מתמטיקאים וסטטיסטיקאים חכמים הגיעו עם אינדיקטור אמין יותר, אם כי למטרה מעט שונה - סטייה ליניארית מתכוונת. אינדיקטור זה מאפיין את מידת התפשטות ערכי מערך הנתונים סביב ערכם הממוצע.
על מנת להראות את מידת התפשטות הנתונים, תחילה יש לקבוע למה עצם הפיזור הזה ייחשב ביחס – בדרך כלל זהו הערך הממוצע. לאחר מכן, עליך לחשב עד כמה הערכים של מערך הנתונים המנותח רחוקים מהממוצע. ברור שכל ערך תואם כמות מסוימת של סטייה, אך אנו מעוניינים גם בהערכה כללית המכסה את כלל האוכלוסייה. לכן, הסטייה הממוצעת מחושבת באמצעות הנוסחה של הממוצע האריתמטי הרגיל. אבל! אבל כדי לחשב את ממוצע הסטיות יש להוסיף אותן תחילה. ואם נוסיף מספרים חיוביים ושליליים, הם יבטלו זה את זה והסכום שלהם ישטה לאפס. כדי למנוע זאת, כל הסטיות נלקחות מודולו, כלומר, כל המספרים השליליים הופכים לחיוביים. כעת הסטייה הממוצעת תציג מדד כללי של התפשטות הערכים. כתוצאה מכך, הסטייה הליניארית הממוצעת תחושב על ידי הנוסחה:
אהיא הסטייה הליניארית הממוצעת,
איקס- המחוון המנותח, עם מקף למעלה - הערך הממוצע של המחוון,
נהוא מספר הערכים במערך הנתונים המנותח,
מפעיל הסיכומים, אני מקווה, לא מפחיד אף אחד.
הסטייה הליניארית הממוצעת המחושבת באמצעות הנוסחה שצוינה משקפת את הסטייה המוחלטת הממוצעת מהערך הממוצע עבור אוכלוסייה זו.

הקו האדום בתמונה הוא הערך הממוצע. הסטיות של כל תצפית מהממוצע מסומנות בחצים קטנים. הם נלקחים מודולו ומסכמים. ואז הכל מחולק במספר הערכים.
כדי להשלים את התמונה, צריך לתת עוד דוגמה אחת. נניח שיש חברה המייצרת ייחורים לאתים. כל חיתוך חייב להיות באורך 1.5 מטר, אבל חשוב מכך, כולם חייבים להיות זהים או, לפחות, פלוס מינוס 5 ס"מ. עם זאת, עובדים רשלניים ינסרו 1.2 מ' או 1.8 מ'. תושבי הקיץ אינם מרוצים. מנהל החברה החליט לבצע ניתוח סטטיסטי של אורך הייחורים. בחרתי 10 חלקים ומדדתי את אורכם, מצאתי את הממוצע וחישבתי את הסטייה הליניארית הממוצעת. הממוצע התברר כנכון - 1.5 מ'. אבל הסטייה הליניארית הממוצעת התבררה כ-0.16 מ'. אז מסתבר שכל חיתוך ארוך או קצר מהנדרש בממוצע של 16 ס"מ. יש על מה לדבר. עם עובדים. למעשה, לא ראיתי את השימוש האמיתי במדד הזה, אז הבאתי דוגמה בעצמי. עם זאת, יש אינדיקטור כזה בסטטיסטיקה.
פְּזִירָה
כמו הסטייה הליניארית הממוצעת, השונות משקפת גם את מידת התפשטות הנתונים סביב הממוצע.
הנוסחה לחישוב השונות נראית כך:
 (עבור סדרות וריאציות (שונות משוקללת))
(עבור סדרות וריאציות (שונות משוקללת))
 (עבור נתונים לא מקובצים (שונות פשוטה))
(עבור נתונים לא מקובצים (שונות פשוטה))
איפה: σ 2 - פיזור, שי- אנו מנתחים את מחוון ה-sq (ערך תכונה), - הערך הממוצע של המחוון, f i - מספר הערכים במערך הנתונים המנותח.
השונות היא הריבוע הממוצע של הסטיות.
ראשית, הממוצע מחושב, לאחר מכן לוקחים את ההפרש בין כל קו בסיס לממוצע, בריבוע, מוכפל בתדירות של ערך התכונה המתאים, מוסיפים, ולאחר מכן מחלקים במספר הערכים באוכלוסיה.
עם זאת, ב צורה טהורה, כגון הממוצע האריתמטי, או המדד, השונות אינה משמשת. זהו אינדיקטור עזר וביניים המשמש לסוגים אחרים של ניתוח סטטיסטי.
דרך פשוטה לחישוב השונות
![]()
סטיית תקן
כדי להשתמש בשונות לניתוח נתונים, נלקח ממנה שורש ריבועי. מתברר מה שנקרא סטיית תקן.

