanih z dnevnimi dogodki, se nadomestijo s serijami, ki se nanašajo na tedenske, mesečne itd. To se bo bolj jasno pokazalo "Os razvoja fenomena". Povprečje, izračunano na podlagi povečanih intervalov, omogoča ugotavljanje smeri in značaja (pospešek ali upočasnitev rasti) glavnega razvojnega trenda.
metoda drsečega povprečja podoben prejšnjemu, vendar so v tem primeru dejanske ravni nadomeščene s povprečnimi ravnmi, izračunanimi za zaporedno premikajoče se (drseče) povečane intervale, ki pokrivajo m ravni vrstic.
Na primerče je sprejet m=3, nato se najprej izračuna povprečje prvih treh ravni serije, nato - iz istega števila ravni, vendar začenši z drugo zaporedoma, nato - začenši s tretjo itd. Tako povprečje, tako rekoč, "drsi" vzdolž niza dinamike in se premika za eno obdobje. Preračunano iz mčlani drsečih povprečij se nanašajo na sredino (središče) vsakega intervala.
Ta metoda odpravi samo naključna nihanja. Če ima niz sezonski val, bo ostal po glajenju z metodo drsečega povprečja.
Analitična poravnava. Da bi odpravili naključna nihanja in identificirali trend, so nivoji serije poravnani v skladu z analitičnimi formulami (ali analitično poravnavo). Njegovo bistvo je v zamenjavi empiričnih (dejanskih) ravni s teoretičnimi, ki so izračunane po določeni enačbi, vzeti kot matematični model trenda, kjer se teoretične ravni obravnavajo kot funkcija časa: . V tem primeru se vsaka dejanska raven obravnava kot vsota dveh komponent: , kjer je sistematična komponenta, izražena z določeno enačbo, in je naključna spremenljivka, ki povzroča nihanja okoli trenda.
Naloga analitičnega usklajevanja je naslednja:
1. Na podlagi dejanskih podatkov določite vrsto hipotetične funkcije, ki lahko najbolj ustrezno odraža razvojni trend proučevanega kazalnika.
2. Iskanje parametrov navedene funkcije (enačbe) iz empiričnih podatkov
3. Izračun po najdeni enačbi teoretičnih (niveliranih) nivojev.
Izbira določene funkcije se praviloma izvaja na podlagi grafičnega prikaza empiričnih podatkov.
Modeli so regresijske enačbe, katerih parametri so izračunani po metodi najmanjših kvadratov
Spodaj so najpogosteje uporabljene regresijske enačbe za izravnavo časovnih vrst z navedbo, katere razvojne trende najprimerneje odražajo.
Za iskanje parametrov zgornjih enačb obstajajo posebni algoritmi in računalniški programi. Zlasti za iskanje parametrov enačbe ravne črte je mogoče uporabiti naslednji algoritem:

Če obdobja ali časovne trenutke oštevilčimo tako, da dobimo St = 0, se bodo zgornji algoritmi znatno poenostavili in spremenili v

Poravnane ravni na grafikonu se bodo nahajale na eni ravni črti, ki poteka na najbližji razdalji od dejanskih ravni te dinamične serije. Vsota kvadratov odstopanj je odraz vpliva naključnih dejavnikov.
Z njegovo pomočjo izračunamo povprečno (standardno) napako enačbe:

Tu je n število opazovanj, m pa število parametrov v enačbi (imamo dva od njih - b 1 in b 0).
Glavni trend (trend) prikazuje, kako sistematični dejavniki vplivajo na ravni niza dinamike, nihanje ravni okoli trenda () pa služi kot merilo vpliva preostalih dejavnikov.
Za oceno kakovosti uporabljenega modela časovne vrste se uporablja tudi Fisherjev F test. Je razmerje dveh varianc, in sicer razmerje variance, ki jo povzroča regresija, tj. proučevanega faktorja, na razpršitev, ki jo povzročajo naključni vzroki, tj. preostala varianca:

V razširjeni obliki lahko formulo za to merilo predstavimo na naslednji način:

kjer je n število opazovanj, tj. število ravni vrstic,
m je število parametrov v enačbi, y je dejanska raven niza,
Poravnana raven vrstice, - povprečna raven vrstice.
Model, ki je uspešnejši od drugih, morda ni vedno dovolj zadovoljiv. Kot tako ga lahko prepoznamo le, če kriterij F zanj preseže določeno kritično mejo. Ta meja je nastavljena z uporabo F distribucijskih tabel.
Bistvo in klasifikacija indeksov.
Indeks v statistiki se razume kot relativni kazalnik, ki označuje spremembo velikosti pojava v času, prostoru ali v primerjavi s katerim koli standardom.
Glavni element indeksne relacije je indeksirana vrednost. Indeksirano vrednost razumemo kot vrednost znaka statistične populacije, katere sprememba je predmet proučevanja.
Indeksi imajo tri glavne namene:
1) ocena sprememb v kompleksnem pojavu;
2) ugotavljanje vpliva posameznih dejavnikov na spremembo kompleksnega pojava;
3) primerjava obsega nekega pojava z obsegom preteklega obdobja, obsegom drugega ozemlja, pa tudi s standardi, načrti, napovedmi.
Indeksi so razvrščeni po 3 kriterijih:
2) po stopnji pokritosti elementov prebivalstva;
3) z metodami izračuna splošnih indeksov.
Po vsebini indeksiranih vrednosti se indeksi delijo na indekse kvantitativnih (volumetričnih) kazalnikov in indekse kvalitativnih kazalnikov. Indeksi kvantitativnih kazalnikov - indeksi fizičnega obsega industrijske proizvodnje, fizičnega obsega prodaje, števila itd. Indeksi kvalitativnih kazalnikov - indeksi cen, stroškov, produktivnosti dela, povprečnih plač itd.
Glede na stopnjo zajetja enot populacije se indeksi delijo na dva razreda: individualne in splošne. Za njihovo opredelitev uvajamo naslednje konvencije, sprejete v praksi uporabe indeksne metode:
q- količina (prostornina) katerega koli proizvoda v naravi ; R- ceno proizvodnje na enoto; z- stroški proizvodnje na enoto; t- čas, porabljen za proizvodnjo enote proizvoda (delovna intenzivnost) ; w- vrednostni obseg proizvodnje na časovno enoto; v- proizvodnja v fizičnem smislu na časovno enoto; T- skupni porabljeni čas ali število zaposlenih.
Da bi razločili, kateremu obdobju ali predmetu pripadajo indeksirane vrednosti, je običajno, da za ustreznim simbolom spodaj desno postavite indekse. Tako se na primer v indeksih dinamike praviloma za primerjana (tekoča, poročevalska) obdobja uporablja indeks 1 in za obdobja, s katerimi se primerja,
Posamezni indeksi služijo za karakterizacijo spremembe posameznih elementov kompleksnega pojava (na primer sprememba obsega proizvodnje ene vrste izdelka). Predstavljajo relativne vrednosti dinamike, izpolnitev obveznosti, primerjavo indeksiranih vrednosti.
Določen je individualni indeks fizičnega obsega proizvodnje
Z analitičnega vidika so navedeni posamezni indeksi dinamike podobni koeficientom (stopnjam) rasti in označujejo spremembo indeksirane vrednosti v tekočem obdobju glede na bazno, tj. kažejo, kolikokrat se je povečala (zmanjšala) ) oziroma za koliko odstotkov gre za rast (zmanjšanje). Vrednosti indeksa so izražene v koeficientih ali odstotkih.
Splošni (sestavljeni) indeks odraža spremembo vseh elementov kompleksnega pojava.
Zbirni indeks je osnovna oblika indeksa. Imenuje se agregat, ker sta njegov števec in imenovalec niz "agregata"
Povprečni indeksi, njihova definicija.
Poleg agregatnih indeksov se v statistiki uporablja še ena njihova oblika - tehtani povprečni indeksi. K njihovemu izračunu se zatečejo, kadar razpoložljive informacije ne omogočajo izračuna splošnega agregatnega indeksa. Torej, če ni podatka o cenah, obstajajo pa podatki o stroških proizvodov v tekočem obdobju in so znani posamezni indeksi cen za vsak proizvod, potem splošnega indeksa cen ni mogoče določiti kot agregatnega, lahko pa ga izračunati kot povprečje posameznih. Na enak način, če količine posameznih proizvedenih proizvodov niso znane, znani pa so posamezni indeksi in proizvodni stroški baznega obdobja, potem lahko skupni indeks fizičnega obsega proizvodnje določimo kot tehtano povprečje.
Povprečni indeks - to indeks, izračunan kot povprečje posameznih indeksov. Agregatni indeks je osnovna oblika generalnega indeksa, zato mora biti povprečni indeks enak agregatnemu indeksu. Pri izračunu povprečnih indeksov se uporabljata dve obliki povprečij: aritmetična in harmonična.
Indeks aritmetične sredine je enak agregatnemu indeksu, če so uteži posameznih indeksov členi imenovalca agregatnega indeksa. Le v tem primeru bo vrednost indeksa, izračunana s formulo aritmetične sredine, enaka agregatnemu indeksu.