אגב, סטיית התקן נקראת גם סיגמה - מהאות היוונית שמציינת אותה.
סטיית התקן מאפיינת כמובן גם את מדד פיזור הנתונים, אך כעת (בניגוד לפיזור) ניתן להשוות אותה לנתונים המקוריים. ככלל, אינדיקטורים של ריבוע ממוצע בסטטיסטיקה נותנים תוצאות מדויקות יותר מאלו ליניאריות. לכן, ממוצע סטיית תקןהוא מדד מדויק יותר לפיזור הנתונים מאשר הסטייה הליניארית הממוצעת.
$X$. ראשית, נזכיר את ההגדרה הבאה:
הגדרה 1
אוּכְלוֹסִיָה- קבוצה של אובייקטים שנבחרו באקראי מסוג נתון, שעליהם מתבצעות תצפיות על מנת לקבל ערכים ספציפיים של משתנה אקראי, המתבצעות בתנאים ללא שינוי בעת לימוד משתנה אקראי אחד מסוג נתון.
הגדרה 2
שונות כללית- הממוצע האריתמטי של הסטיות בריבוע של ערכי הגרסה של האוכלוסייה הכללית מערכם הממוצע.
תן לערכי הגרסה $x_1,\ x_2,\dots ,x_k$ להיות, בהתאמה, את התדרים $n_1,\ n_2,\dots ,n_k$. אז השונות הכללית מחושבת על ידי הנוסחה:
לשקול מקרה מיוחד. תן לכל הווריאציות $x_1,\ x_2,\dots ,x_k$ להיות ברורים. במקרה זה $n_1,\ n_2,\dots ,n_k=1$. אנו מבינים שבמקרה זה השונות הכללית מחושבת על ידי הנוסחה:
כמו כן, קשור למושג זה מושג סטיית התקן הכללית.
הגדרה 3
סטיית תקן כללית
\[(\sigma )_r=\sqrt(D_r)\]
שונה במדגם
הבה נקבל סט מדגם ביחס למשתנה אקראי $X$. ראשית, נזכיר את ההגדרה הבאה:
הגדרה 4
אוכלוסיה לדוגמא-- חלק מהאובייקטים שנבחרו מהאוכלוסייה הכללית.
הגדרה 5
שונה במדגם- הממוצע האריתמטי של ערכי הגרסה של אוכלוסיית המדגם.
תן לערכי הגרסה $x_1,\ x_2,\dots ,x_k$ להיות, בהתאמה, את התדרים $n_1,\ n_2,\dots ,n_k$. לאחר מכן, שונות המדגם מחושבת על ידי הנוסחה:
בואו נבחן מקרה מיוחד. תן לכל הווריאציות $x_1,\ x_2,\dots ,x_k$ להיות ברורים. במקרה זה $n_1,\ n_2,\dots ,n_k=1$. אנו מבינים שבמקרה זה, השונות המדגם מחושבת על ידי הנוסחה:
למושג זה קשור גם הרעיון של סטיית תקן מדגם.
הגדרה 6
סטיית תקן לדוגמה-- שורש ריבועי של השונות הכללית:
\[(\sigma )_v=\sqrt(D_v)\]
שונות מתוקנת
כדי למצוא את השונות המתוקנת $S^2$, יש צורך להכפיל את השונות המדגם בשבר $\frac(n)(n-1)$, כלומר.
מושג זה קשור גם למושג סטיית התקן המתוקנת, שנמצא על ידי הנוסחה:
במקרה שבו הערך של הווריאציה אינו בדיד, אלא הם מרווחים, אז בנוסחאות לחישוב השונות הכלליות או הדגימות, הערך של $x_i$ נחשב לערך של אמצע המרווח אליו $ x_i.$ שייך
דוגמה לבעיה במציאת השונות וסטיית התקן
דוגמה 1
אוכלוסיית המדגם ניתנת על ידי טבלת ההתפלגות הבאה:
תמונה 1.
מצא עבורו את שונות המדגם, סטיית התקן המדגם, את השונות המתוקנת ואת סטיית התקן המתוקנת.
כדי לפתור בעיה זו, ראשית נכין טבלת חישוב:
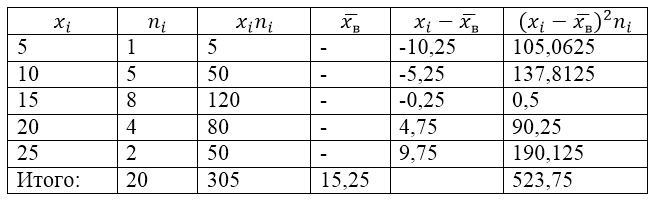
איור 2.
הערך של $\overline(x_v)$ (ממוצע לדוגמה) בטבלה נמצא על ידי הנוסחה:
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15.25\]
מצא את השונות לדוגמה באמצעות הנוסחה:
סטיית תקן לדוגמה:
\[(\sigma )_v=\sqrt(D_v)\approx 5,12\]
שונות מתוקנת:
\[(S^2=\frac(n)(n-1)D)_v=\frac(20)(19)\cdot 26.1875\approx 27.57\]
סטיית תקן מתוקנת.
סטיית תקן(מילים נרדפות: סטיית תקן, סטיית תקן, סטיית תקן; מונחים קשורים: סטיית תקן, פריסה סטנדרטית) - בתורת ההסתברות ובסטטיסטיקה, האינדיקטור הנפוץ ביותר לפיזור הערכים של משתנה אקראי ביחס לתוחלת המתמטית שלו. עם מערכים מוגבלים של דגימות ערכים, במקום הציפייה המתמטית, נעשה שימוש בממוצע האריתמטי של קבוצת הדגימות.
יוטיוב אנציקלופדית
-
1 / 5
סטיית התקן נמדדת ביחידות מדידה של המשתנה המקרי עצמו ומשמשת בחישוב טעות התקן של הממוצע האריתמטי, בבניית רווחי סמך, באימות סטטיסטי של השערות, במדידת הקשר הליניארי בין משתנים אקראיים. הוא מוגדר כשורש הריבועי של השונות של משתנה אקראי.
סטיית תקן:
s = n n − 1 σ 2 = 1 n − 1 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s=(\sqrt ((\frac (n)(n-1))\sigma ^(2)))=(\sqrt ((\frac (1)(n-1))\sum _( i=1)^(n)\left(x_(i)-(\bar (x))\right)^(2)));)- הערה: לעתים קרובות מאוד יש פערים בשמות של RMS (סטיית תקן) ו-SRT (סטיית תקן) עם הנוסחאות שלהם. לדוגמה, במודול numPy של שפת התכנות Python, הפונקציה std() מתוארת כ"סטיית תקן", בעוד שהנוסחה משקפת את סטיית התקן (חלק בשורש המדגם). באקסל, הפונקציה STDEV() שונה (מחלקים בשורש הריבועי של n-1).
סטיית תקן(הערכה של סטיית התקן של משתנה אקראי איקסביחס לתוחלת המתמטית שלו בהתבסס על אומדן חסר פניות של השונות שלו) s (\displaystyle s):
σ = 1 n ∑ i = 1 n (x i − x ¯) 2 . (\displaystyle \sigma =(\sqrt ((\frac (1)(n))\sum _(i=1)^(n)\left(x_(i)-(\bar (x))\right) ^(2))).)איפה σ 2 (\displaystyle \sigma ^(2))- פיזור; x i (\displaystyle x_(i)) - אני-האלמנט לדוגמה; n (\displaystyle n)- גודל המדגם; - ממוצע אריתמטי של המדגם:
x ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + … + x n) . (\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\ldots +x_(n)).)יש לציין ששתי ההערכות מוטות. במקרה הכללי, אי אפשר לבנות אומדן חסר פניות. עם זאת, אומדן המבוסס על אומדן שונות בלתי מוטה עקבי.
בהתאם ל- GOST R 8.736-2011, סטיית התקן מחושבת על פי הנוסחה השנייה של סעיף זה. אנא בדוק את התוצאות שלך.
כלל שלוש סיגמא
כלל שלוש סיגמא (3 σ (\displaystyle 3\sigma )) - כמעט כל הערכים של משתנה אקראי מחולק נורמלית נמצאים במרווח (x ¯ − 3 σ ; x ¯ + 3 σ) (\displaystyle \left((\bar (x))-3\sigma ;(\bar (x))+3\sigma \right)). ליתר דיוק - בערך עם הסתברות של 0.9973, הערך של משתנה אקראי שחולק נורמלית נמצא במרווח שצוין (בתנאי שהערך x ¯ (\displaystyle (\bar (x)))נכון, ולא התקבל כתוצאה מעיבוד המדגם).
אם הערך האמיתי x ¯ (\displaystyle (\bar (x)))לא ידוע, אז אתה צריך להשתמש σ (\displaystyle \sigma), א ס. לפיכך, הכלל של שלוש סיגמא הופך לכלל של שלוש ס .
פירוש הערך של סטיית התקן
ערך גדול יותר של סטיית התקן מצביע על פיזור גדול יותר של ערכים בקבוצה המוצגת עם ממוצע הסט; ערך קטן יותר, בהתאמה, מציין שהערכים בסט מקובצים סביב הערך הממוצע.
לדוגמה, יש לנו שלוש קבוצות מספרים: (0, 0, 14, 14), (0, 6, 8, 14) ו- (6, 6, 8, 8). לכל שלושת הקבוצות יש ערכים ממוצעים של 7 וסטיות תקן של 7, 5 ו- 1, בהתאמה. לקבוצה האחרונה יש סטיית תקן קטנה מכיוון שהערכים בקבוצה מקובצים סביב הממוצע; לסט הראשון יש הכי הרבה חשיבות רבהסטיית תקן - הערכים בתוך הסט חורגים מאוד מהערך הממוצע.
במובן כללי, סטיית התקן יכולה להיחשב כמדד לאי ודאות. לדוגמה, בפיזיקה, סטיית התקן משמשת לקביעת השגיאה של סדרה של מדידות עוקבות בכמות כלשהי. ערך זה חשוב מאוד לקביעת הסבירות של התופעה הנחקרת בהשוואה לערך החזוי על ידי התיאוריה: אם הערך הממוצע של המדידות שונה מאוד מהערכים שחוזים על ידי התיאוריה (סטיית תקן גדולה), אזי יש לבדוק מחדש את הערכים שהושגו או את שיטת השגתם. מזוהה עם סיכון תיק.
אַקלִים
נניח שיש שתי ערים עם אותה טמפרטורה יומית מקסימלית ממוצעת, אבל אחת ממוקמת על החוף והשנייה במישור. ערי חוף ידועות בהרבה טמפרטורות מקסימליות יומיות שונות מאשר בערים בפנים הארץ. לפיכך, סטיית התקן של הטמפרטורות היומיות המקסימליות לעיר החוף תהיה פחותה מזו של העיר השנייה, למרות העובדה שיש להן אותו ערך ממוצע של ערך זה, מה שאומר בפועל שההסתברות לכך טמפרטורה מקסימליתהאוויר של כל יום ספציפי בשנה יהיה שונה יותר מהערך הממוצע, גבוה יותר עבור עיר שנמצאת בתוך היבשת.
ספּוֹרט
נניח שיש כמה קבוצות כדורגל שמדורגות לפי סט פרמטרים כלשהו, למשל, מספר השערים שהובקעו והספגו, הזדמנויות להבקיע וכו'. סביר להניח שלקבוצה הטובה בקבוצה הזו יהיו הערכים הטובים ביותרלאפשרויות נוספות. ככל שסטיית התקן של הצוות קטנה יותר עבור כל אחד מהפרמטרים המוצגים, כך התוצאה של הצוות צפויה יותר, צוותים כאלה מאוזנים. מצד שני, הצוות עם ערך רבקשה לחזות את סטיית התקן, אשר בתורה מוסברת על ידי חוסר איזון, למשל, הגנה חזקה, אבל התקפה חלשה.
השימוש בסטיית התקן של הפרמטרים של הקבוצה מאפשר לחזות את תוצאת המשחק בין שתי קבוצות במידה מסוימת, תוך הערכת החוזק צדדים חלשיםפקודות, ומכאן שיטות המאבק הנבחרות.
הוא מוגדר כמאפיין הכללה של גודל הווריאציה של תכונה במצטבר. זה שווה לשורש הריבוע של הריבוע הממוצע של הסטיות של הערכים האישיים של התכונה מהממוצע האריתמטי, כלומר. השורש של וניתן למצוא כך:
1. עבור השורה הראשית:
2. לסדרת וריאציות:

השינוי של נוסחת סטיית התקן מוביל אותה לצורה נוחה יותר לחישובים מעשיים:
מְמוּצָע סטיית תקן קובע עד כמה, בממוצע, אופציות ספציפיות חורגות מערכן הממוצע, וחוץ מזה, זהו מדד מוחלט לתנודת התכונה ומתבטא באותן יחידות כמו האופציות, ולכן הוא מתפרש היטב.
דוגמאות למציאת סטיית התקן: ,
עבור תכונות חלופיות, הנוסחה עבור סטיית התקן נראית כך:

כאשר p הוא שיעור היחידות באוכלוסייה שיש להן תכונה מסוימת;
ש - שיעור היחידות שאין להן תכונה זו.
המושג סטייה ליניארית ממוצעת
סטייה ליניארית ממוצעתמוגדר כממוצע האריתמטי ערכים מוחלטיםסטיות של אפשרויות בודדות מ.
1. עבור השורה הראשית:

2. לסדרת וריאציות:

כאשר הסכום של n הוא סכום התדרים של סדרת הווריאציות.
דוגמה למציאת הסטייה הליניארית הממוצעת:
היתרון של הסטייה המוחלטת הממוצעת כמדד לפיזור על פני טווח השונות ברור, שכן מדד זה מבוסס על התחשבות בכל סטיות אפשריות. אבל לאינדיקטור זה יש חסרונות משמעותיים. דחייה שרירותית של סימנים אלגבריים של סטיות יכולה להוביל לעובדה שהמאפיינים המתמטיים של אינדיקטור זה רחוקים מלהיות אלמנטריים. זה מסבך מאוד את השימוש בסטייה המוחלטת הממוצעת בפתרון בעיות הקשורות לחישובים הסתברותיים.
לכן, הסטייה הליניארית הממוצעת כמדד לשונות של תכונה משמשת רק לעתים רחוקות בפרקטיקה הסטטיסטית, כלומר כאשר סיכום האינדיקטורים מבלי לקחת בחשבון סימנים הגיוני כלכלי. בעזרתו, למשל, מנתחים את מחזור סחר החוץ, הרכב העובדים, קצב הייצור וכו'.
שורש ממוצע ריבועים
RMS הוחל, למשל, כדי לחשב את הגודל הממוצע של הצדדים של n מקטעים מרובעים, הקטרים הממוצעים של גזעים, צינורות וכו '. זה מחולק לשני סוגים.
הריבוע הממוצע של השורש הוא פשוט. אם, כאשר מחליפים את הערכים האישיים של תכונה ב ערך ממוצעיש צורך לשמור את סכום הריבועים של הערכים המקוריים קבוע, אז הממוצע יהיה הממוצע הריבועי.
זהו השורש הריבועי של המנה של סכום הריבועים של ערכי תכונה בודדים חלקי מספרם:
ממוצע הריבוע המשוקלל מחושב על ידי הנוסחה:

כאשר f הוא סימן למשקל.
מעוקב ממוצע
ממוצע מעוקב הוחל, למשל, בעת קביעת אורך הצלע הממוצע וקוביות. זה מתחלק לשני סוגים.
ממוצע מעוקב פשוט:

בעת חישוב הערכים הממוצעים והשונות בסדרת התפלגות המרווחים, הערכים האמיתיים של התכונה מוחלפים בערכים המרכזיים של המרווחים, השונים מהממוצע ערכים אריתמטייםכלול במרווח. זה מוביל לטעות שיטתית בחישוב השונות. V.F. שפרד קבע את זה טעות בחישוב השונות, שנגרם על ידי יישום הנתונים המקובצים, הוא 1/12 מהריבוע של ערך המרווח, הן כלפי מעלה והן כלפי מטה בגודל השונות.
תיקון שפרדיש להשתמש אם ההתפלגות קרובה לנורמה, מתייחס לתכונה בעלת אופי מתמשך של שונות, הבנויה על כמות משמעותית של נתונים ראשוניים (n> 500). אולם, בהתבסס על העובדה שבמספר מקרים שתי הטעויות, הפועלות בכיוונים שונים, מפצות זו את זו, לעיתים ניתן לסרב להכניס תיקונים.
ככל שהשונות וסטיית התקן קטנים יותר, כך האוכלוסייה תהיה הומוגנית יותר והממוצע יהיה טיפוסי יותר.
בתרגול של סטטיסטיקה, לעתים קרובות יש צורך להשוות וריאציות סימנים שונים. למשל, עניין רב להשוות שינויים בגיל העובדים ובכישוריהם, משך השירות וגודלם. שכר, עלות ורווח, משך שירות ופריון עבודה וכו'. עבור השוואות כאלה, אינדיקטורים של השונות המוחלטת של מאפיינים אינם מתאימים: אי אפשר להשוות את השונות של ניסיון העבודה, המתבטאת בשנים, עם השונות של השכר, המתבטאת ברובלים.כדי לבצע השוואות כאלה, כמו גם השוואות של התנודות של אותה תכונה במספר אוכלוסיות עם ממוצע אריתמטי שונה, אנו משתמשים אינדיקטור יחסיוריאציה - מקדם וריאציה.
ממוצעים מבניים
כדי לאפיין את המגמה המרכזית בהתפלגויות סטטיסטיות, לרוב רציונלי להשתמש, יחד עם הממוצע האריתמטי, בערך מסוים של התכונה X, אשר בשל מאפיינים מסוימים של מיקומה בסדרת ההתפלגות, יכולה לאפיין את רמתה.
זה חשוב במיוחד כאשר לערכים הקיצוניים של התכונה בסדרת ההפצה יש גבולות מטושטשים. בעקבות זאת הגדרה מדויקתהממוצע האריתמטי, ככלל, הוא בלתי אפשרי או קשה מאוד. במקרים כאלו רמה ממוצעתניתן לקבוע על ידי לקיחת, למשל, ערך של תכונה שנמצאת באמצע סדרת התדרים או שמתרחשת לרוב בסדרה הנוכחית.
ערכים כאלה תלויים רק באופי התדרים, כלומר במבנה ההתפלגות. הם אופייניים מבחינת המיקום בסדרת התדרים, ולכן ערכים כאלה נחשבים כמאפיינים של מרכז ההפצה ולכן הוגדרו כממוצעים מבניים. הם רגילים ללמוד מבנה פנימיומבנה של סדרות התפלגות של ערכי תכונות. אינדיקטורים אלה כוללים .
המאפיין המושלם ביותר של וריאציה הוא סטיית התקן, הנקראת תקן (או סטיית תקן). סטיית תקן() שווה לשורש הריבוע הממוצע של הסטיות של ערכי תכונה בודדים מהממוצע האריתמטי:
סטיית התקן פשוטה:


סטיית התקן המשוקללת מיושמת עבור נתונים מקובצים:

בין הריבוע הממוצע לסטיות הלינאריות הממוצעות בתנאים של התפלגות נורמלית, מתקיים הקשר הבא: ~ 1.25.
סטיית התקן, בהיותה המדד המוחלט העיקרי לשונות, משמשת בקביעת ערכי הקורינטות של עקומת ההתפלגות הנורמלית, בחישובים הקשורים לארגון תצפית מדגם וביסוס הדיוק של מאפייני המדגם, וכן ב הערכת גבולות השונות של תכונה באוכלוסייה הומוגנית.
פיזור, סוגיו, סטיית תקן.
שונות של משתנה אקראי- מדד להתפשטות של משתנה מקרי נתון, כלומר, סטייתו מהציפייה המתמטית. בסטטיסטיקה, ייעוד או משמש לעתים קרובות. שורש ריבועישל השונות נקרא סטיית תקן, סטיית תקן או פריסת תקן.
שונות מוחלטת (σ2) מודד את השונות של תכונה בכל האוכלוסייה בהשפעת כל הגורמים שגרמו לשונות זו. יחד עם זאת, הודות לשיטת הקיבוץ, ניתן לבודד ולמדוד את השונות הנובעת מתכונת הקיבוץ, והשונות המתרחשת בהשפעת גורמים לא מטופלים.
שונות בין קבוצות (σ 2 מ"ג) מאפיין שונות שיטתית, כלומר הבדלים בגודל התכונה הנחקרת הנובעים בהשפעת התכונה - הגורם העומד בבסיס הקיבוץ.
סטיית תקן(מילים נרדפות: סטיית תקן, סטיית תקן, סטיית תקן; מונחים דומים: סטיית תקן, פריסת תקן) - בתורת ההסתברות ובסטטיסטיקה, המדד הנפוץ ביותר לפיזור ערכי משתנה מקרי ביחס לתוחלת המתמטית שלו. עם מערכים מוגבלים של דגימות ערכים, במקום הציפייה המתמטית, נעשה שימוש בממוצע האריתמטי של קבוצת הדגימות.
סטיית התקן נמדדת ביחידות של המשתנה המקרי עצמו ומשמשת בחישוב טעות התקן של הממוצע האריתמטי, בבניית רווחי סמך, בבדיקה סטטיסטית של השערות ובמדידת הקשר הליניארי בין משתנים אקראיים. הוא מוגדר כשורש הריבועי של השונות של משתנה אקראי.
סטיית תקן:

סטיית תקן(הערכה של סטיית התקן של משתנה אקראי איקסביחס לתוחלת המתמטית שלו בהתבסס על אומדן חסר פניות של השונות שלו):

איפה הפיזור; — אני-האלמנט לדוגמה; - גודל המדגם; - ממוצע אריתמטי של המדגם:

יש לציין ששתי ההערכות מוטות. במקרה הכללי, אי אפשר לבנות אומדן חסר פניות. עם זאת, אומדן המבוסס על אומדן שונות בלתי מוטה עקבי.
מהות, היקף ונוהל לקביעת המצב והחציון.
בנוסף לממוצעי חוקי הכוח בסטטיסטיקה, עבור מאפיין יחסי של גודלה של תכונה משתנה והמבנה הפנימי של סדרות התפלגות, משתמשים בממוצעים מבניים, המיוצגים בעיקר על ידי מצב וחציון.
אופנה- זוהי הגרסה הנפוצה ביותר של הסדרה. אופנה משמשת, למשל, בקביעת מידה של בגדים, נעליים, המבוקשים ביותר בקרב הקונים. המצב לסדרה בדידה הוא הגרסה בעלת התדר הגבוה ביותר. בעת חישוב המצב עבור סדרת וריאציות המרווחים, עליך לקבוע תחילה את המרווח המודאלי (על ידי תדירות מקסימלית), ולאחר מכן - הערך של הערך המודאלי של התכונה לפי הנוסחה:

- - ערך אופנתי
- - גבול תחתון של המרווח המודאלי
- - ערך מרווח
- - תדר מרווח מודאלי
- - תדירות המרווח שלפני המודאל
- - תדירות המרווח העוקב אחר המודאל
חציון -זהו הערך של התכונה שעומדת בבסיס הסדרה המדורגת ומחלקת את הסדרה הזו לשני חלקים שווים במספר.
כדי לקבוע את החציון בסדרה בדידה בנוכחות תדרים, חשב תחילה את חצי סכום התדרים ולאחר מכן קבע איזה ערך של הווריאציה נופל עליו. (אם השורה הממוינת מכילה מספר אי זוגי של תכונות, אז המספר החציוני מחושב על ידי הנוסחה:
M e \u003d (n (מספר התכונות במצטבר) + 1) / 2,
במקרה של מספר זוגי של תכונות, החציון יהיה שווה לממוצע של שתי התכונות באמצע השורה).
בעת חישוב חציוניםעבור סדרת וריאציות מרווחים, תחילה קבע את המרווח החציוני שבתוכו נמצא החציון, ולאחר מכן את הערך של החציון לפי הנוסחה:

- הוא החציון הרצוי
- הוא הגבול התחתון של המרווח המכיל את החציון
- - ערך מרווח
- - סכום התדרים או מספר איברי הסדרה
סכום התדרים המצטברים של המרווחים שלפני החציון
- היא התדירות של המרווח החציוני
דוגמא. מצא את המצב והחציון.
פִּתָרוֹן:
בדוגמה זו, המרווח המודאלי הוא בקבוצת הגיל של 25-30 שנים, שכן מרווח זה מהווה את התדירות הגבוהה ביותר (1054).בוא נחשב את ערך המצב:
המשמעות היא שהגיל המודאלי של התלמידים הוא 27 שנים.
חשב את החציון. המרווח החציוני הוא ב קבוצת גיל 25-30 שנים, שכן בתוך מרווח זה יש וריאנט המחלק את האוכלוסייה לשני חלקים שווים (Σf i /2 = 3462/2 = 1731). לאחר מכן, נחליף את הנתונים המספריים הדרושים לנוסחה ונקבל את הערך של החציון:

המשמעות היא שמחצית מהתלמידים מתחת לגיל 27.4, והמחצית השנייה מעל גיל 27.4.
בנוסף למצב ולחציון, ניתן להשתמש באינדיקטורים כגון רבעונים, המחלקים את הסדרה המדורגת ל-4 חלקים שווים, עשירונים- 10 חלקים ואחוזונים - לכל 100 חלקים.
מושג ההתבוננות הסלקטיבית והיקפו.
התבוננות סלקטיביתחל בעת יישום תצפית רציפה בלתי אפשרי פיזיתעקב כמות גדולה של נתונים או לא מעשי מבחינה כלכלית. חוסר אפשרות פיזית מתרחשת, למשל, כאשר לומדים את תזרימי הנוסעים, מחירי השוק, תקציבים משפחתיים. חוסר כדאיות כלכלית מתרחשת כאשר מעריכים את איכות הסחורות הקשורות להשמדתם, למשל, טעימות, בדיקת חוזק לבנים וכו'.
יחידות סטטיסטיות שנבחרו לתצפית מהוות מדגם או מדגם, ואת כל המערך שלהן - האוכלוסייה הכללית (GS). במקרה זה, מספר היחידות במדגם מציין נ, ובכל HS - נ. יַחַס n/nנקרא הגודל היחסי או הפרופורציה של המדגם.
איכות תוצאות הדגימה תלויה בייצוגיות המדגם, כלומר עד כמה הוא מייצג ב-HS. כדי להבטיח את הייצוגיות של המדגם, יש צורך להתבונן עקרון של בחירה אקראית של יחידות, אשר מניח שלא ניתן להשפיע על הכללת יחידת HS במדגם מכל גורם אחר מלבד מקרה.
קיים 4 דרכים לבחירה אקראיתלדגום:
- בעצם אקראיבחירה או "שיטת לוטו" כאשר נתונים סטטיסטיים מוקצים מספרי רצף, מובאים על חפצים מסוימים (לדוגמה, חביות), אשר לאחר מכן מערבבים במיכל מסוים (למשל, בשקית) ונבחרים באקראי. בפועל, שיטה זו מתבצעת באמצעות מחולל מספרים אקראיים או טבלאות מתמטיות של מספרים אקראיים.
- מֵכָנִיבחירה, לפיה כל ( לא/נ)-הערך של האוכלוסייה הכללית. לדוגמה, אם הוא מכיל 100,000 ערכים, וברצונך לבחור 1,000, אז כל ערך 100,000 / 1000 = 100 ייכנס למדגם. יתר על כן, אם הם לא מדורגים, אז הראשון נבחר באקראי מתוך המאה הראשונים, והמספרים של האחרים יהיו מאה יותר. לדוגמה, אם יחידה מספר 19 הייתה הראשונה, אז מספר 119 צריך להיות הבא, אז מספר 219, ואז מספר 319, וכן הלאה. אם יחידות האוכלוסייה מדורגות, תחילה נבחר #50, לאחר מכן #150, ואז #250, וכן הלאה.
- הבחירה של ערכים מתוך מערך נתונים הטרוגני מתבצעת מְרוּבָּדשיטה (שכבתית), כאשר האוכלוסייה הכללית מחולקת בעבר לקבוצות הומוגניות, שעליהן מיושמת בחירה אקראית או מכנית.
- שיטת דגימה מיוחדת היא סידוריבחירה, שבה לא נבחרות כמויות בודדות באופן אקראי או מכני, אלא סדרות שלהן (רצפים ממספר כלשהו לרצף כלשהו), שבתוכה מתבצעת התבוננות רציפה.
איכות תצפיות המדגם תלויה גם ב סוג דגימה: חוזר על עצמואוֹ לא חוזר על עצמו.
בְּ בחירה מחדשהערכים הסטטיסטיים או הסדרות שלהם שנפלו במדגם מוחזרים לאוכלוסייה הכללית לאחר השימוש, עם הזדמנות להיכנס למדגם חדש. יחד עם זאת, לכל הערכים של האוכלוסייה הכללית יש אותה הסתברות להיכלל במדגם.
בחירה לא חוזרתפירושו שהערכים הסטטיסטיים או הסדרות שלהם הכלולים במדגם אינם מוחזרים לאוכלוסייה הכללית לאחר השימוש, ולכן ההסתברות להיכנס למדגם הבא עולה עבור יתר הערכים של האחרון.
דגימה לא חוזרת נותנת תוצאות מדויקות יותר, ולכן משתמשים בה לעתים קרובות יותר. אבל יש מצבים שלא ניתן ליישם את זה (מחקר תזרימי נוסעים, ביקוש צרכנים וכו') ואז מתבצעת בחירה מחדש.
הטעות השולית של מדגם התצפית, הטעות הממוצעת של המדגם, סדר חישובם.
הבה נבחן בפירוט את השיטות לעיל ליצירת אוכלוסיית מדגם ואת הטעויות המתעוררות במקרה זה. ייצוגיות .
בעצם-אקראיהמדגם מבוסס על בחירה של יחידות מהאוכלוסייה הכללית באופן אקראי ללא כל מרכיבי עקביות. מבחינה טכנית, בחירה אקראית נכונה מתבצעת על ידי הגרלה (לדוגמה, הגרלות) או על ידי טבלה של מספרים אקראיים.בחירה אקראית למעשה "בצורתה הטהורה" בפרקטיקה של התבוננות סלקטיבית משמשת לעתים רחוקות, אבל היא הבחירה הראשונית מבין סוגי הבחירה האחרים, היא מיישמת את העקרונות הבסיסיים של התבוננות סלקטיבית. הבה נבחן כמה שאלות של התיאוריה של שיטת הדגימה ונוסחת השגיאה עבור מדגם אקראי פשוט.
שגיאת דגימה- זהו ההפרש בין ערך הפרמטר באוכלוסייה הכללית, לבין ערכו המחושב מתוצאות תצפית מדגמית. עבור מאפיין כמותי ממוצע, טעות הדגימה נקבעת על ידי
האינדיקטור נקרא שגיאת הדגימה השולית.
ממוצע המדגם הוא משתנה אקראי שיכול לקחת משמעויות שונותתלוי אילו יחידות נכללו במדגם. לכן, שגיאות דגימה הן גם משתנים אקראיים ויכולות לקבל ערכים שונים. לכן, הממוצע נקבע שגיאות אפשריות - שגיאת דגימה מתכוונת, שתלוי ב:גודל מדגם: מאשר יותר כוח, ככל שהערך של השגיאה הממוצעת קטן יותר;
מידת השינוי של התכונה הנחקרת: ככל ששונות התכונה קטנה יותר, וכתוצאה מכך השונות, כך קטנה טעות הדגימה הממוצעת.
בְּ בחירה מחדש אקראיתהשגיאה הממוצעת מחושבת:
.
בפועל, השונות הכללית לא בדיוק ידועה, אבל ב תאוריית ההסתברותהוכיח את זה .
.
מכיוון שהערך עבור n גדול מספיק קרוב ל-1, אנו יכולים להניח ש. אז ניתן לחשב את שגיאת הדגימה הממוצעת:
.
אבל במקרים של מדגם קטן (עבור n<30) коэффициент необходимо учитывать, и среднюю ошибку малой выборки рассчитывать по формуле .
.בְּ דגימה אקראיתהנוסחאות הנתונות מתוקנות על ידי הערך . אז השגיאה הממוצעת של אי דגימה היא:
 ו
ו  .
.
כי הוא תמיד קטן מ-, אז הגורם () תמיד קטן מ-1. המשמעות היא שהשגיאה הממוצעת בבחירה שאינה חוזרת היא תמיד קטנה מאשר בבחירה חוזרת.
דגימה מכניתמשמש כאשר האוכלוסייה הכללית מסודרת בדרך כלשהי (לדוגמה, רשימות בוחרים לפי סדר אלפביתי, מספרי טלפון, מספרי בתים, דירות). בחירת היחידות מתבצעת במרווח מסוים, השווה להדדיות של אחוז המדגם. אז, עם מדגם של 2%, כל 50 יחידה = 1 / 0.02 נבחרה, עם 5%, כל 1 / 0.05 = 20 יחידה מהאוכלוסייה הכללית.המוצא נבחר בדרכים שונות: באופן אקראי, מאמצע המרווח, עם שינוי במקור. העיקר הוא להימנע משגיאות שיטתיות. לדוגמה, עם מדגם של 5%, אם ה-13 נבחר כיחידה הראשונה, אז ה-33, 53, 73, וכו' הבאים.
מבחינת דיוק, בחירה מכנית קרובה לדגימה אקראית נכונה. לכן, כדי לקבוע את השגיאה הממוצעת של דגימה מכנית, נעשה שימוש בנוסחאות של בחירה אקראית נכונה.
בְּ מבחר טיפוסי האוכלוסייה הנסקרת מחולקת באופן ראשוני לקבוצות הומוגניות, חד-סוגיות. למשל, כאשר בודקים מפעלים, אלו יכולים להיות תעשיות, תת-מגזרים, תוך לימוד האוכלוסייה – אזורים, קבוצות חברתיות או גיל. לאחר מכן מתבצעת בחירה עצמאית מכל קבוצה באופן מכני או אקראי ראוי.
דגימה אופיינית נותנת תוצאות מדויקות יותר משיטות אחרות. טיפוסיית האוכלוסייה הכללית מבטיחה ייצוג של כל קבוצה טיפולוגית במדגם, מה שמאפשר לשלול את השפעת השונות הבין-קבוצתית על טעות המדגם הממוצעת. לכן, כאשר מוצאים את הטעות של מדגם טיפוסי על פי כלל הוספת השונות (), יש צורך לקחת בחשבון רק את הממוצע של השונות הקבוצתיות. ואז שגיאת הדגימה הממוצעת היא:
בבחירה מחדש
,
עם בחירה בלתי חוזרת ,
,
איפה הוא הממוצע של השונות התוך-קבוצתית במדגם.
הוא הממוצע של השונות התוך-קבוצתית במדגם.בחירה סדרתית (או מקוננת). משמש כאשר האוכלוסייה מחולקת לסדרות או לקבוצות לפני תחילת הסקר המדגם. סדרות אלו יכולות להיות חבילות של מוצרים מוגמרים, קבוצות סטודנטים, צוותים. סדרות לבדיקה נבחרות באופן מכני או אקראי, ובתוך הסדרה מתבצע סקר יחידות מלא. לכן, טעות הדגימה הממוצעת תלויה רק בשונות הבין-קבוצתית (בין-סדרתית), אשר מחושבת על ידי הנוסחה:

כאשר r הוא מספר הסדרות שנבחרו;
- הממוצע של הסדרה ה-i.שגיאת הדגימה הטורית הממוצעת מחושבת:
כאשר נבחר מחדש:
,
עם בחירה חד פעמית: ,
,
כאשר R הוא המספר הכולל של סדרות.מְשׁוּלָבבְּחִירָההוא שילוב של שיטות הבחירה הנחשבות.
טעות הדגימה הממוצעת לכל שיטת בחירה תלויה בעיקר בגודל המוחלט של המדגם ובמידה פחותה באחוז המדגם. נניח שבמקרה הראשון מתבצעות 225 תצפיות מתוך אוכלוסייה של 4,500 יחידות ובמקרה השני, מתוך 225,000 יחידות. השונות בשני המקרים שוות ל-25. לאחר מכן, במקרה הראשון, עם בחירה של 5%, טעות הדגימה תהיה:

במקרה השני, עם בחירה של 0.1%, זה יהיה שווה ל:
לכן, עם ירידה באחוז המדגם פי 50, טעות המדגם עלתה מעט, מאחר שגודל המדגם לא השתנה.
נניח שגודל המדגם גדל ל-625 תצפיות. במקרה זה, שגיאת הדגימה היא:
גידול במדגם פי 2.8 עם אותו גודל של האוכלוסייה הכללית מקטין את גודל טעות הדגימה ביותר מפי 1.6.שיטות ואמצעים לגיבוש אוכלוסיית מדגם.
בסטטיסטיקה, נעשה שימוש בשיטות שונות ליצירת ערכות מדגם, אשר נקבעות על פי מטרות המחקר ותלויות בפרטיו של מושא המחקר.
התנאי העיקרי לעריכת סקר מדגם הוא מניעת התרחשותן של טעויות שיטתיות הנובעות מהפרה של עקרון שוויון ההזדמנויות לכל יחידה באוכלוסייה הכללית להיכנס למדגם. מניעת טעויות שיטתיות מושגת כתוצאה משימוש בשיטות מבוססות מדעיות להיווצרות אוכלוסיית מדגם.
ישנן הדרכים הבאות לבחירת יחידות מהאוכלוסייה הכללית:
1) בחירה אישית - יחידות בודדות נבחרות במדגם;
2) בחירת קבוצות - קבוצות או סדרות של יחידות הנחקרות הומוגניות מבחינה איכותית נכנסות למדגם;
3) בחירה משולבת היא שילוב של בחירה אישית וקבוצתית.
שיטות הבחירה נקבעות על פי הכללים להיווצרות אוכלוסיית הדגימה.המדגם יכול להיות:
- אקראי ראוימורכב מכך שהמדגם נוצר כתוצאה מבחירה אקראית (לא מכוונת) של יחידות בודדות מהאוכלוסייה הכללית. במקרה זה, מספר היחידות שנבחרו במערך המדגם נקבע בדרך כלל על סמך השיעור המקובל של המדגם. נתח המדגם הוא היחס בין מספר היחידות באוכלוסיית המדגם n למספר היחידות באוכלוסיה הכללית N, כלומר.
- מֵכָנִימורכב מכך שבחירת היחידות במדגם נעשית מתוך האוכלוסייה הכללית, המחולקת למרווחים שווים (קבוצות). במקרה זה, גודל המרווח באוכלוסיה הכללית שווה להדדיות של שיעור המדגם. לכן, עם מדגם של 2%, כל יחידה 50 נבחרה (1:0.02), עם מדגם של 5%, כל יחידה 20 (1:0.05) וכו'. לפיכך, בהתאם לשיעור הסלקציה המקובל, האוכלוסייה הכללית מחולקת, כביכול, מכנית לקבוצות שוות. רק יחידה אחת נבחרה מכל קבוצה במדגם.
- טיפוסי -שבו האוכלוסייה הכללית מחולקת לראשונה לקבוצות טיפוסיות הומוגניות. לאחר מכן, מכל קבוצה טיפוסית, מתבצעת בחירה פרטנית של יחידות לתוך המדגם על ידי מדגם אקראי או מכני מתאים. מאפיין חשוב של מדגם טיפוסי הוא שהוא נותן תוצאות מדויקות יותר בהשוואה לשיטות אחרות לבחירת יחידות במדגם;
- סידורי- שבהם מחולקת האוכלוסייה הכללית לקבוצות בגודל זהה - סדרות. סדרות נבחרות בערכת המדגם. במסגרת הסדרה מתבצעת תצפית רציפה על היחידות שנפלו לסדרה;
- מְשׁוּלָב- הדגימה יכולה להיות דו-שלבית. במקרה זה, האוכלוסייה הכללית מחולקת תחילה לקבוצות. לאחר מכן נבחרות הקבוצות, ובתוך האחרונות נבחרות יחידות בודדות.
בסטטיסטיקה, השיטות הבאות לבחירת יחידות במדגם נבדלות::
- שלב בודדמדגם - כל יחידה נבחרת נתונה מיד למחקר על בסיס נתון (למעשה דגימות אקראיות וסדרתיות);
- רב שלבידגימה - הבחירה מתבצעת מתוך האוכלוסייה הכללית של קבוצות בודדות, ונבחרות יחידות בודדות מתוך הקבוצות (מדגם טיפוסי בשיטה מכנית לבחירת יחידות באוכלוסיית המדגם).
בנוסף, ישנם:
- בחירה מחדש- לפי תוכנית הכדור המוחזר. במקרה זה, כל יחידה או סדרה שנפלה למדגם מוחזרת לאוכלוסייה הכללית ולכן יש לה סיכוי להיכלל שוב במדגם;
- בחירה שאינה חוזרת על עצמה- לפי תכנית הכדור שלא הוחזר. יש לו תוצאות מדויקות יותר עבור אותו גודל מדגם.
קביעת גודל המדגם הנדרש (באמצעות טבלת הסטודנט).
אחד העקרונות המדעיים בתורת הדגימה הוא להבטיח כי נבחר מספר מספיק של יחידות. תיאורטית, הצורך בעמידה בעקרון זה מוצג בהוכחות של משפטי הגבול של תורת ההסתברות, המאפשרות לקבוע כמה יחידות יש לבחור מתוך האוכלוסייה הכללית כדי שזה יספיק ויבטיח את ייצוגיות המדגם.
ירידה בטעות התקן של המדגם, וכתוצאה מכך, עלייה בדיוק האומדן קשורה תמיד לגידול בגודל המדגם, ולכן, כבר בשלב ארגון תצפית מדגם, יש צורך להחליט מה צריך להיות גודל המדגם על מנת להבטיח את הדיוק הנדרש של תוצאות התצפית. חישוב גודל המדגם הנדרש נבנה באמצעות נוסחאות הנגזרות מהנוסחאות של טעויות הדגימה השוליות (A), המתאימות לסוג ושיטת בחירה כזו או אחרת. אז, עבור גודל מדגם חוזר אקראי (n), יש לנו:

המהות של נוסחה זו היא שעם בחירה מחדש אקראית של המספר הנדרש, גודל המדגם עומד ביחס ישר לריבוע של מקדם הביטחון (t2)ושונות של תכונת הווריאציה (?2) והיא ביחס הפוך לריבוע של טעות הדגימה השולית (?2). בפרט, על ידי הכפלת השגיאה השולית, ניתן להקטין את גודל המדגם הנדרש בפקטור של ארבע. מבין שלושת הפרמטרים, שניים (t ו?) נקבעים על ידי החוקר.
במקביל, החוקרלצורך הסקר המדגמי יש להכריע בשאלה: באיזה שילוב כמותי עדיף לכלול פרמטרים אלו על מנת לספק את הווריאציה האופטימלית? במקרה אחד, הוא עשוי להיות מרוצה יותר מאמינות התוצאות המתקבלות (t) מאשר ממדד הדיוק (?), במקרה השני - להיפך. קשה יותר לפתור את הסוגיה לגבי ערכה של טעות הדגימה השולית, כיוון שלחוקר אין מדד זה בשלב תכנון תצפית מדגם, לכן, בפועל, נהוג לקבוע את טעות הדגימה השולית, שכן כלל, בטווח של 10% מהרמה הממוצעת הצפויה של התכונה. ניתן לגשת לקביעת רמה ממוצעת משוערת בדרכים שונות: שימוש בנתונים מסקרים קודמים דומים, או שימוש בנתונים ממסגרת הדגימה ולקיחת מדגם פיילוט קטן.
הדבר הקשה ביותר לקבוע בעת תכנון תצפית מדגם הוא הפרמטר השלישי בנוסחה (5.2) - השונות של אוכלוסיית המדגם. במקרה זה, יש צורך להשתמש בכל המידע העומד לרשות החוקר, המתקבל מסקרים דומים ופיילוטים קודמים.
שאלה של הגדרהגודל המדגם הנדרש הופך מסובך יותר אם סקר המדגם כולל מחקר של מספר מאפיינים של יחידות דגימה. במקרה זה, הרמות הממוצעות של כל אחד מהמאפיינים והשונות שלהם, ככלל, שונות, ולכן ניתן להחליט לאיזה פיזור של איזה מהמאפיינים להעדיף רק בהתחשב במטרות ובמטרות של הסקר.
בעת תכנון תצפית מדגם, מניחים ערך קבוע מראש של טעות הדגימה המותרת בהתאם למטרות של מחקר מסוים ולהסתברות למסקנות המבוססות על תוצאות התצפית.
באופן כללי, הנוסחה עבור השגיאה השולית של ערך ממוצע המדגם מאפשרת לך לקבוע:
גודל הסטיות האפשריות של האינדיקטורים של האוכלוסייה הכללית ממדדי אוכלוסיית המדגם;
גודל המדגם הנדרש, המספק את הדיוק הנדרש, שבו גבולות השגיאה האפשרית לא יעלו על ערך מסוים שצוין;
ההסתברות שלשגיאה במדגם תהיה גבול נתון.
חלוקת הסטודנטיםבתורת ההסתברות, זוהי משפחה של פרמטר אחד של התפלגויות רציפות לחלוטין.
סדרת דינמיקה (מרווח, מומנט), סגירה של סדרת דינמיקה.
סדרה של דינמיקה- אלו הם הערכים של אינדיקטורים סטטיסטיים המוצגים ברצף כרונולוגי מסוים.
כל סדרת זמן מכילה שני מרכיבים:
1) אינדיקטורים של תקופות זמן (שנים, רבעונים, חודשים, ימים או תאריכים);
2) אינדיקטורים המאפיינים את האובייקט הנחקר לפרקי זמן או בתאריכים המתאימים, הנקראים רמות הסדרה.
הרמות של הסדרה באות לידי ביטויערכים מוחלטים וממוצעים או יחסיים כאחד. בהתאם לאופי האינדיקטורים, נבנות סדרות דינמיות של ערכים מוחלטים, יחסיים וממוצעים. סדרות דינמיות של ערכים יחסיים וממוצעים בנויים על בסיס סדרות נגזרות של ערכים מוחלטים. ישנן סדרות מרווחים ומומנטים של דינמיקה.
סדרת מרווחים דינמייםמכיל את ערכי האינדיקטורים לפרקי זמן מסוימים. בסדרת המרווחים ניתן לסכם את הרמות, לקבל את נפח התופעה לתקופה ארוכה יותר, או מה שנקרא סך הכל המצטבר.
סדרת רגעים דינמייםמשקף את ערכי האינדיקטורים בנקודת זמן מסוימת (תאריך זמן). בסדרות רגעים, החוקר עשוי להתעניין רק בהבדל התופעות, המשקף את השינוי ברמת הסדרה בין תאריכים מסוימים, שכן לסכום הרמות כאן אין תוכן ממשי. סכומים מצטברים אינם מחושבים כאן.
התנאי החשוב ביותר לבנייה נכונה של סדרות דינמיות הוא השוואת רמות הסדרות המתייחסות לתקופות שונות. רמות צריכות להיות מוצגות בכמויות הומוגניות, צריכה להיות אותה שלמות של כיסוי של חלקים שונים של התופעה.
כדיכדי למנוע עיוות של הדינמיקה האמיתית, מתבצעים חישובים ראשוניים במחקר הסטטיסטי (סגירת סדרת הזמן), הקודמים לניתוח הסטטיסטי של סדרת הזמן. סגירת סדרות זמן מובנת כשילוב של שתי סדרות או יותר לסדרה אחת, שרמותיה מחושבות לפי מתודולוגיה שונה או שאינן תואמות גבולות טריטוריאליים וכו'. סגירת סדרת הדינמיקה עשויה לרמוז גם על הפחתת הרמות האבסולוטיות של סדרת הדינמיקה לבסיס משותף, מה שמבטל את חוסר ההתאמה של הרמות של סדרת הדינמיקה.
מושג ההשוואה של סדרות זמן, מקדמים, צמיחה וקצבי צמיחה.
סדרה של דינמיקה- אלו הן סדרות של אינדיקטורים סטטיסטיים המאפיינים התפתחות של תופעות טבע וחברתיות בזמן. אוספים סטטיסטיים שפורסמו על ידי ועדת הסטטיסטיקה הממלכתית של רוסיה מכילים מספר רב של סדרות זמן בצורת טבלה. סדרה של דינמיקה מאפשרת גילוי דפוסי התפתחות של התופעות הנחקרות.
סדרות זמן מכילות שני סוגים של אינדיקטורים. מדדי זמן(שנים, רבעונים, חודשים וכו') או נקודות זמן (בתחילת השנה, בתחילת כל חודש וכו'). מחווני רמת השורות. אינדיקטורים של רמות סדרות הזמן יכולים להתבטא בערכים מוחלטים (ייצור של מוצר בטונות או רובל), ערכים יחסיים (נתח האוכלוסייה העירונית ב%) וערכים ממוצעים (שכר ממוצע של עובדי התעשייה) לפי שנים וכו'). בצורת טבלה, סדרת הזמן מכילה שתי עמודות או שתי שורות.
בנייה נכונה של סדרות זמן כרוכה במילוי מספר דרישות:
- כל האינדיקטורים לסדרה של דינמיקה חייבים להיות מבוססים מדעית, אמינים;
- אינדיקטורים של סדרה של דינמיקה צריכים להיות ניתנים להשוואה בזמן, כלומר. חייב להיות מחושב לאותן פרקי זמן או באותם תאריכים;
- אינדיקטורים של מספר דינמיקות צריכים להיות ניתנים להשוואה ברחבי הטריטוריה;
- אינדיקטורים של סדרה של דינמיקה צריכים להיות ברי השוואה בתוכן, כלומר. מחושב לפי מתודולוגיה אחת, באותו אופן;
- אינדיקטורים של סדרה של דינמיקה צריכים להיות ניתנים להשוואה על פני מגוון החוות הנחשבות. כל האינדיקטורים של סדרת דינמיקה צריכים להינתן באותן יחידות מדידה.
אינדיקטורים סטטיסטייםיכול לאפיין או את תוצאות התהליך הנחקר על פני תקופה מסוימת, או את מצב התופעה הנחקרת בנקודת זמן מסוימת, כלומר. אינדיקטורים יכולים להיות מרווחים (מחזוריים) ומידיים. בהתאם לכך, בתחילה סדרת הדינמיקה יכולה להיות מרווח או מומנט. סדרת הרגעים של דינמיקה, בתורה, יכולה להיות עם מרווחי זמן שווים ולא שווים.
ניתן להמיר את סדרת הדינמיקה הראשונית לסדרה של ערכים ממוצעים ולסדרה של ערכים יחסיים (שרשרת ובסיס). סדרות זמן כאלה נקראות סדרות זמן נגזרות.
שיטת חישוב הרמה הממוצעת בסדרת הדינמיקה שונה, בשל סוג סדרת הדינמיקה. בעזרת דוגמאות, שקול את סוגי סדרות הזמן והנוסחאות לחישוב הרמה הממוצעת.
רווחים מוחלטים (Δy) הראה כמה יחידות השתנתה הרמה שלאחר מכן של הסדרה בהשוואה לקודמתה (עמודה 3. - מרווחים מוחלטים של שרשרת) או בהשוואה לרמה ההתחלתית (עמודה 4. - מרווחים מוחלטים בסיסיים). ניתן לכתוב את נוסחאות החישוב באופן הבא:

עם ירידה בערכים המוחלטים של הסדרה, תהיה "ירידה", "ירידה", בהתאמה.
שיעורי הצמיחה האבסולוטיים מצביעים על כך, למשל, בשנת 1998 גדל ייצור המוצר "A" ב-4,000 טון לעומת 1997, וב-34,000 טון לעומת 1994; לשנים אחרות, ראה טבלה. 11.5 גר'. 3 ו-4.
גורם גדילהמראה כמה פעמים השתנתה רמת הסדרה בהשוואה לקודמתה (עמודה 5 - גורמי צמיחה או ירידה בשרשרת) או בהשוואה לרמה הראשונית (עמודה 6 - גורמי צמיחה או ירידה בסיסיים). ניתן לכתוב את נוסחאות החישוב באופן הבא:

שיעורי צמיחהלהראות כמה אחוזים הרמה הבאה בסדרה בהשוואה לקודמתה (עמודה 7 - קצבי גידול שרשרת) או בהשוואה לרמה הראשונית (עמודה 8 - קצבי צמיחה בסיסיים). ניתן לכתוב את נוסחאות החישוב באופן הבא:

כך, למשל, בשנת 1997, היקף הייצור של מוצר "A" בהשוואה לשנת 1996 היה 105.5% (
שיעור צמיחהלהראות כמה אחוזים עלתה רמת תקופת הדיווח בהשוואה לקודמתה (עמודה 9 - שיעורי צמיחה בשרשרת) או בהשוואה לרמה הראשונית (עמודה 10 - שיעורי צמיחה בסיסיים). ניתן לכתוב את נוסחאות החישוב באופן הבא:
T pr \u003d T p - 100% או T pr \u003d עלייה מוחלטת / רמה של התקופה הקודמת * 100%
כך, למשל, בשנת 1996, בהשוואה ל-1995, המוצר "A" יוצר יותר ב-3.8% (103.8% - 100%) או (8:210) x 100%, ובהשוואה ל-1994. - ב-9% ( 109% - 100%.
אם הרמות האבסולוטיות בסדרה יורדות, הרי שהשיעור יהיה נמוך מ-100% ובהתאם יחול שיעור ירידה (קצב צמיחה בסימן מינוס).
ערך מוחלט של עלייה של 1%.(עמודה 11) מראה כמה יחידות יש לייצר בתקופה נתונה כדי שרמת התקופה הקודמת תגדל ב-1%. בדוגמה שלנו, בשנת 1995 היה צורך לייצר 2.0 אלף טון, ובשנת 1998 - 2.3 אלף טון, כלומר. הרבה יותר גדול.
ישנן שתי דרכים לקבוע את גודל הערך המוחלט של צמיחה של 1%:
חלק את הרמה של התקופה הקודמת ב-100;
חלקו את שיעורי הצמיחה המוחלטים של השרשרת בשיעורי הצמיחה המתאימים של השרשרת.
ערך מוחלט של עלייה של 1% =

בדינמיקה, במיוחד לאורך תקופה ארוכה, חשוב לנתח במשותף את קצב הצמיחה עם התוכן של כל עלייה או ירידה באחוזים.
שימו לב שהמתודולוגיה הנחשבת לניתוח סדרות זמן ישימה הן עבור סדרות זמן, שרמותיהן מתבטאות בערכים מוחלטים (t, אלף רובל, מספר עובדים וכו'), והן עבור סדרות זמן, רמות של המתבטאים באינדיקטורים יחסיים (% מהגרוטאות,% תכולת אפר בפחם וכו') או בערכים ממוצעים (תשואה ממוצעת ב-c/ha, שכר ממוצע וכו').
לצד המדדים האנליטיים הנחשבים המחושבים לכל שנה בהשוואה לרמה הקודמת או הראשונית, בעת ניתוח סדרות הזמן, יש צורך לחשב את המדדים האנליטיים הממוצעים לתקופה: הרמה הממוצעת של הסדרה, העלייה השנתית המוחלטת הממוצעת. (ירידה) וקצב הצמיחה השנתי הממוצע וקצב הצמיחה.
שיטות לחישוב הרמה הממוצעת של סדרה של דינמיקה נדונו לעיל. בסדרת המרווחים של דינמיקה שאנו רואים, הרמה הממוצעת של הסדרה מחושבת על ידי הנוסחה של הממוצע האריתמטי הפשוט:
התפוקה השנתית הממוצעת של המוצר לשנים 1994-1998. הסתכם ב-218.4 אלף טון.
הגידול המוחלט השנתי הממוצע מחושב גם על ידי הנוסחה של הממוצע האריתמטי הפשוט:
התוספות המוחלטות השנתיות השתנו לאורך השנים בין 4 ל-12 אלף טון (ראה גר' 3), והגידול השנתי הממוצע בייצור לתקופה 1995 - 1998. הסתכם ב-8.5 אלף טון.
שיטות לחישוב קצב הגידול הממוצע וקצב הגידול הממוצע דורשות התייחסות מפורטת יותר. הבה נשקול אותם בדוגמה של האינדיקטורים השנתיים של רמת הסדרה המופיעים בטבלה.
הרמה האמצעית של טווח הדינמיקה.
סדרת דינמיקה (או סדרת זמן)- אלו הם הערכים המספריים של אינדיקטור סטטיסטי מסוים ברגעים או פרקי זמן עוקבים (כלומר מסודרים בסדר כרונולוגי).
הערכים המספריים של אינדיקטור סטטיסטי מסוים המרכיב סדרה של דינמיקה נקראים רמות של מספרוהוא מסומן בדרך כלל באות y. חבר ראשון בסדרה y 1נקרא ראשי או קו בסיס, והאחרון y n - סופי. הרגעים או פרקי הזמן שאליהם מתייחסות הרמות מסומנים ב ט.
סדרות דינמיות, ככלל, מוצגות בצורה של טבלה או גרף, וסולם זמן נבנה לאורך ציר ה-x ט, ולאורך הסמין - קנה המידה של רמות הסדרה y.
אינדיקטורים ממוצעים של סדרה של דינמיקה
כל סדרה של דינמיקה יכולה להיחשב כסט מסוים נאינדיקטורים משתנים בזמן שניתן לסכם אותם כממוצעים. אינדיקטורים כלליים (ממוצעים) כאלה נחוצים במיוחד כאשר משווים שינויים במדד זה או אחר בתקופות שונות, במדינות שונות וכו'.
מאפיין כללי של סדרה של דינמיקה יכול להיות, קודם כל, רמת שורה ממוצעת. שיטת חישוב הרמה הממוצעת תלויה בשאלה האם מדובר בסדרת רגעים או בסדרת מרווח (תקופה).
מתי הַפסָקָהסדרה, רמתה הממוצעת נקבעת על ידי הנוסחה של ממוצע אריתמטי פשוט של רמות הסדרה, כלומר.
=
אם זמין רֶגַעשורה המכילה נרמות ( y1, y2, …, yn) עם מרווחים שווים בין תאריכים (נקודות זמן), אז ניתן להמיר סדרה כזו בקלות לסדרה של ערכים ממוצעים. יחד עם זאת, המדד (הרמה) בתחילת כל תקופה הוא בו זמנית המדד בסוף התקופה הקודמת. לאחר מכן ניתן לחשב את הערך הממוצע של המחוון עבור כל תקופה (מרווח בין תאריכים) כחצי סכום של הערכים בְּ-בתחילת התקופה ובסופה, כלומר. איך. מספר הממוצעים הללו יהיה . כאמור, עבור סדרות של ממוצעים, הרמה הממוצעת מחושבת מהממוצע האריתמטי.לכן נוכל לכתוב:
 .
.
לאחר המרת המונה, נקבל: ,
,איפה Y1ו yn- הרמה הראשונה והאחרונה של הסדרה; יי- רמות ביניים.
ממוצע זה ידוע בסטטיסטיקה בשם כרונולוגי ממוצעלסדרת רגעים. את השם הזה היא קיבלה מהמילה "קרונוס" (זמן, lat.), שכן הוא מחושב ממדדים המשתנים עם הזמן.
במקרה של אי שוויוןמרווחים בין תאריכים, ניתן לחשב את הממוצע הכרונולוגי לסדרת הרגעים כממוצע האריתמטי של הערכים הממוצעים של הרמות עבור כל זוג רגעים, בשקלול המרחקים (מרווחי הזמן) בין התאריכים, כלומר.
 .
.
במקרה הזהההנחה היא שבמרווחים שבין תאריכים הרמות קיבלו ערכים שונים, ואנחנו משני ידועים ( יאו yi+1) אנו קובעים את הממוצעים, ומהם אנו מחשבים את הממוצע הכולל עבור כל התקופה המנותחת.
אם מניחים שכל ערך יאנשאר ללא שינוי עד הבא (i+ 1)- הרגע, כלומר התאריך המדויק של השינוי ברמות ידוע, אז ניתן לבצע את החישוב באמצעות נוסחת הממוצע האריתמטי המשוקלל:
,היכן הזמן שבו הרמה נותרה ללא שינוי.
בנוסף לרמה הממוצעת בסדרת הדינמיקה, מחושבים גם מדדי ממוצע נוספים - השינוי הממוצע ברמות הסדרה (שיטות בסיסיות ושרשרת), שיעור השינוי הממוצע.
קו בסיס פירושו שינוי מוחלטהוא המנה של השינוי המוחלט הבסיסי האחרון חלקי מספר השינויים. זה
שרשרת פירושה שינוי מוחלט רמות של סדרה היא המנה של חלוקת סכום כל השינויים האבסולוטיים של השרשרת במספר השינויים, כלומר.
לפי סימן השינויים האבסולוטיים הממוצעים, גם אופי השינוי בתופעה נשפט בממוצע: צמיחה, ירידה או יציבות.
מהכלל לשליטה בשינויים אבסולוטיים בסיסיים ושרשרת, עולה שהשינויים הבסיסיים והממוצעים של השרשרת חייבים להיות שווים.
לצד השינוי המוחלט הממוצע, היחס הממוצע מחושב גם בשיטות הבסיסיות והשרשרת.
שינוי יחסי ממוצע בסיסנקבע על ידי הנוסחה:
שרשרת משמעותה שינוי יחסינקבע על ידי הנוסחה:
מטבע הדברים, השינויים היחסיים הבסיסיים והממוצעים של השרשרת צריכים להיות זהים, ובהשוואתם לערך הקריטריון של 1, מגיעים למסקנה לגבי אופי השינוי בתופעה בממוצע: צמיחה, ירידה או יציבות.
על ידי הפחתת 1 מהשינוי היחסי הממוצע בבסיס או בשרשרת, המתאים קצב השינוי הממוצע, לפי הסימן שניתן לשפוט גם את אופי השינוי בתופעה הנחקרת, המשתקף מסדרת דינמיקה זו.תנודות עונתיות ומדדי עונתיות.
תנודות עונתיות הן תנודות תוך שנתיות יציבות.
העיקרון הבסיסי של ניהול להשיג את האפקט המקסימלי הוא מקסום ההכנסה ומזעור העלויות. על ידי לימוד תנודות עונתיות נפתרת בעיית המשוואה המקסימלית בכל רמה בשנה.
כאשר לומדים תנודות עונתיות, נפתרות שתי משימות הקשורות זו בזו:
1. זיהוי הפרטים של התפתחות התופעה בדינמיקה תוך שנתית;
2. מדידת תנודות עונתיות עם בניית מודל גלים עונתיים;
תרנגולי הודו עונתיים נספרים בדרך כלל כדי למדוד עונתיות. באופן כללי, הם נקבעים על פי היחס בין המשוואות המקוריות של סדרת דינמיקה למשוואות התיאורטיות המשמשות בסיס להשוואה.
היות וסטיות אקראיות מונחות על גבי תנודות עונתיות, מדדי עונתיות מוערכים בממוצע כדי לבטל אותן.
במקרה זה, עבור כל תקופה של המחזור השנתי, אינדיקטורים כלליים נקבעים בצורה של מדדים עונתיים ממוצעים:
המדדים הממוצעים של תנודות עונתיות נקיים מהשפעת סטיות אקראיות של מגמת ההתפתחות העיקרית.
בהתאם לאופי המגמה, הנוסחה למדד העונתיות הממוצעת יכולה ללבוש את הצורות הבאות:
1.לסדרות של דינמיקה תוך שנתית עם מגמת התפתחות עיקרית בולטת:
2. לסדרת הדינמיקה התוך שנתית שבה אין מגמת עלייה או ירידה, או שהיא לא משמעותית:
איפה הממוצע הכללי;
שיטות לניתוח המגמה המרכזית.
התפתחות התופעות לאורך זמן מושפעת מגורמים שונים באופיים ובעוצמת ההשפעה. חלקם אקראי באופיים, אחרים משפיעים כמעט תמידית ויוצרים מגמת התפתחות מסוימת בסדרת הדינמיקה.
משימה חשובה של סטטיסטיקה היא לזהות מגמה בסדרת הדינמיקה, המשוחררת מפעולה של גורמים אקראיים שונים. לצורך כך, סדרות הזמן מעובדות בשיטות של הגדלת מרווחים, ממוצע נע ויישור אנליטי וכו'.
שיטת גיבוש מרווחיםמבוסס על הגדלה של פרקי זמן, הכוללים את הרמות של סדרה של דינמיקה, כלומר. הוא החלפת נתונים הקשורים לפרקי זמן קטנים בנתונים מתקופות גדולות יותר. זה יעיל במיוחד כאשר הרמות הראשוניות של הסדרה הן לפרקי זמן קצרים. לדוגמה, סדרות של אינדיקטורים הקשורות לאירועים יומיים מוחלפות בסדרות הקשורות לשבוע, חודשי וכו'. זה יראה בצורה ברורה יותר "ציר התפתחות התופעה". הממוצע, המחושב על בסיס מרווחים מוגדלים, מאפשר לזהות את הכיוון והאופי (האצת צמיחה או האטה) של מגמת ההתפתחות העיקרית.
שיטת ממוצע נעדומה לקודמתה, אך במקרה זה, הרמות בפועל מוחלפות ברמות ממוצעות המחושבות עבור הזזה (החלקה) ברציפות של מרווחים מוגדלים המכסים Mרמות שורות.
לדוגמהאם יתקבל m=3,לאחר מכן, ראשית, מחושב הממוצע של שלוש הרמות הראשונות של הסדרה, לאחר מכן - מאותו מספר רמות, אך החל מהשנייה ברציפות, ואז - החל מהשלישית וכו'. כך, הממוצע, כביכול, "גולש" לאורך סדרת הדינמיקה, נע לתקופה אחת. מחושב מ Mאיברי הממוצעים הנעים מתייחסים לאמצע (המרכז) של כל מרווח.
שיטה זו מבטלת רק תנודות אקראיות. אם לסדרה יש גל עונתי, אז הוא יישאר לאחר החלקה בשיטת הממוצע הנע.
יישור אנליטי. על מנת לבטל תנודות אקראיות ולזהות מגמה, רמות הסדרה מיושרות לפי נוסחאות אנליטיות (או יישור אנליטי). עיקרו החלפת רמות אמפיריות (בפועל) ברמות תיאורטיות, המחושבות לפי משוואה מסוימת, הנלקחת כמודל מתמטי של המגמה, שבה רמות תיאורטיות נחשבות כפונקציה של זמן:. במקרה זה, כל רמה בפועל נחשבת כסכום של שני מרכיבים: , היכן הוא רכיב שיטתי ומבוטא במשוואה מסוימת, והוא משתנה אקראי הגורם לתנודות סביב המגמה.
המשימה של יישור אנליטי היא כדלקמן:
1. קביעת על בסיס נתונים בפועל את סוג הפונקציה ההיפותטית שיכולה לשקף בצורה המתאימה ביותר את מגמת ההתפתחות של המדד הנבדק.
2. מציאת הפרמטרים של הפונקציה (המשוואה) שצוינה מתוך נתונים אמפיריים
3. חישוב לפי המשוואה שנמצאה של רמות תיאורטיות (מפולסות).
הבחירה בפונקציה מסוימת מתבצעת, ככלל, על בסיס ייצוג גרפי של נתונים אמפיריים.
המודלים הם משוואות רגרסיה, שהפרמטרים שלהן מחושבים בשיטת הריבועים הקטנים ביותר
להלן משוואות הרגרסיה הנפוצות ביותר לפילוס סדרות זמן, המציינות אילו מגמות פיתוח הן מתאימות ביותר לשקף.
כדי למצוא את הפרמטרים של המשוואות לעיל, ישנם אלגוריתמים מיוחדים ותוכנות מחשב. בפרט, כדי למצוא את הפרמטרים של המשוואה של קו ישר, ניתן להשתמש באלגוריתם הבא:

אם פרקי הזמן או רגעי הזמן ממוספרים כך שמתקבל St = 0, אז האלגוריתמים שלעיל יפושטו באופן משמעותי ויהפכו ל

הרמות המיושרות בתרשים יהיו ממוקמות על קו ישר אחד העובר במרחק הקרוב ביותר מהרמות בפועל של סדרה דינמית זו. סכום הסטיות בריבוע הוא השתקפות של השפעתם של גורמים אקראיים.
בעזרתו, אנו מחשבים את השגיאה הממוצעת (הסטנדרטית) של המשוואה:

כאן n הוא מספר התצפיות, ו-m הוא מספר הפרמטרים במשוואה (יש לנו שניים מהם - b 1 ו- b 0).
המגמה העיקרית (מגמה) מראה כיצד גורמים שיטתיים משפיעים על רמות סדרה של דינמיקה, ותנודת הרמות סביב המגמה () משמשת כמדד להשפעה של גורמים שיוריים.
כדי להעריך את איכות מודל סדרת הזמן המשמש, הוא משמש גם מבחן F של פישר. זהו היחס של שתי שונות, כלומר היחס בין השונות הנגרמת על ידי הרגרסיה, כלומר. גורם נחקר, לפיזור הנגרם מסיבות אקראיות, כלומר. שונות שיורית:

בצורה מורחבת, הנוסחה עבור קריטריון זה יכולה להיות מיוצגת באופן הבא:

כאשר n הוא מספר התצפיות, כלומר. מספר רמות השורות,
m הוא מספר הפרמטרים במשוואה, y היא הרמה האמיתית של הסדרה,
רמה מיושרת של השורה, - הרמה הממוצעת של השורה.
מוצלח יותר מאחרים, ייתכן שהדגם לא תמיד מספק מספיק. ניתן לזהות אותו ככזה רק אם הקריטריון F עבורו חוצה גבול קריטי מסוים. גבול זה נקבע באמצעות טבלאות התפלגות F.
מהות וסיווג של מדדים.
אינדקס בסטטיסטיקה מובן כאינדיקטור יחסי המאפיין את השינוי בגודל התופעה בזמן, במרחב או בהשוואה לכל תקן.
המרכיב העיקרי של יחס האינדקס הוא הערך המופיע באינדקס. ערך צמוד מובן כערך של סימן של אוכלוסייה סטטיסטית, ששינויה הוא מושא המחקר.
אינדקסים משרתים שלוש מטרות עיקריות:
1) הערכת שינויים בתופעה מורכבת;
2) קביעת השפעת גורמים בודדים על שינוי תופעה מורכבת;
3) השוואה של גודל תופעה כלשהי עם גודל התקופה הקודמת, גודל טריטוריה אחרת, כמו גם עם תקנים, תוכניות, תחזיות.
המדדים מסווגים לפי 3 קריטריונים:
2) לפי מידת הכיסוי של מרכיבי האוכלוסייה;
3) לפי שיטות חישוב מדדים כלליים.
לפי תוכןשל ערכים צמודים, המדדים מחולקים למדדים של אינדיקטורים כמותיים (נפחיים) ומדדים של אינדיקטורים איכותיים. מדדי אינדיקטורים כמותיים - מדדי נפח פיזי של ייצור תעשייתי, נפח מכירות פיזי, מספר ועוד. מדדי אינדיקטורים איכותיים - מדדי מחירים, עלויות, פריון עבודה, שכר ממוצע וכו'.
לפי מידת הכיסוי של יחידות האוכלוסייה, המדדים מחולקים לשתי מחלקות: יחיד וכללי. כדי לאפיין אותם, אנו מציגים את המוסכמות הבאות שאומצו בפרקטיקה של יישום שיטת האינדקס:
ש- כמות (נפח) של כל מוצר בעין ; ר- מחיר הייצור ליחידה; ז- עלות ייצור ליחידה; ט- זמן המושקע בייצור של יחידת תפוקה (עוצמת עבודה) ; w- תפוקת ייצור במונחי ערך ליחידת זמן; v- תפוקה במונחים פיזיים ליחידת זמן; ט- סך הזמן שהושקע או מספר עובדים.
על מנת להבחין לאיזו תקופה או אובייקט שייכים הערכים המאונדקסים, נהוג לשים מנויים אחרי הסמל המתאים בפינה השמאלית התחתונה. כך, למשל, באינדקסים של דינמיקה, ככלל, עבור התקופות המושוואות (נוכחיות, דיווח), נעשה שימוש במתווה 1 ולתקופות איתן מתבצעת ההשוואה,
מדדים בודדיםמשמשים לאפיון השינוי באלמנטים בודדים של תופעה מורכבת (לדוגמה, שינוי בנפח התפוקה של סוג אחד של מוצר). הם מייצגים את הערכים היחסיים של דינמיקה, מילוי התחייבויות, השוואה של ערכים צמודים.
המדד האישי של נפח הייצור הפיזי נקבע
מנקודת מבט אנליטית, מדדי הדינמיקה הבודדים הנתונים דומים למקדמי (שיעורי) הצמיחה ומאפיינים את השינוי בערך הצמוד בתקופה הנוכחית לעומת הבסיס, כלומר מראים כמה פעמים הוא עלה (ירד ) או כמה אחוזים מדובר בצמיחה (ירידה). ערכי אינדקס מבוטאים במקדמים או באחוזים.
אינדקס כללי (מרוכב).משקף את השינוי בכל המרכיבים של תופעה מורכבת.
אינדקס מצטברהיא הצורה הבסיסית של המדד. זה נקרא מצטבר מכיוון שהמונה והמכנה שלו הם קבוצה של "מצבר"
מדדים ממוצעים, הגדרתם.
בנוסף למדדים מצרפים, צורה נוספת שלהם משמשת בסטטיסטיקה - מדדי ממוצע משוקלל. החישוב שלהם נעשה כאשר המידע הקיים אינו מאפשר חישוב המדד המצרפי הכללי. לכן, אם אין נתונים על מחירים, אבל יש מידע על עלות המוצרים בתקופה הנוכחית וידועים מדדי מחירים בודדים לכל מוצר, אזי לא ניתן לקבוע את מדד המחירים הכללי כמצרף, אבל אפשר כדי לחשב אותו כממוצע של בודדים. באותו אופן, אם הכמויות של מוצרים בודדים שיוצרו אינן ידועות, אך ידועות המדדים הבודדים ועלות הייצור של תקופת הבסיס, אזי ניתן לקבוע את המדד הכולל של נפח הייצור הפיזי כממוצע משוקלל.
מדד ממוצע -זֶהמדד המחושב כממוצע של המדדים הבודדים. המדד המצטבר הוא הצורה הבסיסית של המדד הכללי, ולכן המדד הממוצע חייב להיות זהה למדד המצרפי. בעת חישוב מדדי ממוצע, משתמשים בשתי צורות של ממוצעים: אריתמטי והרמוני.
המדד הממוצע האריתמטי זהה למדד המצרפי אם משקלי המדדים הבודדים הם מונחי המכנה של המדד המצרפי. רק במקרה זה ערך המדד המחושב על ידי נוסחת הממוצע האריתמטי יהיה שווה למדד המצרפי.

